
Table of Contents
Overview
In the rapidly evolving field of artificial intelligence, efficiently processing lengthy documents and extracting text from complex layouts remains a significant technical challenge. DeepSeek-OCR represents a novel approach to this problem by introducing an innovative optical compression methodology that treats textual content as visual data. Released in October 2025 by DeepSeek AI, this open-source model demonstrates how visual token compression can enable more efficient document processing, potentially setting new benchmarks for computational efficiency in optical character recognition tasks.
Key Features
DeepSeek-OCR introduces several distinctive capabilities that differentiate it from conventional OCR approaches:
Visual Compression Architecture: The model employs a unique methodology that converts extensive text into compressed visual representations, enabling substantially more efficient processing of lengthy documents compared to traditional token-based approaches.
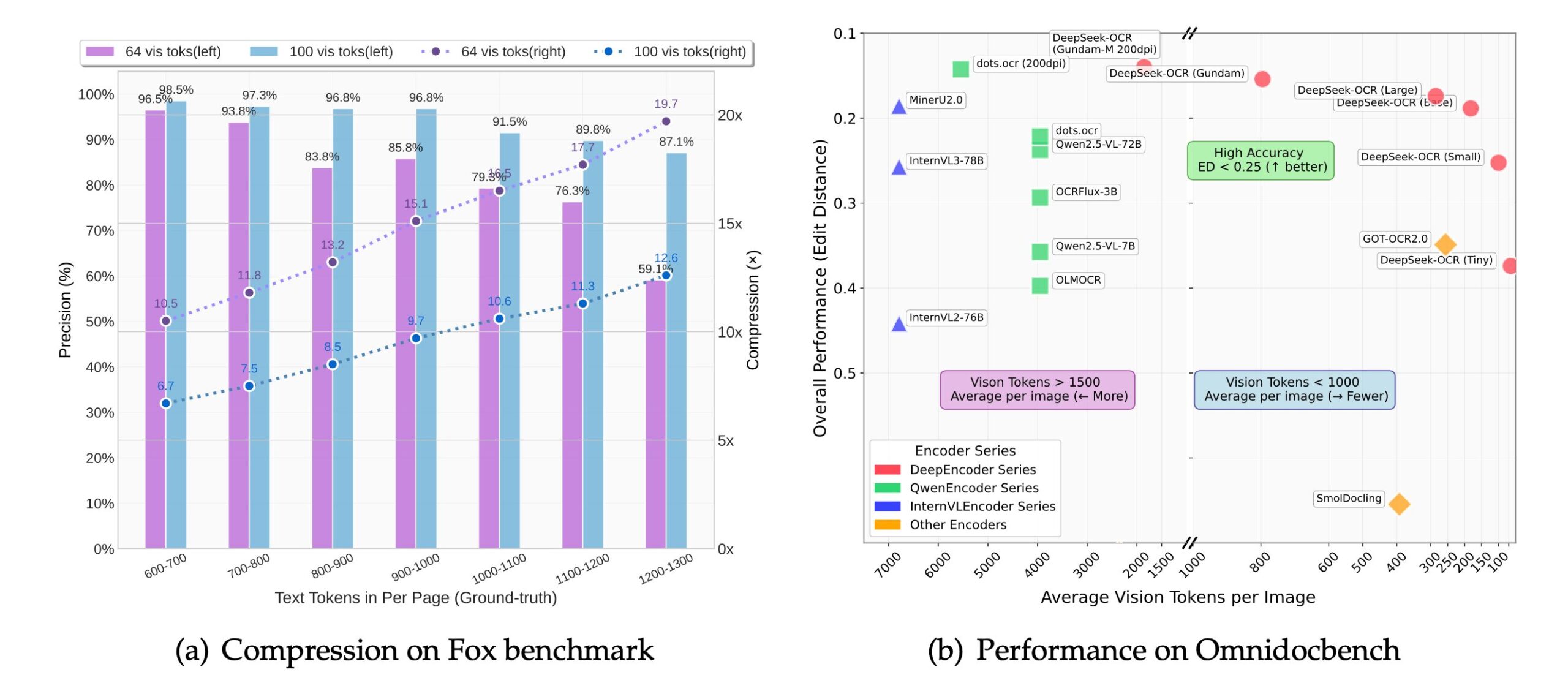
Variable Compression Ratios: The system supports multiple compression configurations, ranging from 7× to 20× compression. At compression ratios below 10×, the model maintains approximately 97% decoding accuracy, while even at 20× compression, it preserves roughly 60% accuracy, offering flexibility based on use-case requirements.
Dual-Component Design: The architecture consists of DeepEncoder, a 380-million-parameter vision module optimized for image processing, combined with a DeepSeek3B-MoE language decoder featuring 570 million active parameters, creating an efficient end-to-end system.
Open-Source Accessibility: Released under the MIT License, the complete model weights, training code, and technical documentation are publicly available on GitHub and Hugging Face, fostering transparency and enabling community-driven development.
High-Throughput Processing: The system demonstrates the capability to process over 200,000 document pages per day on a single NVIDIA A100-40G GPU, making it suitable for large-scale document digitization projects.
How It Works
DeepSeek-OCR fundamentally reimagines document processing by treating text as two-dimensional visual information rather than sequential tokens. The system employs a two-stage pipeline: First, the DeepEncoder converts document images into highly compressed visual tokens through a sophisticated encoding process that leverages SAM-based segmentation and CLIP-inspired global context understanding, combined with a 16× convolutional compressor. This compression dramatically reduces the representation size—for example, a 1024×1024 resolution page typically requiring thousands of text tokens can be compressed to approximately 256 vision tokens.
In the second stage, the DeepSeek3B-MoE decoder, a Mixture-of-Experts language model with approximately 570 million active parameters, reconstructs and interprets this compressed visual information. This architecture enables the model to process substantially longer documents within the context window limitations of modern language models while maintaining high fidelity in text recognition and layout understanding.
Use Cases
The unique compression-first approach of DeepSeek-OCR enables several practical applications across various domains:
Large-Scale Document Digitization: Organizations can efficiently convert extensive archives of physical documents into searchable digital formats, with the system’s high throughput making it viable for processing millions of pages.
Training Data Generation for Large Language Models: The model’s ability to compress lengthy texts makes it particularly valuable for preparing large-scale training datasets for LLMs, potentially reducing both storage requirements and computational costs during model training.
Enterprise Document Processing: Businesses can leverage the system for processing high volumes of invoices, contracts, forms, and other structured documents while maintaining cost-efficiency through its reduced token requirements.
Academic and Research Applications: Researchers working with extensive document collections, historical archives, or scientific literature can benefit from the model’s ability to handle complex layouts, mathematical formulas, tables, and multilingual content.
Pros \& Cons
Advantages
High Compression Efficiency: The model achieves token compression ratios of 7-20×, significantly reducing computational overhead and enabling processing of longer documents within fixed context windows.
Open-Source and Transparent: Complete availability of model weights, code, and technical documentation under the MIT License encourages reproducibility, community contributions, and customization for specific use cases.
Cost-Effective Processing: Demonstrated high throughput on standard GPU hardware makes large-scale document processing economically feasible for organizations with budget constraints.
Benchmark Performance: On the OmniDocBench evaluation, DeepSeek-OCR surpasses GOT-OCR2.0 while utilizing only 100 vision tokens per page compared to 256, and outperforms MinerU2.0 while using fewer than 800 tokens versus approximately 6,000+ tokens per page.
Disadvantages
Limited Independent Validation: As a recently released model, comprehensive third-party evaluations and real-world deployment case studies are still emerging, making it challenging to fully assess performance across diverse document types.
Compression-Accuracy Trade-offs: While high compression ratios enable efficient processing, they come with accuracy penalties—particularly at 20× compression where accuracy drops to approximately 60%, which may be insufficient for precision-critical applications.
Specialized Hardware Requirements: Although efficient relative to some alternatives, the model still requires GPU acceleration for optimal performance, potentially limiting accessibility for users with only CPU-based infrastructure.
How Does It Compare?
The document parsing and OCR landscape in October 2025 features several strong competitors, each with distinct architectural approaches and specializations:
PaddleOCR-VL-0.9B: Released by Baidu in October 2025, this ultra-compact vision-language model achieved state-of-the-art performance on OmniDocBench V1.5 while utilizing only 0.9 billion parameters. PaddleOCR-VL integrates a NaViT-style dynamic resolution encoder with the ERNIE-4.5-0.3B language model, supporting 109 languages and excelling in complex element recognition including tables, formulas, and charts. It demonstrates competitive performance against substantially larger models while maintaining exceptional computational efficiency. The model represents significant advancement over traditional PaddleOCR approaches and currently leads in the document parsing domain.
MinerU2.5: Released in September 2025, this 1.2-billion-parameter model employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. MinerU2.5 achieves state-of-the-art performance on multiple benchmarks while maintaining significantly lower computational overhead than general-purpose VLMs. The model excels particularly in handling rotated tables, borderless structures, and complex formulas, with peak throughput exceeding 10,000 tokens per second on a single NVIDIA 4090 through sglang acceleration.
Ocean-OCR: Introduced in January 2025, this 3-billion-parameter multimodal large language model employs Native Resolution ViT to enable variable resolution input. Ocean-OCR represents the first MLLM to outperform professional OCR models such as TextIn and PaddleOCR in comprehensive evaluations, demonstrating strong capabilities across document understanding, scene text recognition, and handwritten text scenarios.
GOT-OCR2.0: A 580-million-parameter end-to-end model from 2024 that handles diverse OCR tasks through a unified architecture. While still widely referenced, it has been surpassed by newer models in both accuracy and efficiency metrics on current benchmarks.
DeepSeek-OCR distinguishes itself primarily through its novel optical compression methodology, which positions it as a specialized solution for scenarios requiring extreme token efficiency and long-context processing. Unlike models focused on maximizing raw accuracy, DeepSeek-OCR prioritizes the compression-efficiency trade-off, making it particularly suitable for applications involving massive document volumes where processing speed and computational cost are critical constraints. However, in terms of pure accuracy and comprehensive document understanding capabilities, models like PaddleOCR-VL-0.9B currently lead the field according to the latest benchmark results.
Final Thoughts
DeepSeek-OCR introduces an intriguing alternative paradigm for document processing through its visual compression approach, potentially offering valuable efficiency gains for specific large-scale applications. The model’s open-source nature, combined with its demonstrated capability to process hundreds of thousands of pages daily on standard GPU hardware, makes it an accessible option for researchers and organizations exploring cost-effective document digitization solutions.
However, potential users should carefully evaluate whether the model’s compression-oriented design aligns with their accuracy requirements, particularly for applications where precision is paramount. The rapidly evolving document AI landscape, with recent releases from PaddleOCR-VL, MinerU2.5, and other competitors, suggests that organizations should conduct thorough benchmarking against current state-of-the-art alternatives before committing to a specific solution. As independent validations and real-world deployment studies emerge over the coming months, a clearer picture of DeepSeek-OCR’s practical strengths and limitations will develop, enabling more informed adoption decisions across different use cases.