Table of Contents
Overview
Building semantic search systems for AI agents traditionally requires managing complex infrastructure: selecting embedding models, implementing chunking strategies, maintaining vector databases, and tuning re-ranking algorithms. This fragmented approach forces developers to orchestrate multiple specialized tools, each with its own API, configuration requirements, and operational overhead.
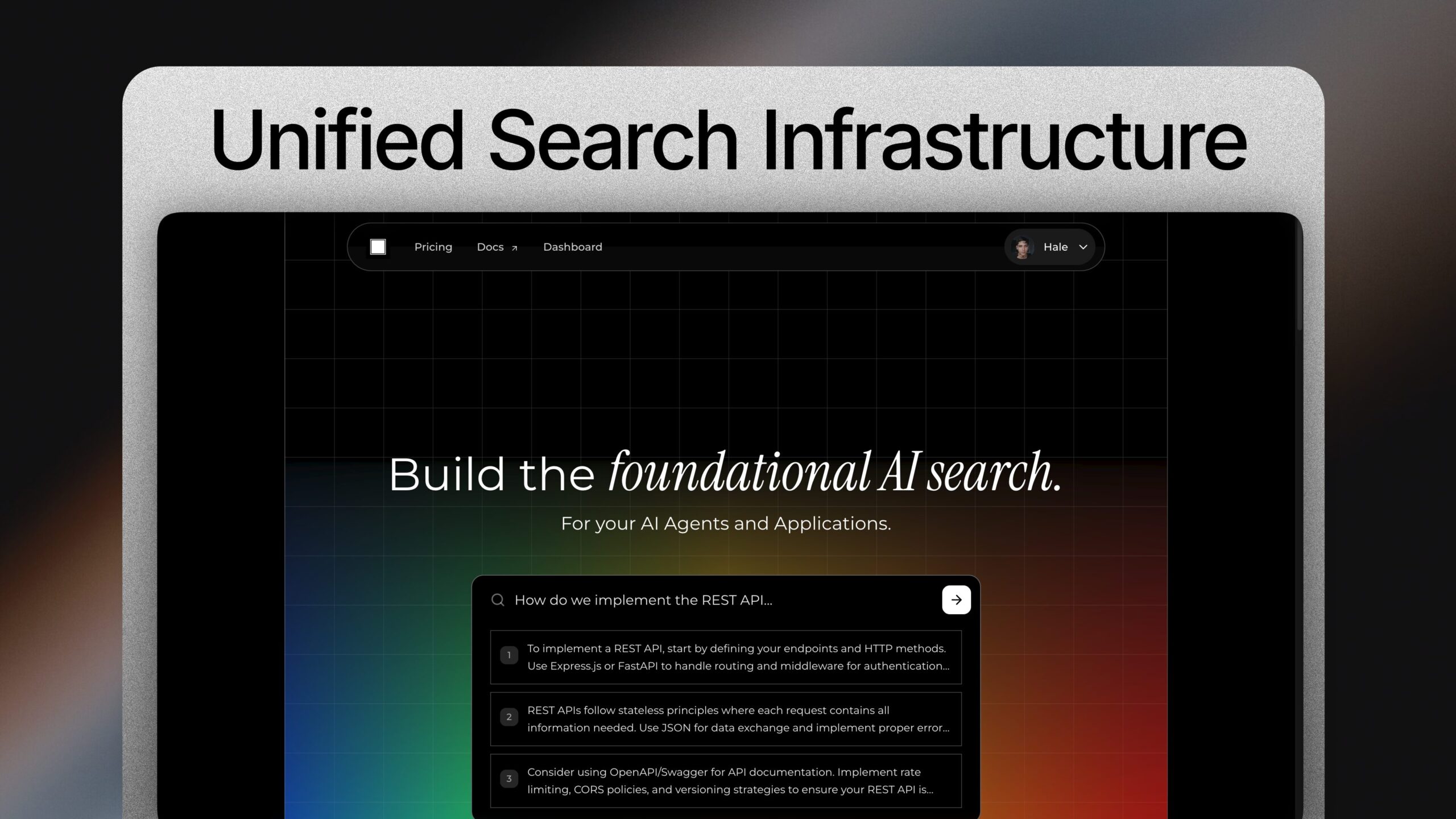
Asimov transforms this process by providing a unified, managed vector search platform designed specifically for AI applications. Rather than assembling separate components, developers upload documents once and immediately access powerful semantic search through a single API endpoint. The platform handles embedding generation, intelligent chunking, vector storage, and contextual re-ranking automatically—eliminating the infrastructure complexity that typically slows AI development.
Built on modern infrastructure optimized for AI workloads, Asimov enables developers to focus on agent logic and application features rather than vector database operations. The platform launched in 2024 and is designed for teams building retrieval-augmented generation (RAG) systems, AI agents, semantic search applications, and knowledge-intensive AI systems at scale.
Key Features
Asimov delivers a comprehensive vector search solution with features purpose-built for AI applications:
- Automatic document ingestion and preprocessing: Upload PDFs, text documents, web pages, or unstructured data directly. Asimov automatically detects content structure, intelligently chunks documents based on semantic boundaries, and prepares data for embedding without manual configuration.
- Unified API endpoint: Access all capabilities through a single, simple API rather than managing separate embedding, chunking, storage, and re-ranking services. This dramatically reduces integration complexity and accelerates development timelines.
- Intelligent automatic embedding and chunking: The platform selects optimal embedding models for your content type, automatically segments documents into semantically coherent chunks, and maintains context windows appropriate for your use case—all without manual tuning.
- Built-in semantic re-ranking: Beyond initial vector similarity search, Asimov applies sophisticated re-ranking algorithms that reorder results based on deep contextual understanding, improving result relevance compared to basic vector similarity matching.
- Enterprise-grade security: Data encryption at rest using AES-256 and in transit with TLS 1.3, role-based access controls, optional private cloud deployment, and compliance with major regulatory standards ensure your sensitive data remains protected.
- Comprehensive monitoring and analytics: Track usage patterns, API call metrics, and data access through built-in analytics, providing visibility into application performance and user behavior.
- Interactive playground: Experiment with different queries, test chunking strategies, and refine search behavior through a user-friendly interface without writing code.
- Multi-tenancy support: Built-in tenant isolation enables serving multiple organizations or projects from a single deployment, with role-based access ensuring data separation and security.
How It Works
Asimov streamlines vector search through an elegant, automated workflow:
- Upload your source documents: Users provide documents in any format—PDFs, text files, web pages, markdown, presentations, or raw text. The platform accepts both single files and bulk uploads for large data migrations.
- Asimov automatically prepares your data: The platform analyzes content structure, applies semantic chunking to divide documents at meaningful boundaries (not just fixed character counts), automatically generates embeddings using optimized models, and stores vectors with full metadata.
- Search via simple API request: Once processed, developers search across all uploaded data using a single API endpoint. The platform retrieves semantically relevant results and applies multi-stage re-ranking for improved accuracy.
- Intelligent context retrieval for AI agents: Results are formatted specifically for agent consumption, including source metadata, chunk boundaries, and confidence scores, enabling agents to reason over retrieved information with full context.
The technical foundation uses state-of-the-art embedding models with automatic model selection based on content type, semantic-aware chunking that preserves document structure and relationships, and hybrid re-ranking combining vector similarity with keyword matching when beneficial. This architecture ensures results remain relevant across diverse query types while minimizing hallucination risk in downstream AI systems.
Use Cases
Asimov’s unified approach serves organizations across multiple AI application categories:
- Retrieval-augmented generation for intelligent agents: Provide AI agents with instant access to accurate, contextually relevant organizational data. Asimov enables agents to retrieve precise information from proprietary documents, reducing hallucinations and improving response accuracy for customer support, internal research, and decision-support applications.
- Enterprise knowledge base search: Transform internal documentation, policies, procedures, and institutional knowledge into instantly searchable systems. Employees and AI systems gain fast semantic access to company information without manual indexing or maintenance.
- Context-aware chatbots and virtual assistants: Power conversational AI with the ability to understand complex, multi-turn queries and retrieve precise answers from uploaded documents, enabling chatbots that provide accurate, sourced responses rather than generic information.
- Legal document analysis and discovery: Accelerate legal research by enabling rapid semantic search across vast contracts, regulatory documents, and case law databases, identifying relevant documents faster than keyword search while reducing review time for legal teams.
- Automated semantic search and content discovery: Implement intelligent search systems that understand user intent rather than relying on keywords, enabling applications that discover relevant information across diverse, large-scale datasets automatically.
- Academic and scientific research systems: Enable researchers to semantically search across papers, datasets, and domain knowledge bases to discover connections and related work that keyword search would miss.
Pros \& Cons
Advantages
- Eliminates infrastructure complexity: Removes the need to select, integrate, and manage separate embedding APIs, chunking logic, vector databases, and re-ranking services, significantly reducing development and operational overhead.
- Rapid integration and deployment: A single unified API dramatically reduces integration complexity. Developers can deploy semantic search in hours rather than weeks, with automatic configuration eliminating tuning burden.
- High-quality search results: Built-in re-ranking and semantic chunking deliver more relevant results than basic vector similarity search, improving AI agent accuracy and user satisfaction without manual optimization.
- Enterprise-grade security and compliance: Comprehensive encryption (AES-256 at rest, TLS 1.3 in transit), multi-tenancy support, role-based access control, and regulatory compliance support (HIPAA, GDPR, SOC 2) make it suitable for sensitive, regulated data environments.
- Optimized for AI workloads: Architecture and API design specifically address AI and agent use cases, with result formatting tuned for LLM consumption rather than adapted from general-purpose databases.
- Built-in re-ranking mechanism: Automatically optimizes search results for contextual relevance, delivering more accurate answers than basic vector similarity without requiring manual algorithm tuning or fine-tuning expertise.
Disadvantages
- Vendor lock-in concerns: Relying on a unified, managed platform creates dependency on a single vendor for critical functionality. Migrating to alternative systems would require re-processing all data and rewriting integrations.
- Limited infrastructure customization: As a managed service, you cannot customize underlying algorithms, select alternative embedding models for specialized requirements, or optimize for domain-specific chunking strategies beyond built-in options.
- Pricing at scale: For organizations processing enormous document volumes, usage-based pricing models may become expensive compared to self-managed vector databases where infrastructure costs flatten after initial setup.
- Cold start latency: Initial document processing and embedding generation incurs latency not present in pre-indexed databases, potentially affecting real-time applications requiring immediate results on first data loads.
- Limited advanced customization: Organizations requiring highly specialized embedding models, custom re-ranking logic, or specific metadata filtering operations may exceed the platform’s configuration flexibility.
How Does It Compare?
In November 2025, vector search platforms serve different architectural philosophies and organizational needs, each with distinct strengths.
Self-managed vector databases like Qdrant provide open-source flexibility with Rust-based performance optimization, prioritizing speed for teams comfortable managing infrastructure. Qdrant requires developers to implement their own embedding pipelines, handle chunking logic, and manage vector storage operations. Weaviate combines vector search with graph capabilities and rich metadata filtering, enabling complex data relationships alongside semantic search but requiring infrastructure expertise. These platforms excel for organizations with specialized requirements or extreme scale demands but demand operational overhead.
Managed vector database platforms like Pinecone offer serverless scaling and impressive performance benchmarks, with recent additions of managed embedding services. Pinecone provides more automation than Qdrant but still requires developers to orchestrate search pipelines and implement application-specific re-ranking logic. Enterprise LMS platforms like Zilliz extend vector search with distributed scaling for massive datasets (billion-scale vectors) and specialized hardware optimization, appealing to organizations processing enormous document corpora but typically requiring significant operational expertise.
Open-source or lightweight solutions like Chromadb prioritize simplicity and local-first operation, ideal for prototyping and development but typically lacking enterprise security, managed scalability, or organizational governance features.
Asimov occupies a distinct category: fully managed vector search specifically engineered for AI agents and retrieval-augmented generation applications. Unlike traditional vector databases requiring developers to orchestrate separate embedding, chunking, storage, and re-ranking components, Asimov automates the entire pipeline through a single API. This unified approach trades deep customization flexibility for development velocity—organizations sacrifice fine-grained algorithm control in exchange for rapid deployment and reduced operational burden.
The key differentiator is time-to-production for AI-ready systems: organizations can deploy production semantic search in hours from document upload, without infrastructure expertise or vector database operations knowledge. This positioning makes Asimov particularly valuable for startups, smaller teams, enterprises prioritizing rapid feature deployment, or organizations building their first RAG system.
Developers evaluating platforms should consider: Do you need maximum performance and customization for specialized requirements (Qdrant, Weaviate)? Do you require managed infrastructure with flexible customization (Pinecone)? Do you need distributed enterprise-scale operations (Zilliz)? Or do you prioritize rapid deployment of AI-ready search with fully managed end-to-end systems (Asimov)? Each platform excels in its category; the optimal choice depends on your team’s infrastructure expertise, customization requirements, and deployment timeline priorities.
Final Thoughts
Asimov addresses a genuine pain point in AI application development: the fragmentation of embedding, storage, and search infrastructure. By unifying these components under a single managed API, it reduces the operational friction that typically slows semantic search deployment.
For teams building AI agents, retrieval-augmented generation systems, or enterprise knowledge bases—particularly those lacking deep machine learning infrastructure expertise—Asimov’s managed, unified approach represents a significant productivity advantage. The platform’s automatic optimization and built-in re-ranking mean organizations achieve high-quality semantic search without manual tuning or infrastructure management.
The tradeoff involves vendor dependency and reduced customization for advanced use cases. Teams with highly specialized requirements or extreme-scale operations may need the flexibility of traditional vector databases or hybrid approaches. However, for most organizations building their first semantic search systems or prioritizing rapid AI feature deployment, this limitation is typically acceptable.
As vector search becomes foundational infrastructure for AI applications, platforms like Asimov that abstract away infrastructure complexity enable broader adoption of sophisticated semantic capabilities. If simplifying vector search deployment while maintaining production-grade quality, security, and performance is your priority, Asimov merits serious consideration.
https://www.asimov.mov/