Overview
Running untrusted code at scale creates contradictory constraints: security requires isolation (VM-level containment, kernel separation), performance demands speed (instant startup, zero cold-start lag), and cost management necessitates efficiency (pay only for runtime, avoid always-on infrastructure). Traditional approaches force impossible choices—containers offer speed but share kernels vulnerable to escape; full VMs provide security but require seconds-to-minutes startup; serverless offers auto-scaling but imposes arbitrary timeout limits unsuitable for long-running processes.
Hopx resolves these tradeoffs through specialized infrastructure: Firecracker micro-VMs launching in ~100 milliseconds while providing hardware-level security through dedicated kernels, combined with stateful persistence enabling continuous operation without artificial runtime constraints. Rather than treating isolation and speed as opposing forces, Hopx uses prebuilt snapshots and optimized hypervisor architecture to achieve both simultaneously.
The platform targets developers and AI teams deploying autonomous agents requiring secure code execution, researchers running long-duration workloads, SaaS platforms isolating user code, and organizations building AI applications accessing untrusted LLM-generated code.
Key Features
Hopx delivers specialized sandbox infrastructure optimized for secure, high-performance, and stateful code execution at scale:
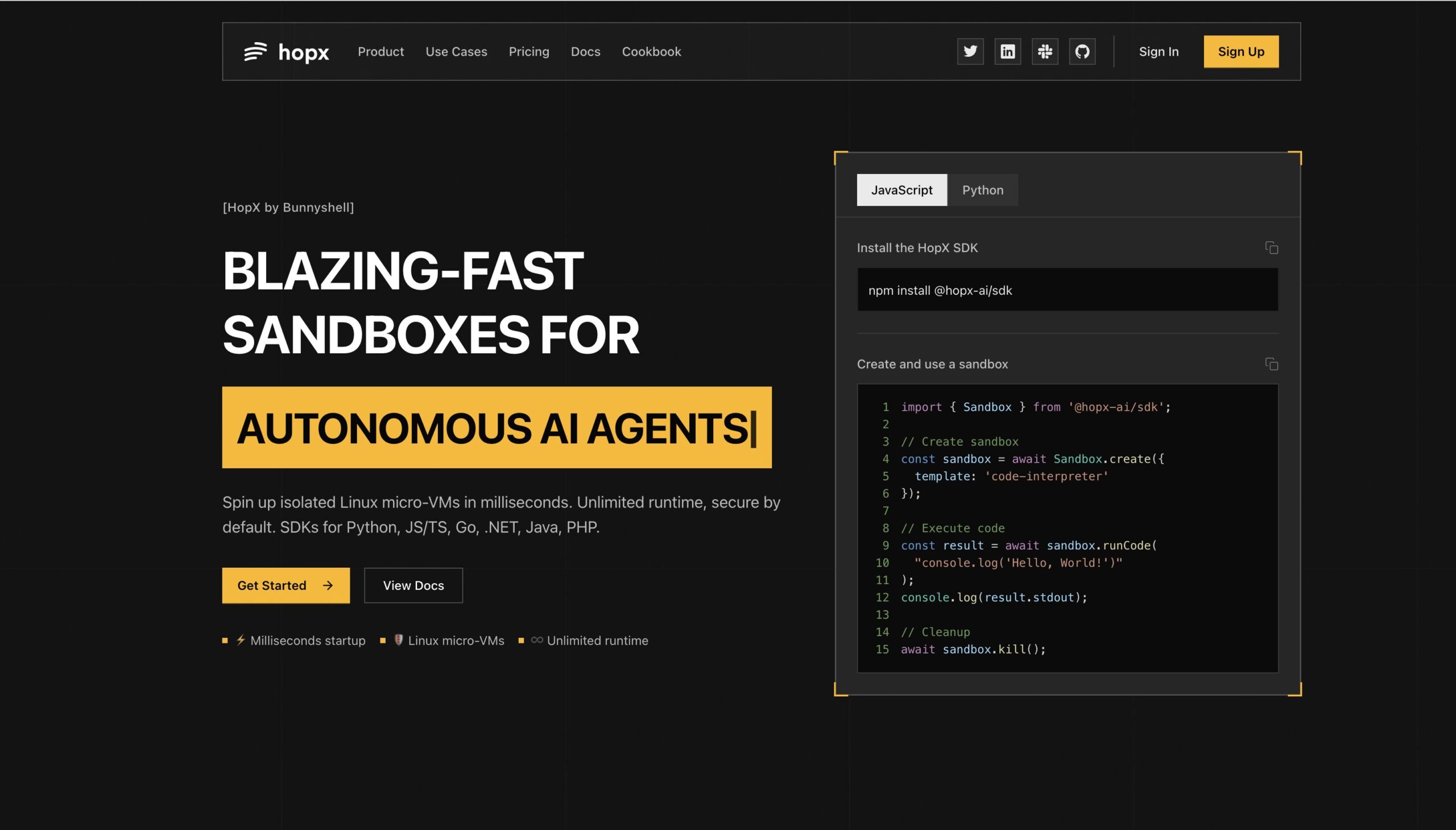
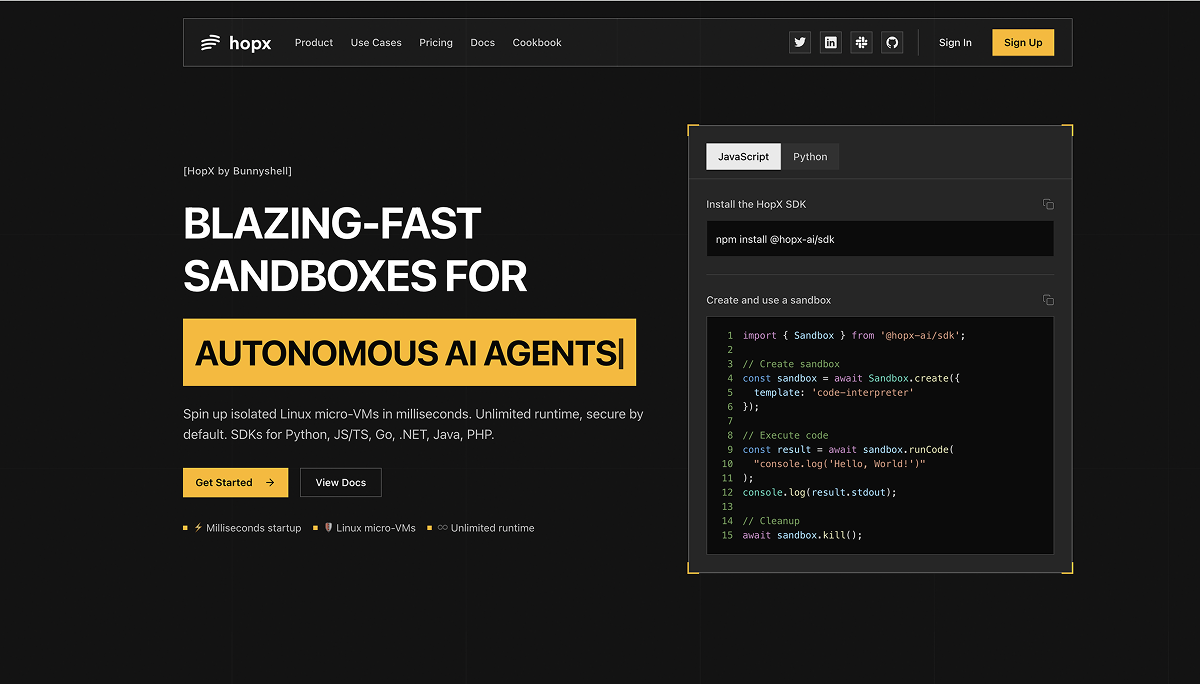
- Ultra-Fast Micro-VM Launch (~100ms): Prebuilt Linux snapshot technology enables near-instantaneous sandbox creation from cold state. Rather than building systems from scratch (consuming seconds-to-minutes), Hopx recovers pre-warmed system images, reducing initialization latency from orders of magnitude slower to imperceptible delays—enabling responsive real-time workloads impossible with traditional VM provisioning.
- Firecracker Hardware Isolation: Leverages AWS Firecracker technology providing kernel-level virtualization isolation. Each sandbox runs in dedicated Linux kernel within dedicated VM—fundamentally different security model from containers sharing host kernels where single vulnerability can compromise all tenants. This enables safe execution of genuinely untrusted code (adversarial LLM outputs, user-submitted scripts, experimental plugins) without risking host infrastructure.
- Comprehensive Language SDK Support: Integrate via SDKs for Python, JavaScript/TypeScript, Go, .NET, Java, and PHP. Clean APIs abstract Firecracker complexity enabling developers to launch sandboxes programmatically, execute code, stream output in real-time via WebSocket, manage file operations, run shell commands, control background processes, and monitor system metrics—all without direct microVM management.
- True Stateful Persistence: Unlike ephemeral serverless functions resetting between invocations, Hopx sandboxes maintain complete state across sessions—filesystem preserved, processes continue, environment configuration intact. This enables long-running autonomous agents, continuous data analysis tasks, and persistent development environments operating for hours, days, or weeks without interruption or re-initialization.
- Unlimited Runtime Duration: No arbitrary execution timeouts. Deploy agents running continuously, background jobs operating indefinitely, or ML training completing over extended periods—without platform-imposed limits forcing workarounds or periodic restarts common in serverless systems where 15-minute timeouts (AWS Lambda) require orchestration complexity to exceed limits.
- Real-Time Output Streaming: Capture code execution output through WebSocket streaming enabling live feedback. Watch agents think through problems in real-time, see inference results immediately, or monitor logs continuously—responding to execution as it happens rather than polling completed results.
- Desktop Environment Automation: Full GUI automation capabilities enable agents controlling cloud desktop environments. Agents screenshot screens, click UI elements, type into applications, copy/paste between programs—automating tasks requiring GUI interaction impossible in headless-only environments.
- Multi-Agent Mesh Orchestration: Deploy coordinated multi-agent systems where each agent runs in isolated sandbox with strict network policies, filesystem boundaries, and port-to-port messaging. Orchestrate through LangGraph, AutoGen, or custom controllers with fine-grained per-agent resource limits, CPU/memory caps, and role-based access controls.
- Flexible Deployment Templates: Pre-configured environments for common use cases (code-interpreter, Jupyter notebooks, desktop automation, reinforcement learning, MCP servers, background jobs) reduce setup complexity. Create custom templates for domain-specific workloads.
- Transparent Cost Model: Per-second billing for compute (vCPU \$0.000014/s), memory (\$0.0000045/s), and storage (\$0.00000003/s). Only pay during active execution—idle sandboxes don’t accrue charges. Stopped or deleted sandboxes incur zero cost, enabling rapid experimentation without wasted cloud spending typical of always-on infrastructure.
- Enterprise Observability: Monitor CPU, memory, network, and disk metrics in real-time. Stream logs via WebSocket for live debugging. Audit logs for compliance requirements. Fine-grained resource controls prevent runaway processes from consuming infrastructure accidentally.
How It Works
Hopx transforms untrusted code execution from security nightmare into routine operation through specialized infrastructure and programmatic simplicity.
Developer integration begins with SDK installation for their language (Python, JavaScript, Go, .NET, Java, PHP). Initialize Hopx client with API key; sandboxes provision immediately via API calls.
Creating isolated execution begins by specifying template—”code-interpreter” for general code execution, “jupyter” for notebook environments, “desktop” for GUI automation, or custom templates for domain-specific configurations. Hopx launches matching prebuilt Linux snapshot creating isolated microVM in ~100 milliseconds.
Within this sandbox, developers execute arbitrary code: Python scripts accessing system libraries, JavaScript using Node.js, shell commands, long-running background processes, or desktop automation sequences. Each execution captures output (stdout/stderr), return codes, generated files, and system metrics.
Real-time streaming pipes execution output through WebSocket enabling live visibility—agents thinking through steps appear in real-time; inference results surface immediately; logs stream continuously rather than waiting for completion.
Sandboxes maintain persistent state: files remain on disk between executions; background processes continue running; environment variables and configurations persist. This contrasts serverless where each invocation starts fresh, requiring complex state management and data transfer between function calls.
Network configuration provides sandboxes with outbound connectivity to external services (APIs, databases, web services) while preventing inbound access—securing agents from remote exploitation while enabling legitimate external communication.
Orchestrating multi-agent systems configures per-agent sandboxes with restricted network scopes (different agents can’t access each other’s networks), filesystem boundaries (agents can’t read other agents’ files), and port-to-port messaging enabling controlled inter-agent communication.
Developers specify per-sandbox resource limits: maximum CPU utilization preventing runaway computations, memory caps preventing OOM crashes, timeout policies for safety. Hopx enforces these limits stopping execution if thresholds are exceeded.
Cost transparency operates continuously: every millisecond of execution charges vCPU billing; each MB of used memory charges memory billing; stored data charges storage billing. Stopping sandbox immediately ceases charges. Developers can track real-time spending and optimize resource usage.
Use Cases
Hopx’s specialized sandbox infrastructure addresses scenarios requiring isolation, speed, and persistence simultaneously:
- Secure Execution of LLM-Generated Code: AI applications generate code from language models and execute it safely in isolated sandboxes. Agents write Python scripts, JavaScript automation, or shell commands; Hopx prevents malicious or buggy code from compromising host systems while enabling full Linux capabilities necessary for sophisticated workloads.
- Autonomous AI Agent Infrastructure: Deploy multi-agent systems where specialized agents (research agent, analysis agent, planning agent, execution agent) run in dedicated isolated sandboxes orchestrated through LangGraph or AutoGen. Per-agent isolation prevents one misbehaving agent from affecting others while enabling coordinated workflows.
- Extended-Duration Workloads: Researchers running reinforcement learning training for hours, data scientists executing multi-hour data processing pipelines, or background workers processing queues operate without artificial timeout constraints. Stateful persistence maintains progress across system resets.
- Jupyter Notebook Sandboxing: Data scientists access secure, persistent Jupyter environments with ML libraries preinstalled. Execute notebooks without impacting shared resources; persistent state enables multi-session analysis without state loss.
- SaaS Backend Isolation: Platforms executing user-uploaded code (data science notebooks, workflow automation tools, compute platforms) isolate each user’s workload preventing cross-tenant interference. Per-user sandboxes with strict network boundaries provide strong multi-tenant isolation.
- Desktop Automation Agents: Agents automating GUI-based workflows (web scraping via headless browser, visual testing, user interface automation, complex multi-step desktop interactions) run within cloud desktop environments controlled through GUI APIs.
- Reinforcement Learning Environments: RL training agents operate continuously in isolated environments with metrics and video streaming. Persistent state enables long-training-duration experiments; snapshot functionality enables branching and rollback for experimentation.
- MCP Server Hosting: Host specialized tool servers (Model Context Protocol servers providing organized tool access) in isolated sandboxes with per-server network and filesystem boundaries, safe port exposure, and rapid 100ms startup enabling dynamic server creation.
Advantages
- 50x Faster Than Alternatives: ~100ms startup vs Modal’s 2-4 second baseline and traditional VMs’ seconds-to-minutes latency. Enables real-time responsiveness for dynamic workloads impossible with slower platforms—agents respond instantly without perceptible delays.
- Superior Security vs Containers: Hardware-level kernel-based isolation prevents container escape vulnerabilities. Genuinely untrusted code (adversarial LLM outputs, malicious plugins, experimental scripts) runs safely—unique risk profile compared to container-based alternatives.
- True Statefulness Without Complexity: Persistent sandboxes eliminate per-invocation state reset complexity. Long-running agents, continuous processes, and multi-session workflows operate naturally without orchestration overhead to preserve state between function calls.
- Unlimited Runtime without Workarounds: No artificial timeout limits forcing orchestration complexity. Agents operate continuously, training runs complete naturally, background jobs execute indefinitely—simplifying system architecture.
- Transparent Per-Second Billing: Pay exclusively for execution time. Idle/stopped sandboxes incur zero cost. Rapid experimentation won’t generate unexpected cloud bills—cost visibility enables optimization.
- Broad Language Support: Python, JavaScript, Go, .NET, Java, PHP SDKs enable integration across technology stacks without vendor-specific language lock-in.
- Multi-Agent Native: Built-in orchestration for coordinated agents with strict isolation, resource controls, and per-agent limits—sophisticated architectures don’t require external orchestration.
- Developer-Friendly Abstractions: Clean SDKs abstract Firecracker complexity. Developers think in code execution terms, not virtualization infrastructure—enabling rapid development.
Considerations
- Developer-Centric Platform: Requires API/SDK integration and technical expertise. Non-technical teams cannot directly use Hopx without developer involvement—primarily infrastructure for builders rather than end-users.
- Cloud Infrastructure Knowledge Expected: Users should understand compute concepts (CPU, memory, processes, networking) to configure sandbox parameters effectively. Teams unfamiliar with Linux environments may require learning investment.
- Scaling Expertise Required: While Hopx handles infrastructure, deploying thousands of concurrent agents requires understanding resource allocation, cost optimization, and multi-tenant isolation patterns. Large-scale deployments demand expertise beyond simple integration.
- Network Configuration Complexity: Advanced use cases requiring specific network isolation, inter-agent communication patterns, or external service connectivity may require thoughtful configuration.
- Cold Start Advantages Diminish at Scale: While 100ms startup is incredibly fast, deploying thousands of concurrent sandboxes means aggregate startup latency becomes measurable. Careful resource scheduling optimizes efficiency.
How It Compare
Hopx operates in the code execution infrastructure landscape positioned distinctly from general serverless, container platforms, and GPU compute services:
Serverless Code Execution Platforms (AWS Lambda, Google Cloud Functions, Azure Functions): These provide event-driven code execution with automatic scaling and zero infrastructure management. AWS Lambda offers 2-second cold starts (improved from historical 5+ seconds), event-driven invocation, and extensive AWS integration. Cold start latency suitable for most workloads but unsuitable for real-time interactive agents. Arbitrary timeout limits (15 minutes) require orchestration workarounds for longer tasks. Stateless invocation model forces complex state management. Hopx differs through stateful persistence, no timeout limits, and 100ms cold starts—trading general-purpose event-driven simplicity for specialized agent infrastructure requirements.
Container/Kubernetes Platforms (Docker, Kubernetes, container registries): Provide packaging and orchestration for containerized workloads. Excellent for traditional application deployment, microservice architectures, and batch processing. Container startup (200-500ms typical) faster than full VMs but slower than Hopx. Shared kernel architecture creates security vulnerabilities for untrusted code execution. State management requires external systems. Hopx trades general-purpose flexibility for specialized safety and speed when executing untrusted code.
Specialized MicroVM Platforms (Northflank, Kata Containers): Northflank provides microVM deployment supporting Kata Containers, gVisor, Firecracker, and Cloud Hypervisor runtimes. Offers security and speed advantages over containers. However, Northflank focuses on general microVM application deployment rather than specialized agent infrastructure. Hopx optimizes specifically for AI agent orchestration, untrusted code execution, and persistent workloads—providing purpose-built abstractions (sandbox templates, agent mesh, streaming output) vs general-purpose VM deployments.
GPU Cloud Platforms (Lambda Cloud, Gradient AI, RunPod, Modal): Provide access to GPU hardware for ML training and inference. Lambda Cloud specializes in bare metal GPU access for research and training; Gradient AI offers managed GPU notebooks; RunPod provides serverless GPU inference; Modal combines serverless platform with GPU access. These excel at computationally intensive workloads. Hopx provides CPU-based sandbox infrastructure—different hardware profiles for different use cases. Hopx’s strength isn’t compute performance but isolation, speed, and statefulness.
General-Purpose AI Inference Platforms (Replicate, Baseten, Together): These serve pre-built AI models through APIs or serverless deployment. Replicate enables running open-source models serverlessly; Baseten manages ML model deployment at scale. These optimize model inference latency and serving infrastructure. Hopx differs fundamentally: rather than serving models, Hopx executes arbitrary user/LLM code safely—completely different use case spectrum.
Multi-Agent Orchestration Frameworks (LangGraph, AutoGen, CrewAI): These provide software libraries for building and coordinating multi-agent workflows. Excellent for agent logic and reasoning patterns. However, they delegate code execution to underlying infrastructure. Hopx provides execution layer these frameworks orchestrate on—complementary rather than competing.
Hopx’s competitive differentiation centers on specialized sandbox infrastructure: 100ms latency combining VM-level security with serverless responsiveness, stateful persistence enabling agent continuity, no artificial timeout limits supporting long-running processes, and purpose-built agent orchestration. For teams deploying autonomous AI agents requiring secure untrusted code execution, extended runtime durations, and coordinated multi-agent workflows—Hopx delivers specialized infrastructure bridging security, performance, and persistence constraints that general-purpose platforms cannot simultaneously optimize.
Final Thoughts
Deploying AI agents at scale creates infrastructure challenges general-purpose platforms misalign with: serverless sacrifices state and duration for simplicity; containers sacrifice security for flexibility; traditional VMs sacrifice speed for safety. These tradeoffs constrain agent architectures, forcing compromises on security, performance, or operational simplicity.
Hopx represents different approach: purpose-built infrastructure optimizing specifically for agent deployment requirements. By combining Firecracker hardware isolation with snapshot-based speed, stateful persistence with unlimited runtime, and multi-agent orchestration with granular resource controls—Hopx delivers execution infrastructure where security, performance, and statefulness coexist rather than compromise.
For AI teams building sophisticated agents, researchers requiring long-running workloads with full system access, platforms isolating user code safely, or organizations executing untrusted LLM-generated code—Hopx provides specialized infrastructure transforming previously difficult constraints into reliable operations. As autonomous agents mature from experimental tools toward production systems, infrastructure platforms optimizing specifically for agent requirements become essential—precisely the niche Hopx occupies.