
Table of Contents
Overview
As artificial intelligence systems become increasingly complex and autonomous, ensuring their reliability, performance, and quality has emerged as a critical challenge for development teams. Basalt positions itself as a comprehensive AI observability and development platform designed to help teams build production-ready AI features with confidence. Launched in 2024 and recognized through its Product Hunt debut in August 2025, Basalt offers an integrated environment for prototyping, testing, evaluating, and deploying AI agents and workflows composed of multiple prompts and reasoning steps.
The platform addresses a fundamental problem facing AI developers: the difficulty of systematically testing, debugging, and optimizing complex multi-step AI workflows before and after deployment. By providing tools for A/B testing entire agent chains, running evaluations at scale, monitoring production performance, and receiving AI-powered suggestions for improvement, Basalt aims to accelerate the development cycle while maintaining high quality standards for AI-powered applications.
Key Features
Basalt delivers several integrated capabilities designed to support the complete lifecycle of AI feature development:
A/B testing of complete agent workflows: Test entire multi-step AI agent chains directly from your codebase, comparing different prompt versions, model selections, or workflow configurations against real datasets to identify the most effective approaches before deployment. This goes beyond testing individual prompts to evaluate full agent behavior end-to-end.
Extensive AI evaluator template library: Access over 50 pre-built evaluator templates designed to automatically detect common issues including hallucinations, factual inaccuracies, tone inconsistencies, safety violations, and other quality problems. Teams can also create custom evaluators tailored to their specific use cases and success criteria.
AI-powered co-pilot for prompt optimization: Receive automated suggestions for improving prompts based on evaluation results and production performance data. The co-pilot analyzes test outcomes and provides recommendations to enhance effectiveness, clarity, and reliability of prompts without manual trial-and-error iteration.
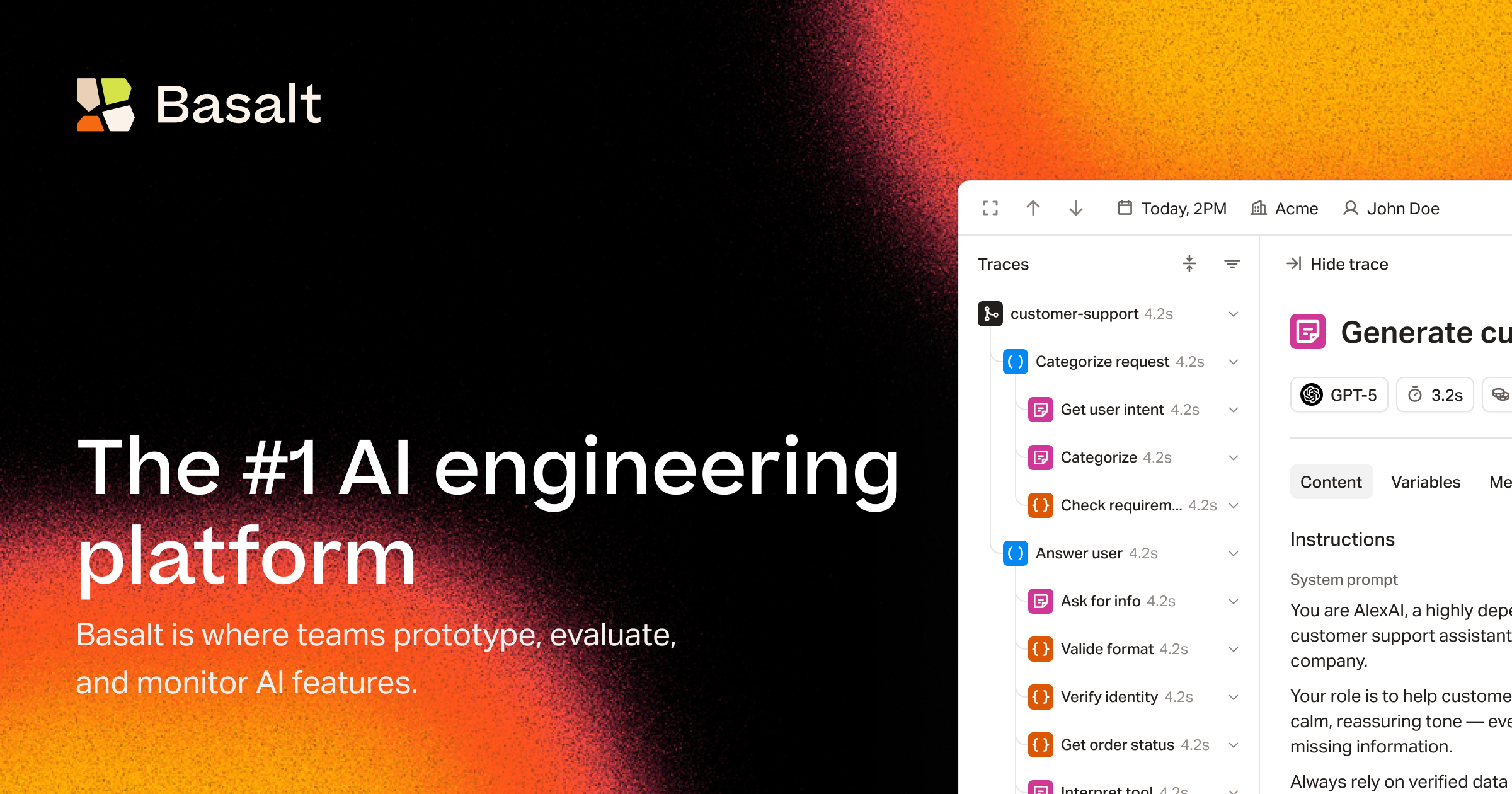
Production tracing and monitoring: Gain visibility into real-time AI agent performance in live environments through detailed logging and tracing capabilities. Monitor usage patterns, track costs across models and users, measure latency, identify error patterns, and receive alerts when metrics exceed defined thresholds.
Step-by-step workflow evaluation: Understand exactly how multi-step AI agents process information by examining detailed traces of each stage in the workflow, making it possible to pinpoint where issues occur and optimize individual components within complex agent systems.
Multi-model support with SDK integration: Work flexibly across various AI model providers including OpenAI, Anthropic, Google, and others. Integrate seamlessly through Basalt’s SDK, manage multiple versions of agents and prompts, and maintain version control for systematic experimentation and rollback capabilities.
No-code playground for rapid prototyping: Build and test prompts through an intuitive visual interface that requires no programming knowledge for initial experimentation, enabling product managers and non-technical team members to participate in AI feature development alongside engineers.
Dataset-driven testing at scale: Run AI workflows against hundreds or thousands of test cases simultaneously, enabling comprehensive evaluation across diverse scenarios to surface edge cases and failure modes before they impact users in production.
How It Works
Basalt operates through an integrated workflow that spans from initial prototyping through production deployment and ongoing optimization. Teams begin by creating prompts and agent workflows either through the no-code playground interface or by integrating Basalt’s SDK directly into their existing codebase. The platform supports both approaches, allowing non-technical users to prototype ideas quickly while enabling engineers to work within their familiar development environments.
Once a workflow is defined, teams upload or generate datasets containing test scenarios that represent real-world use cases. Basalt then executes the AI agent against these datasets, running evaluations using either the platform’s extensive library of pre-built evaluators or custom criteria defined by the team. The system generates detailed performance scores, identifies failure patterns, and highlights areas requiring improvement.
For A/B testing, teams can define multiple versions of an agent workflow with variations in prompts, model selections, or processing logic, then run comparative evaluations to determine which configuration performs best across the test dataset. The platform visualizes results through side-by-side comparisons, making it easy to identify the superior approach.
When ready for deployment, teams integrate the finalized workflow into their production applications through Basalt’s SDK. The platform continues monitoring in live environments, capturing traces of every execution including inputs, outputs, intermediate steps, token usage, latency, and errors. This production telemetry feeds back into the co-pilot system, which analyzes performance data to generate suggestions for further optimization.
Teams receive automated alerts when production metrics deviate from expected baselines, enabling rapid response to emerging issues. The complete cycle—from prototyping through production monitoring and iterative improvement—occurs within a unified platform, reducing context switching and maintaining visibility across the entire AI feature lifecycle.
Use Cases
Basalt serves multiple applications across AI development workflows:
Prototyping and validating complex multi-step AI agents: Teams building sophisticated AI systems involving sequences of prompts, tool calls, reasoning steps, and decision logic can rapidly prototype these workflows and systematically test them against comprehensive datasets before committing to production implementation.
Evaluating AI workflows for quality and accuracy: Organizations concerned with AI reliability can establish rigorous quality assurance processes, running automated evaluations that detect hallucinations, factual errors, bias, safety violations, and other issues across diverse test scenarios to ensure consistent performance.
Monitoring production AI agent performance: Engineering teams can maintain visibility into how deployed AI features perform in real-world conditions, tracking key metrics including response quality, latency, cost, error rates, and user satisfaction to identify optimization opportunities and catch problems before they escalate.
Accelerating prompt engineering cycles: Rather than manually iterating on prompts through trial and error, teams can leverage Basalt’s co-pilot to receive data-driven suggestions for improvements, generate test cases automatically, and systematically compare prompt variations to converge on optimal configurations faster.
Enabling non-technical participation in AI development: The no-code playground allows product managers, designers, and domain experts to contribute to AI feature development by prototyping prompts, defining evaluation criteria, and assessing results without requiring engineering support for every experiment.
Establishing AI governance and compliance: Organizations with regulatory requirements or internal quality standards can use Basalt’s evaluation framework to document testing procedures, demonstrate compliance with safety and accuracy requirements, and maintain audit trails of AI system behavior.
Pros and Cons
Advantages
Comprehensive end-to-end platform: Unlike tools focusing solely on one aspect of AI development, Basalt integrates prototyping, testing, evaluation, deployment, and monitoring in a unified environment, reducing the need to coordinate multiple disconnected tools and maintaining context across the development lifecycle.
Emphasis on systematic testing and evaluation: The platform’s focus on dataset-driven evaluation and A/B testing of complete agent workflows addresses a critical gap in AI development, enabling teams to validate behavior comprehensively before deployment rather than discovering issues in production.
Multi-model flexibility: Support for various AI model providers prevents vendor lock-in and allows teams to experiment with different models or switch providers based on performance, cost, or capability requirements without rebuilding their entire system.
Accessible to non-technical users: The no-code playground democratizes AI feature development, allowing broader team participation and reducing bottlenecks where every experiment requires engineering resources.
Production observability with actionable insights: Rather than simply logging data, Basalt’s co-pilot analyzes production performance to generate specific recommendations for improvement, accelerating optimization cycles.
Free tier for getting started: The platform offers a generous free plan with 1,000 runs per month, unlimited prompts, projects, test cases, evaluators, and users, making it accessible for experimentation and small projects without financial commitment.
Disadvantages
Requires SDK integration for production use: While the playground enables no-code prototyping, actually deploying AI features to production applications requires integrating Basalt’s SDK into codebases, necessitating engineering resources and technical expertise.
Relatively new platform with limited track record: Having launched its Agent Builder feature in October 2025, Basalt lacks the extensive operational history and large user base of more established platforms, which may concern enterprises requiring proven long-term stability.
Pricing transparency limited beyond free tier: Detailed pricing information for paid plans is not publicly disclosed, requiring direct contact with the company for enterprise pricing, which complicates budget planning and cost comparison during evaluation.
Learning curve for complex features: While basic prompt testing is straightforward, fully utilizing advanced capabilities like A/B testing complete agent chains, custom evaluators, and production monitoring requires understanding the platform’s concepts and investment in setup.
Focused primarily on technical teams: Despite the no-code playground, the platform’s core value proposition centers on development workflows, SDK integration, and observability concepts that primarily benefit engineering and technical product teams rather than broader business users.
How Does It Compare?
Understanding Basalt’s positioning relative to other AI development and observability tools clarifies its unique value proposition and alternative options:
Vs. LangSmith: LangSmith, developed by the creators of LangChain, is a comprehensive observability platform optimized for tracing, debugging, and monitoring LLM applications, particularly those built with LangChain and LangGraph frameworks. LangSmith excels in detailed tracing capabilities, showing step-by-step execution of complex chains with full OpenTelemetry support, and provides robust production monitoring with dashboards tracking costs, latency, and quality metrics. However, LangSmith’s primary focus is observability and debugging of existing applications rather than the prototyping and systematic evaluation emphasis of Basalt. Basalt differentiates itself through its AI co-pilot that provides automated prompt improvement suggestions, extensive pre-built evaluator template library for quality assessment, and no-code playground for rapid prototyping. While LangSmith is stronger for teams heavily invested in the LangChain ecosystem seeking deep tracing and debugging capabilities, Basalt is better suited for teams prioritizing systematic A/B testing, comprehensive evaluation before deployment, and AI-assisted optimization workflows across multiple frameworks.
Vs. Vellum: Vellum is an enterprise AI development platform focused on prompt engineering, workflow creation, and deployment management with strong emphasis on collaboration between technical and non-technical team members. Vellum provides side-by-side comparison capabilities for testing different prompt and model combinations, multi-step workflow builders with visual interfaces, evaluation frameworks for assessing performance, and deployment management with version control. Both Vellum and Basalt address similar problems around prototyping and deploying AI features with systematic testing. However, Vellum positions itself more as a complete development platform emphasizing visual workflow building and non-technical user accessibility, whereas Basalt emphasizes observability, systematic evaluation with its extensive evaluator library, and production monitoring with AI-powered optimization suggestions. Vellum may be preferable for organizations prioritizing collaborative workflow design and document retrieval capabilities, while Basalt suits teams focused on rigorous testing, production observability, and automated improvement guidance.
Vs. LangChain Framework: LangChain is an open-source framework providing building blocks for constructing LLM applications, including chains, agents, memory, and tool integration capabilities. As a framework rather than a platform, LangChain focuses on application development rather than testing, evaluation, or monitoring. Developers using LangChain write code to build AI applications but must separately implement testing strategies, evaluation processes, and monitoring infrastructure. Basalt can complement LangChain development by providing the observability, evaluation, and systematic testing capabilities that the framework itself doesn’t include. While LangChain gives developers maximum flexibility and control over application architecture, Basalt provides the structured testing, monitoring, and optimization environment needed to ensure those applications work reliably in production. Teams using LangChain often integrate with LangSmith for observability or could use Basalt as an alternative offering different strengths in evaluation and optimization.
Vs. Haystack: Haystack, developed by deepset, is an open-source framework for building search and question-answering systems powered by LLMs, with particular strength in retrieval-augmented generation (RAG) pipelines and document processing. Haystack provides components for semantic search, document stores, retrievers, and reader models, focusing on information retrieval use cases. While Haystack offers some evaluation capabilities for assessing retrieval and generation quality, it doesn’t provide the comprehensive observability, A/B testing, and production monitoring that Basalt offers. The two platforms serve different primary use cases: Haystack excels for teams building search and RAG applications requiring sophisticated document processing and retrieval capabilities, while Basalt addresses the broader need for testing, evaluating, and monitoring any type of multi-step AI agent workflow. Organizations building RAG systems with Haystack might use Basalt as a complementary tool for systematic evaluation and production observability.
Vs. Weights \& Biases (W\&B): Weights \& Biases is a comprehensive ML ops platform providing experiment tracking, model training monitoring, dataset versioning, and collaborative tools for machine learning teams. While W\&B has expanded to support LLM applications through its Weave product, the platform’s core strengths lie in traditional machine learning workflows including model training, hyperparameter optimization, and experiment management. Basalt specifically targets prompt-based AI applications and agent workflows rather than traditional ML model training. W\&B is better suited for teams developing and fine-tuning machine learning models with extensive training and experimentation processes, while Basalt addresses the distinct needs of teams building applications with foundation models through prompt engineering, agent orchestration, and production deployment of LLM-powered features.
Vs. Braintrust: Braintrust is an enterprise-grade AI product optimization platform offering evaluation, experimentation, and observability specifically designed for AI applications. Like Basalt, Braintrust provides capabilities for evaluating AI outputs, running A/B tests, and monitoring production performance. Both platforms recognize the need for systematic testing and quality assurance in AI development. Braintrust emphasizes enterprise-scale deployments with sophisticated cost analysis, advanced alerting with webhook integrations to tools like PagerDuty and Slack, and built-in AI agents for anomaly detection. The platform also features Thread views for tracing complex multi-step interactions. Basalt differentiates itself through its AI co-pilot providing automated prompt improvement suggestions, extensive library of 50+ evaluator templates, and its no-code playground making experimentation accessible to non-developers. Organizations requiring enterprise-level monitoring with advanced alerting infrastructure might prefer Braintrust, while teams seeking AI-assisted optimization guidance and accessible prototyping tools may find Basalt more suitable.
Final Thoughts
Basalt addresses a genuine challenge in modern AI development: the difficulty of systematically testing, evaluating, and monitoring complex AI agent workflows at both development and production stages. The platform’s integrated approach—combining prototyping, systematic evaluation, A/B testing, production observability, and AI-powered optimization suggestions—provides a comprehensive solution for teams building AI-powered applications who need confidence in their systems’ reliability and performance.
The emphasis on dataset-driven evaluation and testing entire agent workflows rather than isolated prompts represents a maturity in AI development practices, moving beyond informal experimentation toward rigorous quality assurance processes similar to those in traditional software engineering. The extensive library of evaluator templates and AI co-pilot for automated improvement suggestions reduce the manual effort typically required for prompt optimization.
However, prospective users should carefully consider several factors. As a relatively new platform launching its Agent Builder in October 2025, Basalt lacks the extensive operational history of established alternatives. Organizations with strict enterprise requirements around vendor stability may prefer more proven options. The free tier is generous for experimentation, but lack of public pricing transparency for paid plans complicates cost evaluation for production deployments at scale.
The platform appears most compelling for development teams building complex multi-step AI agents who need systematic testing and evaluation capabilities, organizations establishing AI governance and quality assurance processes, and product-focused companies wanting to involve non-technical team members in AI feature development. Teams already heavily invested in specific ecosystems like LangChain with LangSmith, or those primarily needing observability without the prototyping and evaluation emphasis, might find specialized alternatives more suitable.
For organizations evaluating whether Basalt fits their needs, key questions include: Do we build complex multi-step AI agents requiring comprehensive testing? Are we struggling with systematic evaluation and quality assurance for AI features? Do we need both development-time testing and production monitoring in a unified platform? Are we prepared to work with a recently launched platform with evolving features? Would non-technical team participation in AI development provide value?
The AI development tooling landscape continues evolving rapidly, and platforms specifically designed for the unique challenges of agent-based systems—like Basalt—address needs that traditional ML ops tools weren’t built to handle. As organizations move beyond simple prompt-and-response applications toward sophisticated multi-agent systems, infrastructure supporting rigorous testing, evaluation, and observability will become increasingly essential. Basalt represents one approach to meeting these emerging needs, offering teams a structured path from prototype to production-ready AI features with maintained quality standards throughout the lifecycle.