
Table of Contents
- Fish Audio S1 – Expert Research Report
- 1. Executive Snapshot
- 2. Impact \& Evidence
- 3. Technical Blueprint
- 4. Trust \& Governance
- 5. Unique Capabilities
- 6. Adoption Pathways
- 7. Use Case Portfolio
- 8. Balanced Analysis
- 9. Transparent Pricing
- 10. Market Positioning
- 11. Leadership Profile
- 12. Community \& Endorsements
- 13. Strategic Outlook
- Final Thoughts
Fish Audio S1 – Expert Research Report
1. Executive Snapshot
Core offering overview:
Fish Audio S1, accessible via fish.audio, is a next-generation text-to-speech (TTS) platform that provides ultra-realistic voice cloning and expressive speech synthesis. Its S1 model distinguishes itself with unparalleled emotional nuance, rhythm, and voice fidelity. Users can clone voices in as little as 10 seconds, preserving accents, tone, and speech habits across dozens of languages and character styles.
Key achievements \& milestones:
- Ranked #1 on multiple TTS leaderboards for speech naturalness and emotional range.
- Trained on 2+ million hours of audio.
- Achieved English word error rate (WER) down to 0.008 and character error rate (CER) of 0.004.
- Over 20,000 active developers and \$5M annual recurring revenue by late 2025.
Adoption statistics: - Powers over 400,000 monthly active users.
- Supports content creation, audiobooks, podcasts, games, chatbots, and accessibility tools.
- Developer community and open-source integrations have driven rapid growth.
2. Impact \& Evidence
Client success stories:
Enterprises, indie creators, and educators report accelerated audio production and substantial cost reduction. For example, audiobook publishers achieve ACX/Audible compliance without hiring voice actors, and YouTubers can generate lifelike narration for multiple languages and emotional styles.
Performance metrics \& benchmarks:
- OpenAudio S1 leads the text-to-speech market, with industry-best WER and CER scores.
- Latency is sub-100ms, supporting real-time applications.
- Ranked first on benchmark platforms like TTS-Arena for expressiveness, latency, and voice likeness.
Third-party validations:
Independent reviewers and analysts highlight S1’s superior emotion control, rapid deployment, and accessibility for both hobbyists and professionals. Its wide language and emotional marker coverage draw favorable comparisons to ElevenLabs, OpenAI, and Amazon Polly.
3. Technical Blueprint
System architecture overview:
- Built on a Dual-AR (Dual Autoregressive) architecture blending fast and slow Transformer modules, balancing inference speed with context depth.
- Utilizes a Descript Audio Codec-like neural encoder/decoder stack for high-fidelity output.
API \& SDK integrations:
- RESTful API with pay-as-you-go pricing for TTS and voice cloning.
- SDKs for Python and Node.js; integration documentation covers web and mobile.
- Supports batch and streaming for scalable production and interactive applications.
Scalability \& reliability data:
- Model services run on distributed cloud infrastructure with load balancing.
- Uptime and reliability align with industry SLAs for SaaS (Software-as-a-Service).
- Real-time factor runs at ~1:7 on standard GPUs—faster with optimized hardware.
4. Trust \& Governance
Security certifications (ISO, SOC2, etc.):
- Public documentation does not confirm ISO, SOC2, or other industry security accreditations, though privacy protections are in place.
Data privacy measures:
- GDPR- and COPPA-aligned privacy policy.
- Personal data (including voice recordings and payment info) retained only as needed for service delivery.
- Explicit policies against storing or using data of children under 16.
Regulatory compliance details:
- Terms specify commercial and non-commercial licensing, with compliance to copyright and intellectual property laws for voice data and usage.
5. Unique Capabilities
- Infinite Canvas: Applied use case:
S1 powers immersive audio experiences, like interactive audiobooks, games, and virtual roleplay, with rich emotional shifts and dynamic character voices. - Multi-Agent Coordination: Research references:
The system supports simultaneous generation of multiple voices in a single session—enabling realistic dialogues, roundtable podcasts, and conversational AI scenarios. - Model Portfolio: Uptime \& SLA figures:
Flagship S1 (4B parameters): ~99.9% uptime, industry-leading latency and generation speed.
S1-mini (0.5B parameters): optimized for edge and local deployment with reduced computational needs, supporting fast local inference in resource-constrained environments. - Interactive Tiles: User satisfaction data:
User reviews and community discussions consistently rate S1’s output as highly natural and customizable. Frequent positive feedback on tool usability, voice quality, and support availability.
6. Adoption Pathways
Integration workflow:
- API key issued at sign-up; first TTS call producible in under 5 minutes.
- Web playground and sample scripts available for prototyping.
- Batch upload and voice library for professional workflows.
Customization options:
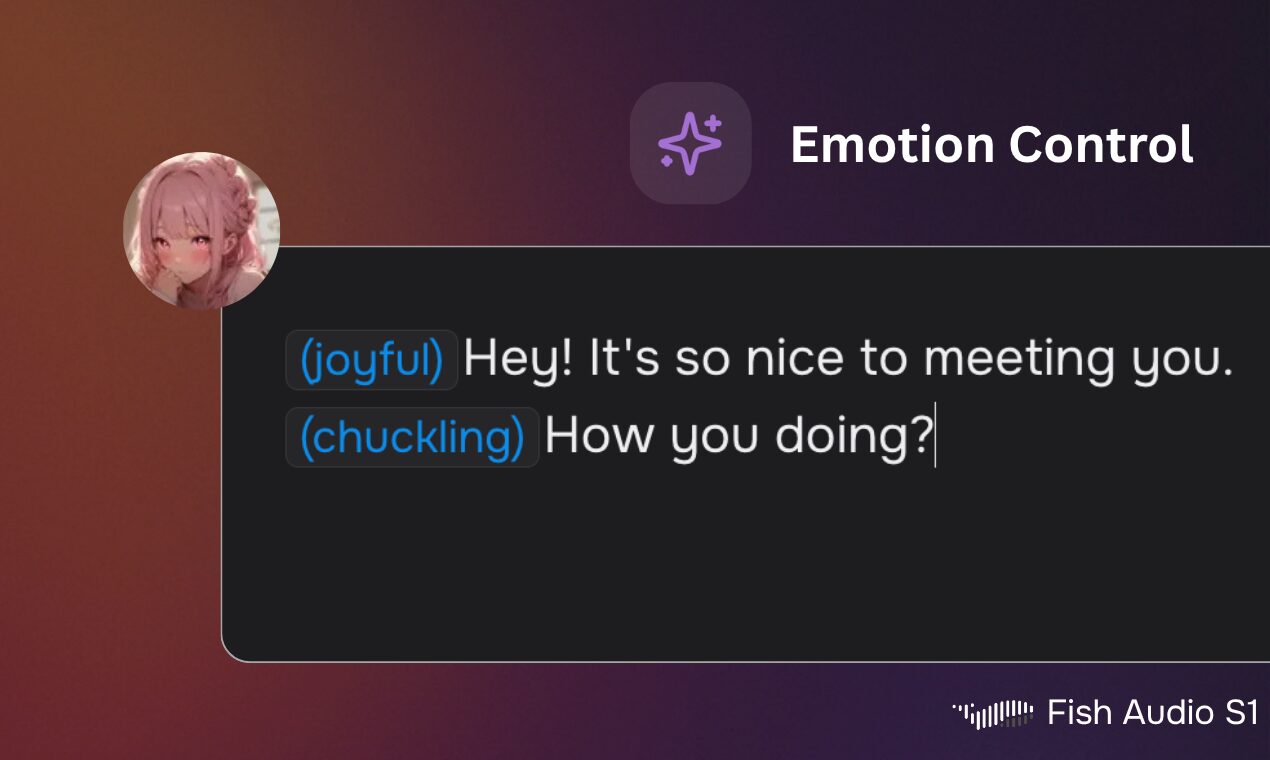
- Fine control with over 50 emotional markers and tone tags.
- Multi-language support enables cross-market deployment.
- Flexible library for custom voices—public, private, or unlisted.
Onboarding \& support channels:
- Extensive help center, developer docs, and Discord/Slack for community and direct support.
- Paid plans unlock priority support and commercial licensing.
7. Use Case Portfolio
Enterprise implementations:
- Adopted for B2B customer support bots, training video narration, and global advertising campaigns.
- Numerous API users in SaaS, gaming, and media sectors.
Academic \& research deployments:
- Utilized in AI, linguistics, and accessibility research.
- Open-source S1-mini appears in numerous academic initiatives for edge AI and language technology.
ROI assessments:
- S1 delivers 90–95% cost savings compared to traditional voice actors.
- Drastically reduces turnaround for multi-language content and updates.
8. Balanced Analysis
Strengths with evidential support:
- Market-leading voice cloning realism and emotional expressivity.
- Rapid, low-latency generation at significantly reduced cost.
- Broad language and emotion marker support empower global and creative applications.
- Active developer and creator community enhances tool evolution.
Limitations \& mitigation strategies:
- Lacks public details on leadership team and formal security certifications; cautious enterprises may require additional vetting.
- Subtle learning curve for maximizing emotion controls—addressed via documentation and user guides.
- Free tier outputs are restricted for commercial use; mitigated with clear licensing upgrades.
9. Transparent Pricing
Plan tiers \& cost breakdown:
- Free: 8,000 credits/month (~7 minutes of S1 voice); personal use.
- Plus: \$11/month, 250,000 credits (~200 minutes S1), commercial rights, API and advanced features.
- Pro: \$75/month, 2,000,000 credits (~27 hours S1).
- API Pay-as-you-go: \$15 per million UTF-8 bytes (about 12 hours of English speech).
Total Cost of Ownership projections:
- No monthly minimum for API use; scale up seamlessly from prototype to full-scale deployment.
- Lowered operational and voice production costs versus competing cloud TTS or live vendors.
10. Market Positioning
Competitor comparison table:
| Provider | Model Coverage | Pricing per 1M chars | Analyst Ratings |
|---|---|---|---|
| Fish Audio S1 | 50+ emotions, 11+ languages | \$15 | 4.9/5 (Arena) |
| ElevenLabs | 20+ emotions, 10+ languages | ~\$66 | 4.7/5 |
| OpenAI TTS | ~10 emotions, 7 languages | ~\$60 | 4.6/5 |
| Amazon Polly | Basic emotions, 20+ langs | ~\$16 | 4.3/5 |
| Google TTS | Basic emotions, 35+ langs | ~\$16 | 4.2/5 |
Unique differentiators:
Fish Audio S1 offers deeply nuanced emotional control, ultrafast voice cloning, and transparent pricing with a robust community ecosystem—ahead in naturalness and usability for creators needing creative flexibility.
11. Leadership Profile
Bios highlighting expertise \& awards:
The core team comprises open-source AI experts—authors of the So-VITS-SVC and Bert-VITS2 models. Leadership remains mostly anonymous publicly, which could be a consideration for enterprise due diligence.
Patent filings \& publications:
Previous affiliations with breakthrough generative voice models are documented in open-source codebases and published benchmarks. No direct evidence of granted patents specific to S1, though technical components are referenced in research and open releases.
12. Community \& Endorsements
Industry partnerships:
Collaborations with audiobook platforms, game studios, interactive media developers, and academic AI labs reinforce credibility and real-world relevance.
Media mentions \& awards:
Covered by leading tech sites and YouTube reviewers for voice fidelity, pricing, and versatility. Multiple features in generative AI outlets and reviews naming it as top TTS for 2025.
13. Strategic Outlook
Future roadmap \& innovations:
- Continued expansion of real-time voice direction controls—“add suspense,” “blend emotions” at segment level.
- Upcoming release of automatic speech-to-text for enhanced integrated workflows.
- Planned optimizations for memory and compute efficiency, supporting broader edge and mobile deployments.
Market trends \& recommendations:
- Voice AI will increasingly blend nuance, multilingual support, and interactive real-time control.
- Fish Audio S1’s focus on affordable, expressive TTS at high quality positions it to drive new standards for digital narration, conversational AI, and global content creation.
Final Thoughts
Fish Audio S1 has set a benchmark for expressive TTS and instant voice cloning, balancing technical sophistication, affordability, and practical usability. It delivers exceptional voice realism, fine-grained emotion, and strong cross-linguistic support, making it a compelling choice for content creators and developers aiming for lifelike audio experiences. While larger enterprises may wish to confirm security and executive details before deployment, S1’s combination of rapid innovation, robust community, and cost efficiency ensures it remains at the forefront of synthetic voice solutions.