Overview
In the rapidly evolving landscape of artificial intelligence, real-time interaction capabilities have become paramount for creating truly responsive and natural user experiences. Enter Kyutai TTS, a groundbreaking open-source text-to-speech model that establishes new standards for ultra-low latency speech synthesis. Unlike conventional TTS systems that require complete text input before generating audio, Kyutai TTS employs an innovative delayed streams modeling architecture that enables simultaneous text input processing and audio output generation. This revolutionary approach makes it exceptionally well-suited for integration with large language model applications, facilitating genuinely fluid and natural voice interactions that respond dynamically to streaming text input.
Key Features
Kyutai TTS distinguishes itself through advanced features specifically engineered for high-performance, real-time speech synthesis applications.
- Real-time streaming text-to-speech synthesis: Delivers speech generation that begins immediately upon receiving initial text tokens, eliminating traditional processing delays through innovative streaming architecture.
- Comprehensive open-source accessibility: Released under CC-BY 4.0 license, providing complete freedom for research, modification, and commercial integration without proprietary constraints or usage restrictions.
- Revolutionary simultaneous input/output architecture: Utilizes delayed streams modeling to enable concurrent text input processing and audio output generation, achieving unprecedented low-latency performance of 220 milliseconds.
- Advanced LLM integration optimization: Specifically architected to seamlessly interface with large language models, supporting dynamic text streaming and enabling responsive conversational AI experiences.
How It Works
Kyutai TTS fundamentally reimagines the text-to-speech synthesis process through its innovative delayed streams modeling approach. Rather than following traditional sequential processing patterns that require complete text input, the model operates on continuous, time-aligned streams of text and audio data. The system begins generating high-quality audio output immediately upon receiving the first few text tokens, regardless of final text length. This simultaneous processing capability is achieved through a sophisticated 1.6-billion parameter hierarchical Transformer architecture that has been meticulously optimized for real-time performance. The model employs a unique action stream mechanism that coordinates text input alignment with audio generation, utilizing padding tokens to maintain proper temporal synchronization. For enhanced analysis or extended conversational capabilities, the generated audio integrates seamlessly with complementary AI systems, though the core TTS functionality operates independently with exceptional efficiency.
Use Cases
The real-time capabilities and advanced architecture of Kyutai TTS enable diverse applications across multiple domains requiring immediate speech synthesis.
- Next-generation voice assistant development: Powers responsive voice interfaces that provide instantaneous audio feedback, creating more natural and engaging user interactions compared to traditional delayed response systems.
- Real-time accessibility and captioning solutions: Enables immediate audio conversion for live events, supporting individuals with hearing impairments through dynamic, low-latency speech synthesis that maintains conversation flow.
- Enhanced LLM-powered voice applications: Facilitates fluid conversational experiences in language model applications by processing streaming text input, eliminating artificial pauses and creating natural dialogue patterns.
- Interactive media and entertainment platforms: Supports immersive storytelling and gaming experiences where characters respond instantly to user input, enhancing engagement through immediate audio feedback.
Pros \& Cons
Kyutai TTS offers significant advantages while maintaining transparency about current limitations and considerations.
Advantages
- Industry-leading latency performance: Achieves 220ms first-token latency, with production deployment capable of 350ms latency while serving 32 concurrent users on a single L40S GPU, setting new standards for real-time speech synthesis.
- Comprehensive open-source framework: Provides complete model access, training methodologies, and implementation code under permissive licensing, enabling extensive customization and community-driven development.
- Purpose-built LLM compatibility: Designed specifically for large language model integration, offering optimized streaming text processing and dynamic audio generation that enhances conversational AI applications.
Disadvantages
- Hardware resource requirements: Requires GPU acceleration for optimal real-time performance, with recommended L40S GPU configuration for production deployments serving multiple concurrent users.
- Limited language support: Currently supports English and French languages, though the development team is actively exploring expansion to additional languages based on community needs and contributions.
- Emerging technology considerations: As a recently released model (July 2025), some advanced features and optimizations continue to evolve through ongoing development and community feedback.
How Does It Compare?
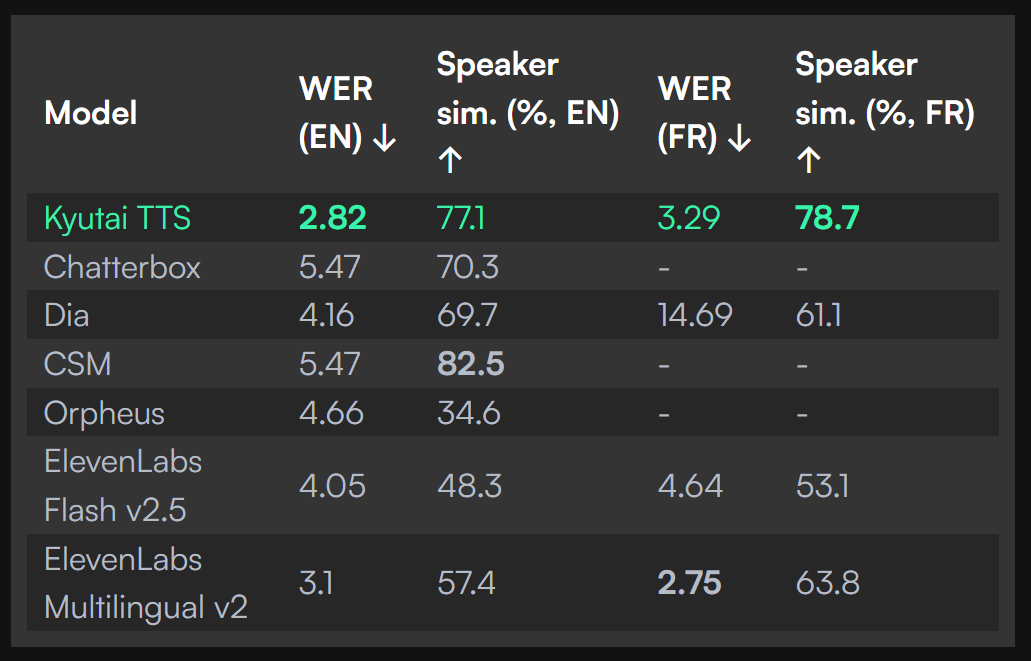
When evaluated against the current competitive landscape, Kyutai TTS establishes distinctive advantages in the rapidly evolving text-to-speech market.
ElevenLabs Flash v2.5 represents a leading commercial solution offering robust voice synthesis capabilities with a WER of 4.05% for English. While ElevenLabs provides high-quality output and extensive voice options, it operates as a proprietary service with associated usage costs and does not match Kyutai’s 220ms latency performance for streaming applications.
Coqui TTS (the successor to Mozilla TTS, which ceased development in 2021) offers a comprehensive open-source framework with multilingual support and customizable voice training capabilities. However, Coqui TTS primarily focuses on traditional batch processing rather than the real-time streaming text input that defines Kyutai’s innovative approach.
F5-TTS and Kokoro-82M represent recent advances in efficient TTS processing, with Kokoro-82M achieving sub-0.3-second processing times for traditional text-to-speech tasks. While these models excel in speed for complete text processing, they lack Kyutai’s unique streaming text input capability that enables audio generation from partial text.
Dia 1.6B and Spark-TTS demonstrate the evolution toward LLM-based speech synthesis approaches. Dia 1.6B achieves competitive accuracy with a 4.16% WER for English, while Spark-TTS introduces innovative token-based processing. However, neither model offers Kyutai’s combination of streaming text input processing and ultra-low latency performance.
Kyutai TTS’s primary differentiator lies in its delayed streams modeling architecture, which enables true streaming text-to-speech conversion rather than merely streaming audio output. This fundamental innovation allows the model to begin speech synthesis immediately upon receiving initial text tokens, creating a responsive experience that significantly outperforms traditional approaches where complete text input is required before audio generation begins.
Final Thoughts
Kyutai TTS represents a paradigm shift in text-to-speech technology, particularly for applications demanding immediate, natural voice interaction capabilities. Its innovative delayed streams modeling approach, combined with industry-leading 220ms latency performance and comprehensive open-source accessibility, positions it as a transformative solution for developers building real-time voice applications, interactive conversational AI systems, and accessibility-focused tools. While the model currently supports English and French languages and represents emerging technology with ongoing development, its core architectural innovations and demonstrated performance metrics establish it as a significant advancement in speech synthesis technology. The combination of streaming text processing, ultra-low latency performance, and seamless LLM integration creates unprecedented opportunities for natural human-AI voice communication experiences.
https://kyutai.org/next/tts