Overview
In the rapidly evolving landscape of artificial intelligence, new models emerge with promises of enhanced capabilities and efficiency. Today, we’re diving deep into MiMo-V2-Flash, a 309B MoE (Mixture of Experts) model developed by Xiaomi. This powerhouse is engineered for performance in demanding tasks like reasoning and coding, while also serving as a capable general-purpose assistant. The model was released on December 16, 2025, and represents Xiaomi’s entry into the frontier AI development space.
Important Correction: The official blog post is at https://mimo.xiaomi.com/mimo-v2-flash, not the previously stated URL.
Key Features
MiMo-V2-Flash stands out with a suite of features designed for optimal performance and versatility:
- Powerful MoE Architecture: 309 billion total parameters with 15 billion actively engaged per inference, allowing for computational power without the prohibitive cost of activating all parameters.
- High Reasoning and Speed: Delivers 150 tokens per second inference speed through Multi-Token Prediction and self-speculative decoding, making it 2-3x faster than many competitors.
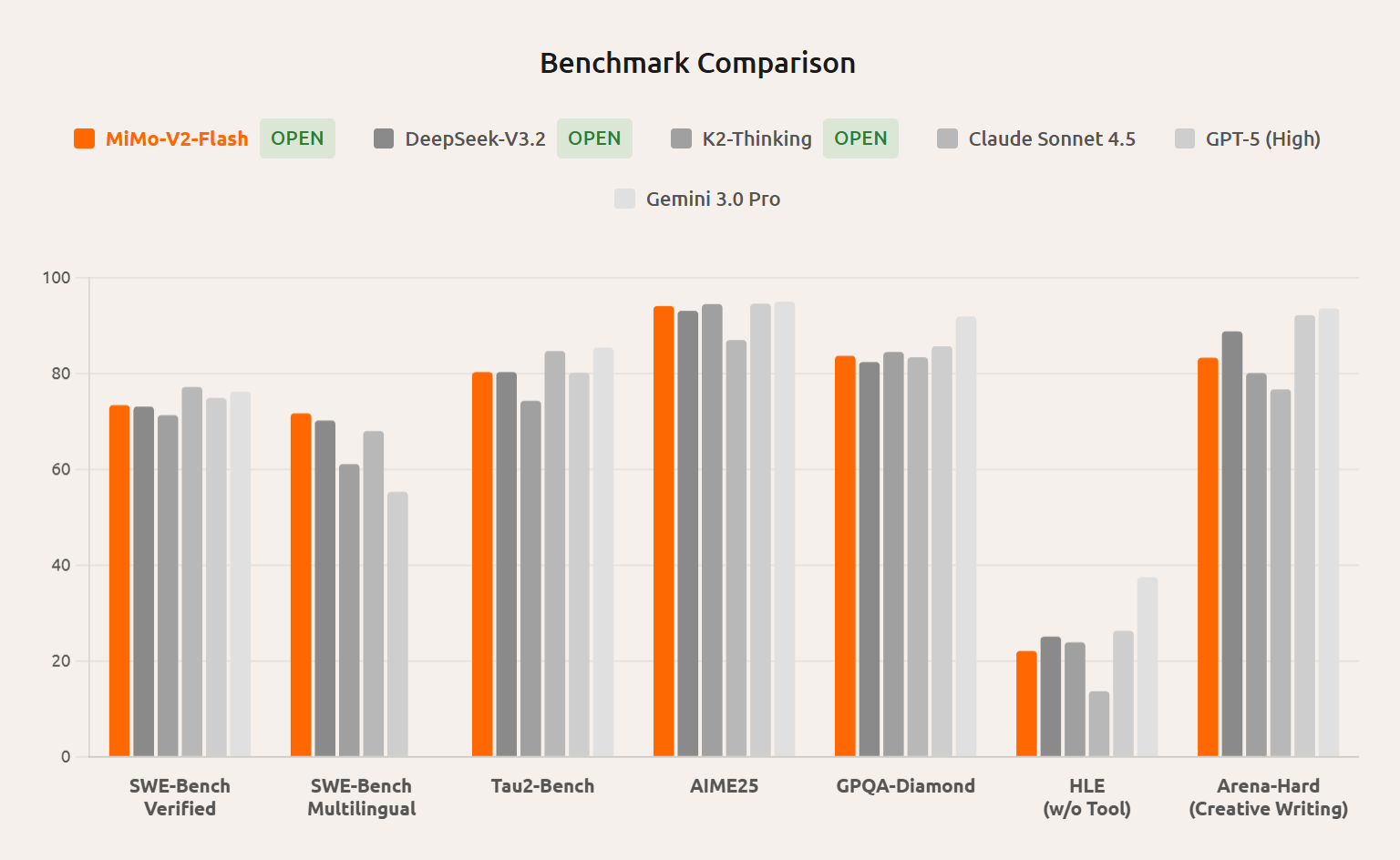
- Optimized for Coding and Agentic Scenarios: Achieved 73.4% on SWE-Bench Verified, ranking #1 among open-source models and approaching GPT-5-High performance.
- Highly Efficient: The MoE architecture contributes significantly to efficiency, enabling top-tier performance while consuming fewer resources compared to monolithic models of similar scale.
- Hybrid Attention Architecture: Interleaves Sliding Window Attention (SWA) and Global Attention (GA) with a 5:1 ratio and 128-token window, reducing KV-cache storage by nearly 6x while maintaining long-context performance.
- Multi-Token Prediction (MTP): Equipped with lightweight MTP modules (0.33B params/block) that triple output speed during inference.
- Ultra-Long Context: Supports up to 256,000 tokens, enabling processing of entire codebases and extended conversations.
How It Works
The efficiency and power of MiMo-V2-Flash are rooted in its Mixture of Experts (MoE) architecture. Unlike traditional large language models that engage all parameters for every task, MiMo-V2-Flash intelligently activates only a subset of its vast parameter pool through a gating mechanism that routes specific parts of the input to specialized “expert” subnetworks. These experts are trained to handle different types of data or tasks, allowing the model to distribute the reasoning process across specialized units.
The hybrid attention mechanism further enhances efficiency by using a 5:1 ratio of Sliding Window Attention to Global Attention, reducing computational overhead while maintaining long-context understanding through learnable attention sink bias. The Multi-Token Prediction module enables self-speculative decoding, drafting multiple tokens that the main model verifies in parallel, achieving 2.0-2.6x speedup.
Use Cases
The versatility of MiMo-V2-Flash opens doors to a wide array of applications:
- Advanced AI Applications: Powering sophisticated AI systems that require deep understanding and complex decision-making.
- Cutting-Edge Research: Serving as a foundation for researchers exploring new frontiers in natural language processing and AI capabilities.
- General Conversational Agents: Providing users with an intelligent assistant for everyday tasks, information retrieval, and creative content generation.
- Coding Assistants: Offering developers powerful support for code generation, debugging, explanation, and optimization.
- Mathematical Reasoning: Strong performance on AIME 2025 (94.1%) and MMLU-Pro (84.9%) makes it suitable for complex mathematical problem-solving.
Pros \& Cons
Advantages
- Exceptional Efficiency: The MoE design significantly reduces computational overhead, making it more resource-friendly than dense models.
- Superior Power: Despite efficiency, it packs immense capability, handling complex tasks with strong benchmark performance.
- Advanced Reasoning Capabilities: Excels in logical deduction, problem-solving, and understanding nuanced contexts.
- Cost-Effective: Priced at \$0.1 per million input tokens and \$0.3 per million output tokens—significantly cheaper than Claude Sonnet 4.5.
- Fully Open Source: Available on Hugging Face with MIT license, allowing local deployment and customization.
Disadvantages
- Infrastructure Demands: Deploying and running MiMo-V2-Flash effectively requires substantial computational infrastructure (recommended: 8x A100/H100 GPUs for enterprise deployment).
- Inconsistent Instruction Following: Community testing reveals reliability issues with complex multi-turn conversations and tool calling workflows.
- Benchmark Discrepancies: While official benchmarks show competitive performance, real-world testing by users reports mixed results compared to established models.
- Limited Ecosystem Support: Currently lacks support in some popular inference frameworks like llama.cpp.
- New and Unproven: As a recently released model, it lacks the extensive community validation and trust that established models have built.
How Does It Compare?
vs. GPT-4/GPT-5
GPT-4/GPT-5 Strengths: Established reliability, consistent instruction following, robust tool use, extensive ecosystem integration, proven performance across diverse tasks.
MiMo-V2-Flash Differentiation: Claims competitive performance on coding benchmarks (73.4% SWE-Bench vs GPT-5-High) at 2.5% of Claude’s cost. Offers 256K context window vs GPT-4’s 128K. However, community reports indicate GPT models maintain superior consistency and reliability in production environments.
Key Distinction: While MiMo-V2-Flash matches or exceeds GPT-5 on specific benchmarks, GPT models offer more predictable behavior and broader ecosystem support. MiMo’s cost advantage is significant for high-volume use cases.
vs. Claude Sonnet 4.5
Claude Sonnet 4.5 Strengths: Exceptional reasoning, strong coding capabilities, reliable performance, good instruction following, established reputation.
MiMo-V2-Flash Differentiation: Claims to match or exceed Claude on SWE-Bench Multilingual while being substantially cheaper (\$0.3/M output vs Claude’s ~\$15/M). Offers faster inference (150 tok/s vs ~30-40 tok/s). However, Claude maintains advantages in consistency and complex reasoning tasks.
Key Distinction: MiMo-V2-Flash offers compelling cost-performance ratio for coding tasks, but Claude’s proven reliability makes it preferable for mission-critical applications. The 50x price difference favors MiMo for experimental and high-volume scenarios.
vs. DeepSeek-V3.2
DeepSeek-V3.2 Strengths: 671B parameters with 37B active, proven strong performance, established community trust, reliable instruction following, excellent coding capabilities.
MiMo-V2-Flash Differentiation: Despite fewer total parameters (309B vs 671B), claims competitive or superior performance on most benchmarks. Achieves 150 tok/s vs DeepSeek’s ~30 tok/s—5x faster inference. More aggressive efficiency optimizations with 5:1 hybrid attention ratio.
Key Distinction: MiMo-V2-Flash demonstrates that architectural innovation can compensate for raw parameter count. However, DeepSeek’s established track record and community validation make it more trustworthy for production deployment. MiMo’s speed advantage is compelling for latency-sensitive applications.
vs. Kimi K2
Kimi K2 Strengths: 1043B total parameters, excellent long-context performance, strong Chinese language capabilities (90.9% on CMMLU vs MiMo’s 87.4%), advanced thinking mode.
MiMo-V2-Flash Differentiation: Activates only 15B parameters vs Kimi’s 32B, making it more efficient. Achieves comparable AIME 2025 scores (94.1% vs 94.5%). Offers 256K context vs Kimi’s strong long-context capabilities.
Key Distinction: MiMo-V2-Flash provides better parameter efficiency and faster inference, while Kimi K2 excels in Chinese language tasks and has more established long-context reliability. For English-centric coding tasks, MiMo’s efficiency is advantageous.
vs. Gemini
Gemini Strengths: Multimodal capabilities, strong reasoning, Google ecosystem integration, reliable performance.
MiMo-V2-Flash Differentiation: Currently text-only, lacking Gemini’s multimodal strengths. Claims competitive coding performance at lower cost. Offers longer context window (256K vs Gemini’s varying limits).
Key Distinction: MiMo-V2-Flash cannot compete with Gemini’s multimodal capabilities. For text-only coding and reasoning tasks, MiMo offers cost advantages, but Gemini’s broader capability set makes it more versatile.
Final Thoughts
MiMo-V2-Flash by Xiaomi represents an ambitious entry into frontier AI development. Its powerful MoE architecture, coupled with exceptional speed and competitive benchmark performance, makes it a compelling choice for developers and researchers seeking an efficient yet capable foundation model. The 150 tokens/second inference speed and 73.4% SWE-Bench score demonstrate genuine technical achievement.
However, prospective users should approach with measured expectations. Community testing reveals inconsistencies in instruction following and tool calling that may limit production readiness. While official benchmarks show promise, the gap between benchmark performance and real-world reliability suggests the model requires further refinement.
Expert Perspective: For organizations with established AI infrastructure and the ability to handle occasional inconsistencies, MiMo-V2-Flash offers exceptional value—particularly for coding assistance and mathematical reasoning tasks. The cost advantage is substantial for high-volume applications. However, mission-critical deployments should wait for broader community validation or consider hybrid approaches where MiMo handles specific tasks while more reliable models manage complex workflows.
Implementation Recommendation: Start with non-critical coding assistance and mathematical reasoning tasks. Use temperature settings appropriate for the task (0.3 for coding/agents, 0.8 for math/writing). Enable Multi-Token Prediction for speed benefits. Monitor for instruction-following issues and have fallback models available for complex multi-turn conversations. The model shows promise but requires careful evaluation within your specific use case before full production deployment.
https://mimo.xiaomi.com/blog/mimo-v2-flash