Table of Contents
Overview
In the rapidly evolving landscape of AI development, access to high-performance computing resources frequently becomes the primary bottleneck constraining innovation and research progress. Traditional GPU procurement involves lengthy approval processes, extensive waitlists, and rigid long-term contractual commitments that can significantly impede project timelines. Exla FLOPs addresses these industry challenges by providing on-demand GPU cluster infrastructure that enables immediate access to substantial computing resources. The platform specializes in delivering large-scale GPU deployments ranging from 64 to 128+ GPUs without traditional barriers, positioning itself as a streamlined solution for organizations requiring immediate, flexible access to high-performance computing infrastructure.
Key Features
Exla FLOPs differentiates itself through features specifically designed to address the computational demands of modern AI and machine learning workloads.
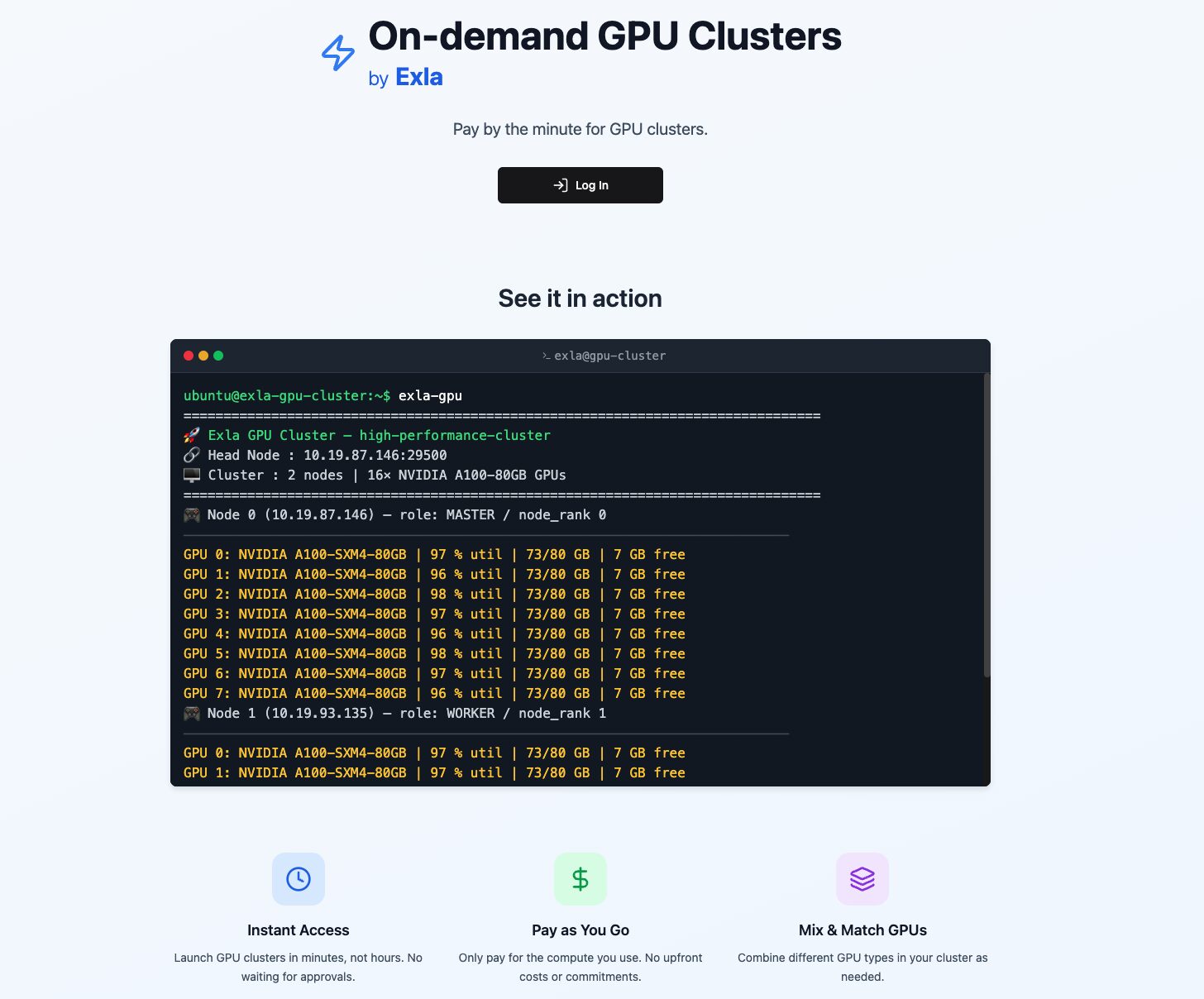
- Instant GPU provisioning: Provides immediate access to high-performance GPU resources without traditional approval processes or extended waiting periods, enabling rapid project initiation and iteration.
- Scalable cluster configurations: Supports flexible deployment options ranging from 64 to 128+ GPUs, accommodating diverse computational requirements from research experiments to large-scale production workloads.
- Flexible commitment structure: Operates on a pay-as-you-go model without requiring long-term contractual obligations, allowing organizations to scale resources dynamically based on project needs.
- High computational flexibility: Enables precise resource allocation tailored to specific project requirements, supporting both burst computing needs and sustained high-performance workloads.
- Dynamic resource scaling: Facilitates seamless expansion or reduction of GPU capacity as computational demands evolve, ensuring cost-effective resource utilization.
How It Works
Exla FLOPs operates through a streamlined cloud infrastructure designed to eliminate traditional GPU access barriers. The platform provides users with intuitive access through both web-based interfaces and programmatic APIs, enabling rapid cluster deployment and management. Users can specify their required GPU count and configuration parameters, with the system automatically provisioning the requested resources from available inventory. The service dynamically sources GPU capacity across multiple providers and data centers, ensuring availability even during periods of high demand. This distributed approach allows the platform to offer consistent access to large-scale GPU clusters while maintaining competitive pricing and deployment speed.
Use Cases
The immediate availability and scalable architecture of Exla FLOPs enable diverse applications across multiple computational domains requiring substantial GPU resources.
- Large-scale AI model training: Accelerates development of sophisticated neural networks, large language models, and complex computer vision systems through massive parallel processing capabilities that significantly reduce training timeframes.
- Scientific and engineering simulations: Supports computationally intensive research applications including fluid dynamics modeling, molecular simulations, climate modeling, and other scientific computing tasks requiring substantial computational power.
- High-performance computing workloads: Enables advanced HPC applications that benefit from large GPU clusters, including numerical analysis, optimization problems, and parallel computing tasks requiring coordinated multi-GPU processing.
- Real-time rendering and visualization: Powers high-fidelity rendering applications for film production, architectural visualization, game development, and interactive media requiring immediate access to substantial graphics processing power.
- Research and development computing: Provides academic institutions and research organizations with the computational infrastructure necessary for advanced research projects without requiring significant capital investment in hardware.
Pros \& Cons
Exla FLOPs offers distinct advantages while maintaining transparency about service limitations and considerations.
Advantages
- Immediate resource availability: Eliminates traditional waiting periods and approval processes, enabling instant access to substantial GPU computing power for time-sensitive projects and dynamic research needs.
- Flexible scaling capabilities: Provides seamless resource adjustment options, allowing organizations to optimize costs by scaling GPU resources precisely to match computational requirements.
- Commitment-free accessibility: Removes the financial risk and inflexibility associated with long-term hardware purchases or extended cloud commitments, particularly beneficial for project-based computing needs.
- Cost transparency: Offers clear pricing models that enable accurate project budgeting and cost management, though specific rates require direct consultation with the service provider.
- Enterprise-grade hardware access: Provides access to cutting-edge GPU technology including H100 and A100 processors without requiring substantial capital investment in hardware acquisition and maintenance.
Disadvantages
- Premium pricing for large-scale deployments: Extended use of substantial GPU clusters may result in significant operational costs, particularly for sustained production workloads requiring continuous resource allocation.
- Potential geographic limitations: As a specialized service provider, data center presence may be concentrated in specific regions, potentially affecting latency and data sovereignty requirements for some users.
- Focused service scope: Concentrates primarily on GPU cluster provisioning rather than providing comprehensive cloud ecosystem services, which may require integration with additional providers for complete infrastructure needs.
How Does It Compare?
When evaluated against the current competitive landscape, Exla FLOPs operates within a dynamic market of specialized GPU cloud providers, each offering distinct advantages for different use cases.
Together AI Instant GPU Clusters represents a significant competitor, offering up to 64 NVIDIA H100 SXM GPUs with immediate deployment capabilities. Together AI provides enterprise-grade infrastructure with NVIDIA Quantum-2 InfiniBand and NVLink networking, priced at approximately \$3.19 per GPU hour for on-demand usage. Their service includes comprehensive orchestration options with Kubernetes and Slurm support, making it particularly suitable for organizations requiring both immediate access and advanced cluster management capabilities.
Lambda Labs has established itself as a prominent player in the AI-focused cloud GPU market, offering competitive H100 pricing ranging from \$2.49 to \$2.99 per GPU hour. Lambda Labs provides 1-Click Clusters supporting 16 to 1,500+ GPUs with rapid deployment capabilities. Their platform includes pre-installed machine learning frameworks and specialized AI development tools, positioning them as a comprehensive solution for machine learning workflows. Lambda Labs offers both on-demand and reserved pricing options, providing flexibility for different usage patterns.
RunPod delivers cost-effective GPU access with H100 pricing ranging from \$1.99 to \$2.99 per GPU hour, making it one of the more budget-friendly options in the market. RunPod operates both Community Cloud and Secure Cloud infrastructure, supporting large-scale multi-GPU configurations while maintaining competitive pricing. Their platform provides container-based deployment and serverless options, appealing to developers seeking both flexibility and cost efficiency.
CoreWeave focuses on enterprise-grade GPU infrastructure with sophisticated Kubernetes-based orchestration and high-performance networking. As a specialized GPU cloud provider, CoreWeave offers customizable cluster configurations and advanced networking capabilities, particularly suited for large-scale enterprise deployments. Their infrastructure supports complex multi-tenant environments and provides detailed resource management capabilities.
NVIDIA DGX Cloud provides premium AI infrastructure with H100-based instances starting at \$36,999 per month per instance (8 GPUs), offering comprehensive software stack integration and expert support. While significantly more expensive, DGX Cloud provides enterprise-grade reliability and NVIDIA’s complete AI development ecosystem.
Exla FLOPs differentiates itself by emphasizing rapid large-scale cluster deployment and flexible resource sourcing across multiple providers. This approach potentially offers advantages in availability during high-demand periods, though specific performance and pricing comparisons require direct evaluation based on individual project requirements.
Final Thoughts
Exla FLOPs addresses genuine challenges in the GPU cloud computing market by focusing on immediate access to large-scale computing resources without traditional procurement barriers. The service provides valuable flexibility for organizations requiring substantial computational power on demand, particularly those working with time-sensitive research projects or dynamic development cycles. While operating in an increasingly competitive market alongside established providers like Together AI, Lambda Labs, and CoreWeave, Exla FLOPs contributes to the broader trend toward more accessible, flexible GPU computing infrastructure. Organizations evaluating GPU cloud services should consider factors including pricing, performance requirements, geographic considerations, and integration needs when selecting the most appropriate provider for their specific computational demands. The continued evolution of this market benefits users through improved availability, competitive pricing, and enhanced service capabilities across all providers.