
Overview
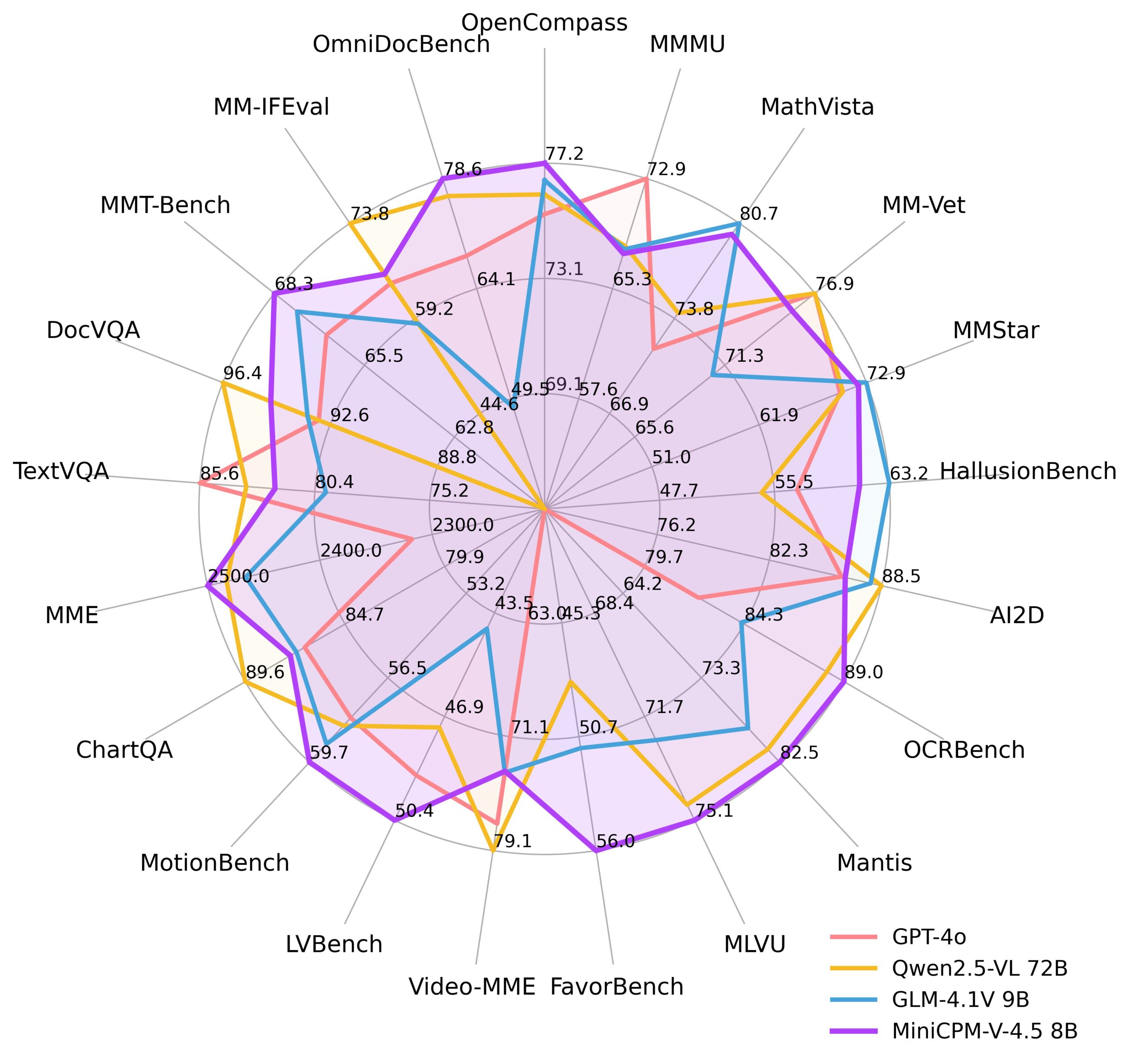
In the rapidly evolving landscape of AI, the demand for powerful yet accessible multimodal models continues to grow. MiniCPM-V 4.5 represents a significant advancement as an 8B parameter open-source Multimodal Large Language Model (MLLM) that achieves performance comparable to much larger proprietary models while running efficiently on mobile devices. This model excels at understanding images, videos, and documents, demonstrating particularly strong performance on OCR tasks and achieving leading results on critical benchmarks like OCRBench.
Key Features
MiniCPM-V 4.5 incorporates several advanced capabilities designed for high performance and mobile deployment:
- 8B Parameter Multimodal Architecture: Built on Qwen3-8B and SigLIP2-400M, the model handles various input types including text, images, video, and documents while maintaining computational efficiency.
- Advanced OCR and Document Processing: Demonstrates exceptional optical character recognition capabilities, achieving leading performance on OCRBench and surpassing proprietary models in document understanding tasks.
-
Mobile-Optimized Performance: Engineered for edge deployment with efficient inference on mobile devices, bringing advanced AI capabilities to resource-constrained environments.
-
Open-Source Accessibility: Released under Apache-2.0 license with model weights and inference stack freely available for academic research and commercial use after registration.
-
Competitive Benchmark Results: Achieves an average score of 77.0 on OpenCompass across 8 benchmarks, demonstrating performance competitive with much larger proprietary models.
Technical Capabilities
The model’s architecture enables several advanced features:
Dynamic Resolution Processing: Handles high-resolution images up to 1.8 million pixels (1344×1344) with any aspect ratio, using the LLaVA-UHD architecture for efficient processing with 4x fewer visual tokens than most comparable models.
Video Understanding: Features a unified 3D-Resampler that achieves 96x compression rate for video tokens, processing six 448×448 video frames into just 64 tokens. This enables high refresh rate video understanding up to 10FPS and long-form video analysis.
Multilingual Support: Processes text in over 30 languages, making it suitable for global deployment and diverse linguistic contexts.
Hybrid Processing Modes: Offers controllable fast and deep thinking modes to optimize for either efficiency or complex problem-solving depending on use case requirements.
Performance and Validation
Independent benchmarking demonstrates MiniCPM-V 4.5’s competitive performance:
- OpenCompass Score: 77.0 average across 8 comprehensive benchmarks
- OCRBench Results: Leading performance, surpassing GPT-4o-latest and Gemini 2.5
- Parameter Efficiency: Most performant MLLM under 30B parameters
- Mobile Performance: Optimized inference on edge devices with low latency
Use Cases and Applications
The model’s versatility enables deployment across multiple scenarios:
Enterprise Document Processing: Automated OCR, document analysis, and information extraction with high accuracy for business workflows.
Mobile AI Applications: Real-time image and video analysis on smartphones and tablets, enabling privacy-preserving on-device processing.
Research and Development: Lightweight foundation for multimodal AI research and prototyping without extensive computational requirements.
Edge Computing: Deployment in resource-constrained environments such as IoT devices, robotics, and autonomous systems where cloud connectivity is limited.
Technical Considerations
Advantages
- Computational Efficiency: 8B parameter design enables deployment on standard hardware
- Open Source: Transparent development and community accessibility
- Strong OCR Performance: Specialized capabilities in text recognition and document processing
- Local Processing: Enhanced privacy and reduced dependency on cloud services
Current Limitations
- Scale Trade-offs: May not match the most complex reasoning capabilities of frontier models with significantly more parameters
- Hardware Constraints: Mobile deployment still subject to device memory and processing limitations
- Specialized Domains: Performance may vary in highly specialized tasks compared to domain-specific models
- Continuous Development: Video understanding capabilities continue to evolve with ongoing improvements
Competitive Landscape
MiniCPM-V 4.5 operates in a competitive field of advanced multimodal models. Key comparisons include:
Frontier Models: NVLM 1.0 (72B) and InternVL 2.5 (up to 78B) represent the current state-of-the-art but require significantly more computational resources.
Comparable Scale Models: LLaVA-NeXT (7B-34B), Qwen2.5-VL (7B-72B), and Phi-3.5-Vision (4.2B) offer different trade-offs between performance and efficiency.
Specialized Performance: Points1.5-7B currently ranks first on OpenCompass among models under 10B parameters, while MiniCPM-V 4.5 distinguishes itself through superior OCR capabilities and mobile optimization.
The model’s primary differentiator lies in delivering strong multimodal performance with exceptional OCR capabilities while maintaining deployment feasibility on consumer hardware, making it particularly valuable for applications requiring local processing and document analysis.
Deployment and Availability
MiniCPM-V 4.5 supports multiple deployment options:
- Format Options: Available in int4, GGUF, and AWQ quantized formats across 16 different sizes
- Inference Frameworks: Compatible with llama.cpp, ollama, SGLang, and vLLM for various deployment scenarios
- Development Tools: Supports fine-tuning through Transformers and LLaMA-Factory
- Mobile Deployment: Optimized implementations for iOS and cross-platform mobile applications
Future Directions
As multimodal AI continues advancing, MiniCPM-V 4.5 represents an important step toward making sophisticated AI capabilities accessible on consumer devices. The model demonstrates that efficient architectures can achieve competitive performance while enabling new applications in privacy-sensitive and resource-constrained environments. Ongoing development focuses on expanding video understanding capabilities and improving performance across diverse multimodal tasks.