
Table of Contents
- Claude Opus 4.5: Comprehensive Analysis of Anthropic’s Flagship AI Model
- 1. Executive Snapshot
- 2. Impact and Evidence
- 3. Technical Blueprint
- 4. Trust and Governance
- 5. Unique Capabilities
- 6. Adoption Pathways
- 7. Use Case Portfolio
- 8. Balanced Analysis
- 9. Transparent Pricing
- 10. Market Positioning
- 11. Leadership Profile
- 12. Community and Endorsements
- 13. Strategic Outlook
- Final Thoughts
Claude Opus 4.5: Comprehensive Analysis of Anthropic’s Flagship AI Model
1. Executive Snapshot
Core Offering Overview
Claude Opus 4.5 represents Anthropic’s most advanced large language model, released on November 24, 2025. Positioned as the flagship model in the Claude family, it delivers state-of-the-art performance across software engineering, autonomous agent workflows, computer interaction, and complex reasoning tasks. The model builds upon Anthropic’s commitment to developing AI systems that are intelligent, helpful, and aligned with human values.
The model introduces several architectural innovations including an effort parameter that allows developers to control reasoning depth, enhanced context management capabilities supporting extended conversations, and improved multi-agent coordination for constructing sophisticated autonomous systems. Claude Opus 4.5 processes information across text and visual modalities while maintaining what Anthropic describes as the most robust alignment profile among frontier AI models.
Key Achievements and Milestones
Claude Opus 4.5 has established benchmark leadership across critical domains:
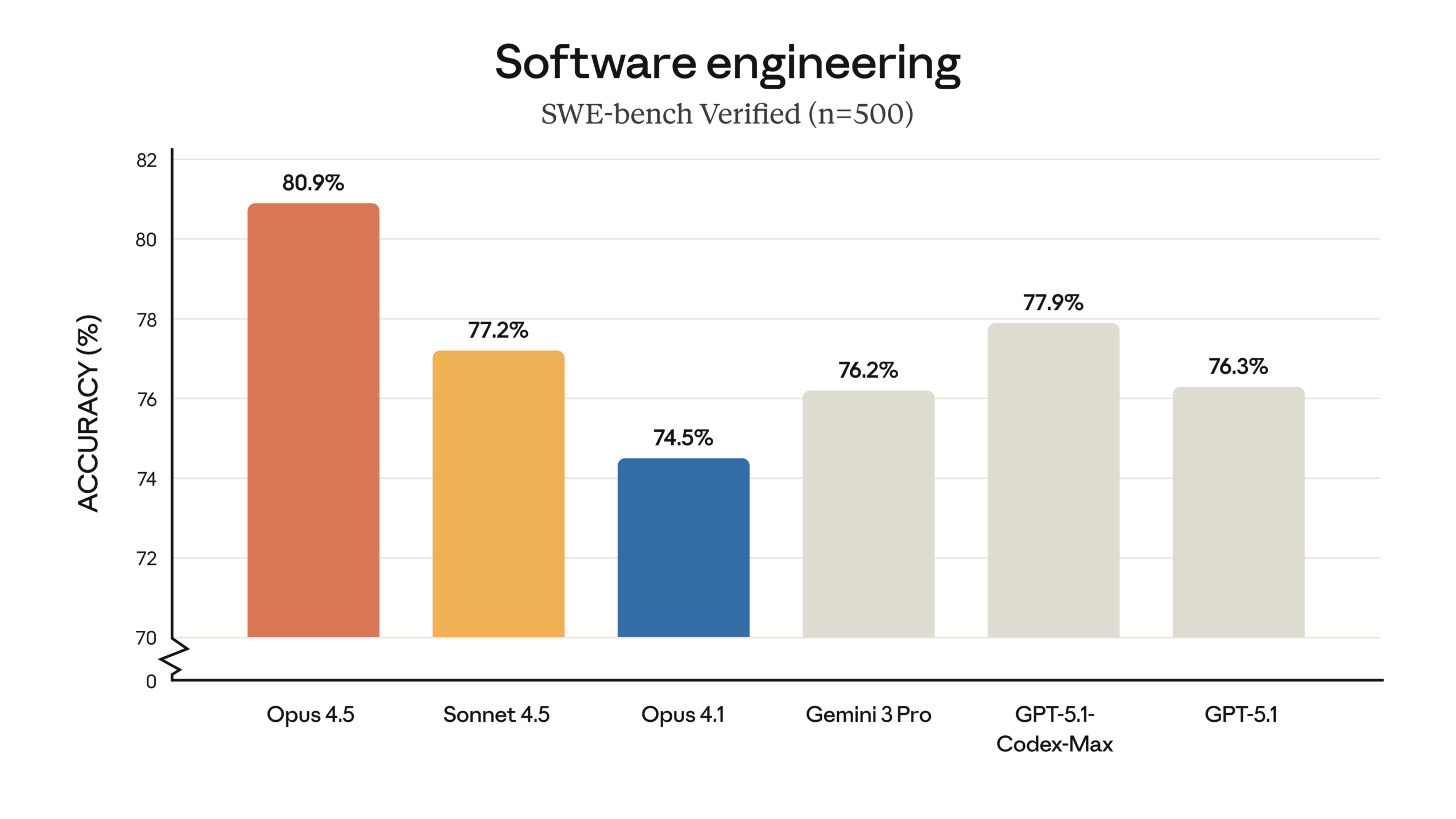
Software Engineering Excellence: The model achieved 80.9% on SWE-bench Verified, becoming the first large language model to surpass the 80% threshold on this real-world software engineering benchmark. This score significantly outpaces OpenAI’s GPT-5.1 Codex-Max (77.9%) and Google’s Gemini 3 Pro (76.2%).
Terminal Operations Mastery: On Terminal-Bench 2.0, which measures proficiency in command-line environments, Opus 4.5 scored 59.3%, exceeding both GPT-5.1 (58.1%) and Gemini 3 Pro (54.2%).
Mathematical Reasoning: When equipped with Python tools, Opus 4.5 achieves 100% accuracy on AIME 2025, matching Gemini 3 Pro’s tool-assisted performance and demonstrating state-of-the-art mathematical reasoning capabilities.
Human Performance Comparison: On Anthropic’s internal performance engineering take-home exam, Opus 4.5 scored higher than any human candidate within the prescribed two-hour time limit—a notable milestone indicating capabilities that approach or exceed expert-level technical judgment under time pressure.
Adoption Statistics
Anthropic’s platform has experienced extraordinary growth trajectory. The company reached \$5 billion in annualized revenue by August 2025, growing from approximately \$1 billion at the beginning of 2025. Projections indicate \$9 billion ARR by end of 2025, with targets of \$20-26 billion for 2026 and potential \$70 billion revenue by 2028.
Enterprise customers drive approximately 80% of Anthropic’s revenue, with over 300,000 businesses utilizing Claude models. The number of customers generating over \$100,000 in run-rate revenue has grown 7x year-over-year. Claude Code, the company’s coding-focused product, has achieved nearly \$1 billion in annualized run rate revenue since its launch, with usage growing more than 10x in just three months.
2. Impact and Evidence
Client Success Stories
Leading technology companies have provided detailed assessments of Claude Opus 4.5’s capabilities:
GitHub Copilot Integration: In early testing for GitHub Copilot, Claude Opus 4.5 surpassed internal coding benchmarks while cutting token usage in half. GitHub describes it as “especially well-suited for accelerating development in professional settings.”
Cursor IDE Performance: Cursor reports that “Claude Opus 4.5 is a notable improvement over the prior Claude models inside Cursor, with improved pricing and intelligence on difficult coding tasks.”
Lovable Platform Experience: Lovable found that “Claude Opus 4.5 delivers frontier reasoning within chat mode, where users plan and iterate on projects. Its reasoning depth transforms planning—and great planning makes code generation even better.”
Warp Terminal Integration: Warp documented “a 15% improvement over Sonnet 4.5” on Terminal Bench, noting this represents “a meaningful gain that becomes especially clear when using Warp’s Planning Mode.”
JetBrains Junie Testing: Based on testing with Junie coding agent, “Claude Opus 4.5 outperforms Sonnet 4.5 across all benchmarks. It requires fewer steps to solve tasks and uses fewer tokens as a result.”
Sendbird Enterprise Deployment: In production environments, Sendbird achieved “a 90% win rate without any prompt optimization” compared to 30% with competing models, enabling reliable AI customer support agents serving their 4,000+ global customers with over 7 billion monthly conversations.
Performance Metrics and Benchmarks
| Benchmark | Claude Opus 4.5 | GPT-5.1 | Gemini 3 Pro |
|---|---|---|---|
| SWE-bench Verified | 80.9% | 77.9% | 76.2% |
| Terminal-Bench 2.0 | 59.3% | 58.1% | 54.2% |
| AIME 2025 (with tools) | 100% | Not reported | 100% |
| MMMU (Visual Reasoning) | 80.7% | 85.4% | 81.0% |
| Aider Polyglot | 89.4% | — | — |
| Prompt Injection Resistance | 4.7% ASR | 21.9% ASR | 12.5% ASR |
The effort parameter introduces unprecedented efficiency control. At medium effort, Opus 4.5 matches Sonnet 4.5’s best SWE-bench score while using 76% fewer output tokens. At high effort, it exceeds Sonnet 4.5 by 4.3 percentage points while still consuming 48% fewer tokens.
Third-Party Validations
Independent benchmark organizations have documented Claude Opus 4.5’s capabilities:
ARC Prize Leaderboard: Opus 4.5 demonstrates significant advancement on ARC-AGI, achieving 58.7% on ARC-AGI-1 with 8K thinking budget and 13.9% on ARC-AGI-2, representing meaningful progress on tests designed to measure genuine generalization rather than memorization.
Vellum AI Analysis: Independent evaluation confirms “Claude Opus 4.5 demonstrates a clear lead in complex, real-world coding task” and represents “Anthropic’s most robustly aligned frontier model.”
DataCamp Assessment: Technical reviewers describe Opus 4.5 as “state-of-the-art on SWE-bench Verified, outperforming Google’s Gemini 3 Pro and OpenAI’s GPT-5.1.”
3. Technical Blueprint
System Architecture Overview
Claude Opus 4.5 employs a hybrid reasoning architecture that combines standard autoregressive generation with extended thinking capabilities. The model supports context windows up to 200,000 tokens and implements interleaved scratchpads for complex reasoning tasks.
Key architectural innovations include:
Extended Thinking Mode: The model can engage in deliberate, multi-step reasoning with configurable thinking budgets up to 128K tokens, allowing deeper analysis of complex problems.
Effort Parameter: A new API parameter (low/medium/high) enables developers to control the tradeoff between computational cost and reasoning depth, optimizing for specific use case requirements.
Context Management: Advanced memory and context compaction capabilities enable dramatically longer conversations and sustained multi-turn workflows without hitting context limits.
Multi-Agent Coordination: Opus 4.5 effectively manages teams of subagents, enabling construction of complex, well-coordinated multi-agent systems for sophisticated automation workflows.
API and SDK Integrations
Claude Opus 4.5 is accessible through multiple integration pathways:
Direct API Access: Available via the Claude API using model identifier claude-opus-4-5-20251101 with pricing at \$5 per million input tokens and \$25 per million output tokens.
Cloud Platform Availability: Deployed across all three major cloud providers—Amazon Web Services (Bedrock), Google Cloud Platform (Vertex AI), and Microsoft Azure (Foundry)—making Claude the only frontier model available on all three platforms.
Developer Tool Integration: Native support in GitHub Copilot (Pro, Pro+, Business, and Enterprise tiers), Cursor IDE, Windsurf, and Claude Code. Windsurf offers Opus 4.5 at promotional Sonnet pricing (2x credits versus 20x for Opus 4.1).
Enterprise Platforms: Integration with Microsoft 365 Copilot, Copilot Studio, and enterprise workflows through comprehensive SDK support.
Scalability and Reliability Data
Anthropic’s infrastructure commitment ensures production-grade availability:
Compute Partnership: Anthropic has committed to purchasing \$30 billion in Azure compute capacity, with additional capacity up to one gigawatt, ensuring scalability for enterprise workloads.
Batch Processing: API batch processing provides 50% cost reduction (\$2.50/\$12.50 per million tokens) for non-time-sensitive workloads.
Prompt Caching: Cache hits reduce input token costs to \$0.50 per million tokens, enabling significant cost optimization for repetitive context patterns.
4. Trust and Governance
Security Certifications
Anthropic maintains comprehensive security certifications for enterprise deployment:
SOC 2 Type II: Independent audit verification of security, availability, and confidentiality controls over extended operational periods. The SOC 2 detailed report is available under NDA for Enterprise customers, with a public SOC 3 summary accessible through Anthropic’s Trust Portal.
ISO 27001:2022: International standard certification for information security management systems.
ISO/IEC 42001:2023: Certification specifically addressing AI management systems and responsible AI development practices.
HIPAA Compliance: Attestation for healthcare applications requiring protected health information handling through the first-party API.
Data Privacy Measures
Privacy-protective architecture includes:
Zero Data Retention (ZDR): Enterprise customers can configure zero data retention agreements ensuring no conversation data persists beyond the immediate session.
Transit Encryption: All API communications employ industry-standard encryption protocols.
Custom Data Processing: Enterprise arrangements enable tailored data handling configurations meeting specific organizational requirements.
Audit Logging: Comprehensive logging framework supports SOX, Basel III, and other regulatory compliance requirements.
Regulatory Compliance Details
Claude Opus 4.5 operates under Anthropic’s ASL-3 (AI Safety Level 3) protections, representing enhanced safety precautions including classifier-based monitoring on top of conversations. The model demonstrates the strongest prompt injection resistance among frontier models, with only 4.7% attack success rate compared to 21.9% for GPT-5.1 and 12.5% for Gemini 3 Pro.
Anthropic’s Responsible Scaling Policy ensures systematic evaluation of model capabilities against defined safety thresholds, with ASL-4 requirements not yet triggered by current capability levels.
5. Unique Capabilities
Extended Thinking Architecture
The extended thinking capability enables Claude Opus 4.5 to engage in deliberate, multi-step reasoning before responding. Unlike simple chain-of-thought prompting, extended thinking allows the model to revise its reasoning, consider alternative approaches, and validate conclusions—resulting in significantly improved performance on complex problems.
On the 100Q Hard benchmark testing difficult question-answering, Opus 4.5 with thinking reaches approximately 46% correct rate while maintaining low uncertainty responses, suggesting more confident and accurate answers on challenging queries.
Multi-Agent Orchestration
Claude Opus 4.5 demonstrates exceptional capability in managing hierarchical agent systems. The model can coordinate multiple subagents, delegating tasks appropriately and synthesizing results into coherent outputs. This enables construction of sophisticated automation workflows where Opus 4.5 serves as an orchestrating “manager” directing specialized worker agents.
Anthropic’s testing indicates that combining context management, memory tools, and multi-agent coordination boosted performance on deep research evaluations by almost 15 percentage points.
Computer Use and Automation
The model advances Anthropic’s computer use capabilities, enabling interaction with graphical user interfaces, spreadsheets, browsers, and other applications. Enterprise users leverage this for:
Excel and Financial Modeling: Accuracy on internal evaluations improved 20%, efficiency rose 15%, with complex tasks “that once seemed out of reach became achievable.”
3D Visualization: Replicate reports that “Claude Opus 4.5 is the only model that nails some of our hardest 3D visualizations. Polished design, tasteful UX, and excellent planning \& orchestration.”
Browser Automation: Claude for Chrome enables task handling across browser tabs, now available to all Max users.
Effort-Controlled Reasoning
The effort parameter represents a significant innovation in model efficiency. Developers can specify reasoning intensity to optimize for their specific use case:
| Effort Level | SWE-bench Performance | Token Usage vs Sonnet 4.5 |
|---|---|---|
| Low | Baseline capability | Minimal tokens |
| Medium | Matches Sonnet 4.5 best | 76% fewer output tokens |
| High | Exceeds Sonnet 4.5 by 4.3% | 48% fewer output tokens |
This granular control enables significant cost optimization while maintaining quality for appropriate use cases.
6. Adoption Pathways
Integration Workflow
Developers can integrate Claude Opus 4.5 through multiple approaches:
Direct API Integration: Simply specify claude-opus-4-5-20251101 as the model parameter in API calls. Standard REST endpoints support synchronous and streaming responses.
Cloud Platform Deployment: Access through existing AWS Bedrock, Google Cloud Vertex AI, or Microsoft Azure Foundry accounts with enterprise security and compliance configurations already in place.
Development Tool Integration: Select Opus 4.5 from model pickers in GitHub Copilot, Cursor, Windsurf, or Claude Code for immediate coding assistance.
Consumer Applications: Claude.ai web application and mobile apps provide direct access with automatic context summarization for extended conversations.
Customization Options
Enterprise deployments support extensive customization:
System Prompts: Define model behavior, constraints, and persona characteristics for specific use cases.
Thinking Budget Configuration: Adjust the maximum tokens allocated to extended thinking based on task complexity requirements.
Tool Integration: Connect external tools and APIs through Anthropic’s tool use framework for domain-specific capabilities.
Memory Configuration: Enable or configure conversation memory to maintain context across sessions.
Onboarding and Support Channels
Anthropic provides multi-tier support:
Documentation: Comprehensive API documentation, system cards, and integration guides available through platform.claude.com.
Enterprise Sales: Dedicated sales and implementation support for organizations with significant deployment requirements.
Trust Portal: Access to security documentation, compliance artifacts, and audit reports.
Community Resources: Developer forums and GitHub discussions for technical implementation questions.
7. Use Case Portfolio
Enterprise Implementations
Claude Opus 4.5 powers diverse enterprise applications:
Financial Services: Financial modeling automation with 20% accuracy improvement. Risk analysis and regulatory document processing with enhanced precision.
Customer Support: Sendbird’s deployment handles high-volume support conversations across 4,000+ global customers, achieving 90% win rate on accuracy evaluations with automatic escalation for complex issues.
Software Development: GitHub Copilot integration accelerates professional development with reduced token usage. Code review at scale catches more issues without sacrificing precision.
Content Creation: Notion Agent integration produces “shareable content on the first try” with speed, token efficiency, and cost advantages enabling first-time Opus availability in Notion.
Long-Form Writing: NovelCrafter reports Opus 4.5 “excels at long-context storytelling, generating 10-15 page chapters with strong organization and consistency.”
Academic and Research Deployments
Research applications leverage Opus 4.5’s advanced reasoning:
Deep Research: The combination of effort control, context compaction, and advanced tool use enables research workflows with 15 percentage point performance improvements.
Mathematical Problem Solving: 100% accuracy on AIME 2025 when equipped with computational tools demonstrates graduate-level mathematical reasoning.
Scientific Document Analysis: Extended context windows support analysis of lengthy technical documents without information loss.
ROI Assessments
Enterprise customers document significant efficiency gains:
Token Efficiency: 50-65% reduction in token usage compared to previous models while maintaining or improving output quality.
Time Savings: Tasks requiring two hours with previous models complete in thirty minutes with Opus 4.5 according to Replicate’s testing.
Error Reduction: Builder.io reports “50% to 75% reductions in both tool calling errors and build/lint errors.”
Development Velocity: Complex tasks finish “in fewer iterations with more reliable execution,” reducing development cycles and human intervention requirements.
8. Balanced Analysis
Strengths with Evidential Support
Software Engineering Leadership: The 80.9% SWE-bench score demonstrates clear superiority in real-world software engineering tasks, with practical impact confirmed by multiple enterprise deployments.
Security and Alignment: Industry-leading prompt injection resistance (4.7% attack success rate) and 99.8% harmless response rate establish Claude Opus 4.5 as the safest frontier model for production deployment.
Cost Efficiency: Dramatic token efficiency improvements combined with the 66% price reduction from previous Opus models make advanced capabilities accessible to broader user bases.
Multi-Agent Capability: Superior coordination of complex, multi-step autonomous workflows enables sophisticated enterprise automation previously impractical with AI systems.
Reasoning Depth: Extended thinking architecture enables more thorough analysis and reduced errors on complex problems requiring deliberate reasoning.
Limitations and Mitigation Strategies
Multimodal Reasoning: GPT-5.1 demonstrates stronger performance on visual reasoning benchmarks (85.4% vs 80.7% on MMMU), suggesting Claude Opus 4.5 may be suboptimal for vision-heavy applications. Mitigation: Use specialized multimodal models for image-intensive tasks.
Not Immune to Manipulation: Despite industry-leading robustness, Anthropic explicitly acknowledges the model is “not completely immune to prompt injection” and recommends additional organizational safeguards for sensitive deployments.
Latency Considerations: Extended thinking mode introduces additional latency for complex reasoning tasks. The effort parameter allows optimization, but time-critical applications may benefit from lower effort settings.
Cost at Scale: While significantly reduced from previous Opus versions, the \$5/\$25 per million token pricing remains higher than lighter models. Batch processing and caching strategies can reduce costs for appropriate workloads.
Judgment Limitations: Despite superior technical performance, the model remains a statistical language model capable of errors and hallucinations. Human oversight remains essential for critical decisions in regulated domains.
9. Transparent Pricing
Plan Tiers and Cost Breakdown
| Usage Type | Input Tokens | Output Tokens | Notes |
|---|---|---|---|
| Standard API | \$5/MTok | \$25/MTok | 66% reduction from Opus 4.1 |
| Prompt Caching (Hits) | \$0.50/MTok | \$25/MTok | 90% input cost reduction |
| Batch Processing | \$2.50/MTok | \$12.50/MTok | 50% overall reduction |
| 5-minute Cache Writes | \$6.25/MTok | — | Short-term caching |
| 1-hour Cache Writes | \$10/MTok | — | Extended caching |
Consumer subscription options:
| Plan | Price | Features |
|---|---|---|
| Claude Pro | ~\$20/month | Enhanced Claude access |
| Claude Max | ~\$200/month | Premium features, no Opus-specific caps |
GitHub Copilot access: Available to Pro, Pro+, Business, and Enterprise users with promotional 1x premium request multiplier through December 5, 2025.
Total Cost of Ownership Projections
For enterprise deployments processing 10 million input tokens and 10 million output tokens daily:
| Optimization Strategy | Monthly Cost |
|---|---|
| Standard pricing | \$9,000 |
| With prompt caching (50% hit rate) | \$5,625 |
| Batch processing only | \$4,500 |
| Combined optimization | \$2,812 |
The dramatic cost reduction enables use cases previously cost-prohibitive. Organizations report that Opus 4.5’s efficiency—achieving better results with fewer tokens—often results in lower actual costs despite premium pricing compared to lighter models.
10. Market Positioning
Competitor Comparison
| Capability | Claude Opus 4.5 | GPT-5.1 | Gemini 3 Pro |
|---|---|---|---|
| SWE-bench Verified | 80.9% (Leader) | 77.9% | 76.2% |
| Terminal-Bench 2.0 | 59.3% (Leader) | 58.1% | 54.2% |
| MMMU Visual | 80.7% | 85.4% (Leader) | 81.0% |
| Prompt Injection Resistance | 4.7% ASR (Leader) | 21.9% ASR | 12.5% ASR |
| Input Price (MTok) | \$5 | \$1.25 | ~\$2 |
| Output Price (MTok) | \$25 | \$10 | ~\$12 |
| Max Context | 200K | 128K | 1M |
| Extended Thinking | Yes | Limited | DeepThink mode |
| Computer Use | Yes | Limited | Yes |
| Cloud Availability | AWS/GCP/Azure | Azure | GCP |
Unique Differentiators
Only Model on All Major Clouds: Claude is the sole frontier model available across AWS, Google Cloud, and Microsoft Azure, providing maximum deployment flexibility.
Safety-First Architecture: Constitutional AI training combined with industry-leading prompt injection resistance makes Claude optimal for enterprise applications requiring trustworthy AI behavior.
Coding Benchmark Leadership: Consistent superiority across SWE-bench, Terminal-Bench, and Aider Polyglot establishes Claude Opus 4.5 as the premier choice for software engineering applications.
Effort Control Innovation: Unique ability to tune reasoning depth enables cost-quality optimization impossible with competing models.
Enterprise Security Stack: Comprehensive SOC 2 Type II, ISO 27001, and HIPAA certifications with zero data retention options support regulated industry deployments.
11. Leadership Profile
Bios Highlighting Expertise and Awards
Dario Amodei (Co-Founder and CEO)
Dario Amodei holds a PhD in Computational Neuroscience from Princeton University and brings extensive experience from leadership positions at the forefront of AI development. Before founding Anthropic, he served as Vice President of Research at OpenAI, where he led development of GPT-2 and GPT-3. He previously worked as Senior Research Scientist at Google Brain and conducted research at Baidu.
Amodei is co-inventor of Reinforcement Learning from Human Feedback (RLHF), the technique powering conversational AI systems including ChatGPT and Claude. He has been recognized on TIME’s 100 Most Influential People in AI 2025 list. His published work spans deep learning scaling laws, AI safety methodology, and responsible AI development.
Daniela Amodei (Co-Founder and President)
Daniela Amodei drives Anthropic’s strategic direction and operational excellence. Her diverse career includes significant roles at OpenAI in AI safety and policy, as well as risk management positions at Stripe. She brings expertise in scaling technology organizations while maintaining focus on responsible development practices.
Jack Clark (Co-Founder and Head of Policy)
Jack Clark shapes Anthropic’s strategic initiatives and policy direction. Before co-founding Anthropic, he served as Policy Director and Strategy \& Communications lead at OpenAI. His background includes technology journalism at Bloomberg LP and The Register, providing unique perspective on AI policy and industry communications.
Sam McCandlish (Co-Founder and Chief Technology Officer)
Sam McCandlish oversees Anthropic’s Large Language Model organization encompassing Training, Inference, and Core Resources divisions. He serves as Responsible Scaling Officer, helping design and implement Anthropic’s responsible scaling policy.
Research Publications
Anthropic’s research team has published extensively on AI safety and capabilities:
Scaling Laws: Foundational work establishing relationships between model size, data, and performance that guide modern AI development.
Constitutional AI: Novel training methodology that imbues models with ethical principles, reducing harmful outputs while maintaining helpfulness.
Interpretability Research: Ongoing work on understanding internal model representations and decision-making processes.
System Cards: Comprehensive technical documentation including the Claude Opus 4.5 System Card detailing capability evaluations, safety testing, and operational parameters.
12. Community and Endorsements
Industry Partnerships
Microsoft Partnership: Microsoft has committed to investing up to \$5 billion in Anthropic as part of a strategic partnership making Claude available across Microsoft’s Copilot family including GitHub Copilot, Microsoft 365 Copilot, and Copilot Studio.
NVIDIA Partnership: NVIDIA will invest up to \$10 billion in Anthropic while collaborating on design and development to optimize Anthropic AI models for NVIDIA architecture.
Amazon Partnership: Amazon remains Anthropic’s primary cloud provider and training partner, with Claude deeply integrated into AWS Bedrock services.
Google Cloud: Claude Opus 4.5 is generally available on Google Cloud’s Vertex AI platform with Model Armor protection against prompt injection and tool poisoning.
Media Mentions and Awards
TIME Recognition: CEO Dario Amodei named to TIME’s 100 Most Influential People in AI 2025.
Enterprise Validation: Featured deployments at major technology companies including GitHub, Cursor, Windsurf, Notion, Replicate, Builder.io, and hundreds of enterprise customers.
Industry Coverage: Extensive coverage from TechCrunch, Reuters, The Information, and major technology publications documenting Anthropic’s rapid growth and technical achievements.
Government Adoption: Anthropic announced offerings to the U.S. government and plans for expanded international presence including India operations.
13. Strategic Outlook
Future Roadmap and Innovations
Anthropic’s trajectory suggests continued advancement across multiple dimensions:
Capability Scaling: The company’s demonstrated ability to improve model performance while reducing costs indicates continued capability gains in future releases.
Industry-Specific Products: Expansion of Claude for Financial Services and similar vertical solutions targeting regulated industries with specific compliance requirements.
Enterprise Features: Enhanced search capabilities, workflow automation, and deeper integration with enterprise application ecosystems.
Safety Research: Ongoing investment in interpretability, alignment, and responsible scaling to maintain safety leadership as capabilities increase.
International Expansion: Plans for Bengaluru, India office and tripling of international workforce to meet growing global demand.
Market Trends and Recommendations
The AI industry demonstrates several trends relevant to Claude Opus 4.5 adoption:
Enterprise AI Acceleration: Approximately 80% of Anthropic’s revenue comes from enterprise customers, reflecting broader industry movement toward production AI deployment.
Developer Tool Integration: The proliferation of Claude integrations in coding tools (GitHub Copilot, Cursor, Windsurf) indicates AI-assisted development becoming standard practice.
Multi-Cloud Strategy: Claude’s unique availability across all three major cloud platforms positions it favorably as enterprises pursue multi-cloud AI strategies.
Safety-First Differentiation: Increasing enterprise focus on AI governance and risk management favors models with demonstrated safety profiles and compliance certifications.
Recommendations:
- Organizations requiring best-in-class software engineering capabilities should prioritize Claude Opus 4.5 given its benchmark leadership.
- Enterprise deployments in regulated industries should leverage Anthropic’s comprehensive security certifications and zero data retention options.
- Cost-conscious deployments should implement prompt caching and batch processing strategies to optimize expenses.
- Multi-modal applications requiring strong visual reasoning may benefit from complementing Claude with specialized vision models.
- Developers should utilize the effort parameter to optimize cost-quality tradeoffs for specific use cases.
Final Thoughts
Claude Opus 4.5 represents a significant milestone in AI capability development, establishing clear leadership in software engineering tasks while maintaining what Anthropic credibly claims as the strongest safety profile among frontier models. The combination of benchmark-leading performance, dramatically reduced pricing, and comprehensive enterprise security features positions Opus 4.5 as a compelling choice for organizations seeking production-grade AI capabilities.
The model’s software engineering superiority—demonstrated by the first-ever 80%+ score on SWE-bench Verified—has immediate practical implications for development teams. Early adopter testimonials consistently describe meaningful productivity gains, reduced iteration cycles, and improved code quality. The integration across major development tools (GitHub Copilot, Cursor, Windsurf) ensures accessible deployment for diverse technical workflows.
Anthropic’s safety-first approach, while occasionally criticized as overly cautious, provides meaningful differentiation for enterprise buyers navigating AI governance requirements. The 4.7% prompt injection attack success rate—compared to 21.9% for GPT-5.1—represents a substantial security advantage for applications where AI reliability directly impacts business operations.
The pricing restructuring deserves recognition as strategically significant. The 66% reduction from previous Opus models, combined with effort parameter control and batch/caching optimizations, makes frontier-level AI economically viable for use cases previously constrained to lighter models. This democratization of advanced capabilities may accelerate broader AI adoption across industries.
Anthropic’s extraordinary growth trajectory—from \$1 billion to \$5 billion ARR in eight months—validates market demand for Claude’s combination of capability and safety. The projected path toward \$26 billion ARR by 2026 and potential \$70 billion revenue by 2028 suggests sustained enterprise confidence in Anthropic’s approach.
For organizations evaluating frontier AI models, Claude Opus 4.5 merits serious consideration particularly for software engineering automation, complex reasoning tasks, and applications requiring demonstrable safety profiles. The model’s limitations—including slightly weaker multimodal visual reasoning compared to competitors—are well-documented and addressable through complementary tool selection.
The broader implication of Claude Opus 4.5’s capabilities extends beyond immediate commercial applications. Anthropic’s demonstration that AI models can surpass human expert performance on challenging technical tasks while maintaining robust safety characteristics suggests a path toward beneficial AI development that balances capability advancement with responsible deployment practices. This balance may prove as valuable as the raw performance metrics as AI systems assume increasingly consequential roles in organizational operations.