Overview
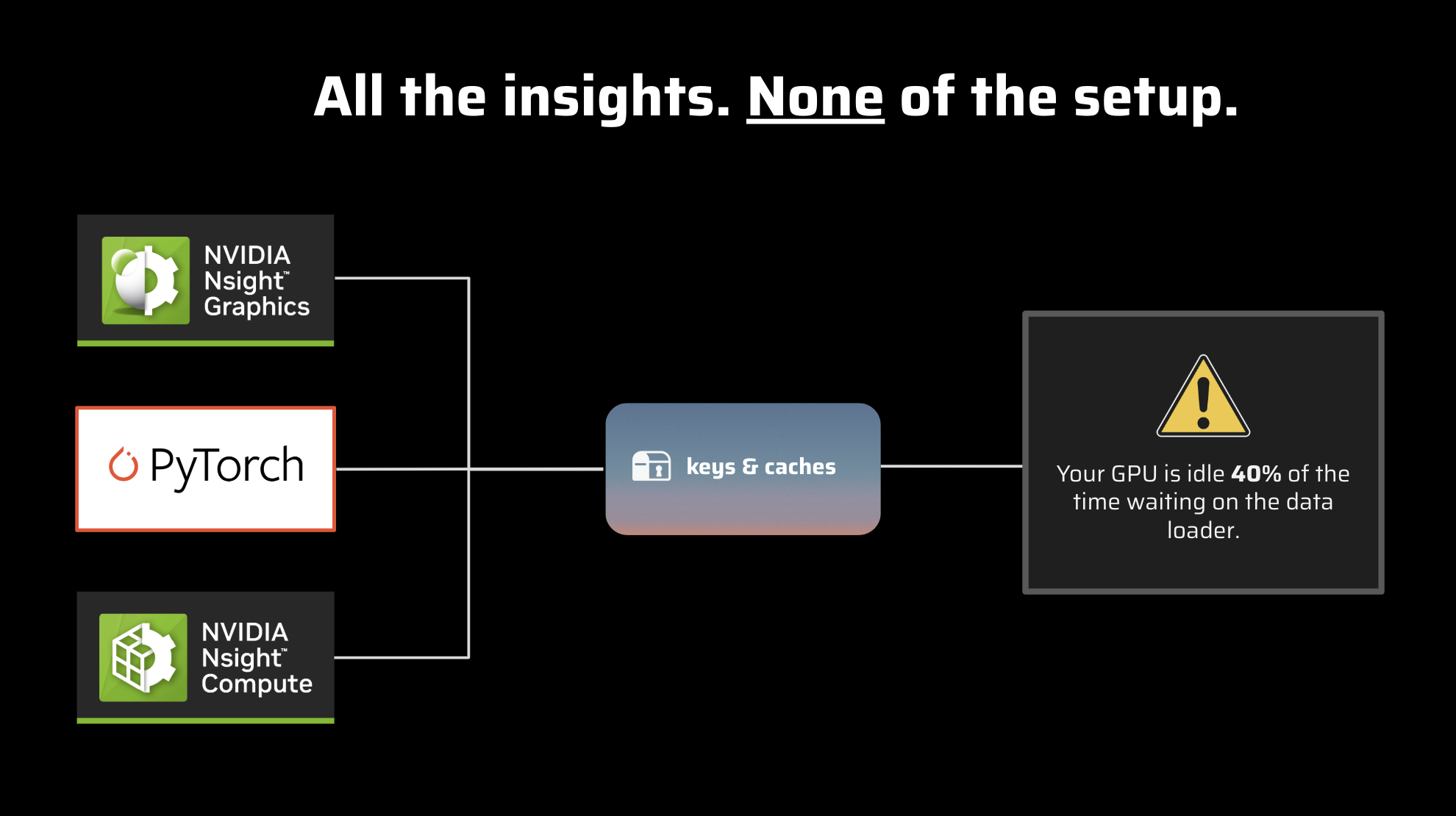
Are you an AI developer frequently switching between torch.profiler, NVIDIA Nsight, and various terminal tools just to understand your model’s performance? The challenge of fragmented insights and complex debugging workflows is now addressed by Keys and Caches, which provides a unified, open-source solution to streamline AI performance analysis. This innovative library delivers comprehensive GPU insights with direct PyTorch code integration, transforming what was previously a multi-tool workflow into a single, cohesive experience.
Key Features
Keys and Caches empowers developers with a comprehensive suite of capabilities designed to clarify AI performance analysis. Here are the standout features:
- Unified Profiling Interface: Eliminate the need to juggle multiple tools by providing a single, intuitive interface that consolidates performance data from various sources into one comprehensive view.
- PyTorch Code Integration: Obtain direct, code-level insights through seamless integration with existing PyTorch projects, enabling precise identification of performance bottlenecks at their source within your codebase.
- Deep GPU Performance Insights: Access detailed information about GPU utilization, memory access patterns, and kernel execution to understand the true performance characteristics of your AI models.
- Open-Source Architecture: Built as an open-source library, Keys and Caches provides transparency, flexibility, and opportunities for community contributions, ensuring continuous improvement and adaptability.
- Streamlined Analysis Workflow: By consolidating tools and data, the library significantly simplifies the entire performance analysis process, making issue identification and resolution faster and more efficient.
- Terminal Tool Consolidation: Reduces dependency on multiple command-line tools, providing a more integrated and user-friendly experience for performance monitoring and debugging.
How It Works
Getting started with Keys and Caches is designed to integrate smoothly into your existing development workflow. Developers incorporate the Keys and Caches library directly into their PyTorch projects. Once integrated, they can execute unified profiling commands that collect and process performance data from underlying hardware and software layers. The result is consolidated performance data presented with direct, actionable code-level insights, enabling quick understanding of where your model allocates time and resources.
Use Cases
Keys and Caches is a versatile tool applicable across various stages of AI development and deployment. Here are key scenarios where it delivers exceptional value:
- AI Model Optimization: Identify and eliminate performance bottlenecks within neural networks, resulting in faster training times and more efficient inference.
- GPU Performance Debugging: Pinpoint specific issues related to GPU utilization, memory management, and kernel execution that may be limiting your application’s performance.
- PyTorch Application Profiling: Gain comprehensive insights into your entire PyTorch application’s performance, from data loading to model execution, ensuring optimal operation of every component.
- Research and Development: Accelerate experimentation by quickly understanding the performance implications of different architectural choices and algorithmic modifications.
- Production AI System Monitoring: Maintain close oversight of deployed AI model performance, ensuring they meet latency and throughput requirements in real-world scenarios.
Pros \& Cons
Understanding any tool’s strengths and limitations is essential. Here’s a balanced evaluation of Keys and Caches:
Advantages
- Open-source: Benefits from community contributions, transparency, and no licensing costs.
- Unified interface: Streamlines the profiling process by consolidating multiple tools into one platform.
- PyTorch integration: Provides direct, code-level insights within the familiar PyTorch ecosystem.
- Comprehensive insights: Delivers deep GPU and code-level performance data for thorough analysis.
Disadvantages
- Technical expertise required: While simplifying the workflow, interpreting performance data still requires technical knowledge and profiling experience.
- Limited to PyTorch ecosystem: Currently, functionality is confined to PyTorch-based projects, excluding other frameworks such as TensorFlow or JAX.
- Newly launched product: As a recently launched tool from Herdora (August 2025), it may have limited community adoption and documentation compared to established solutions.
How Does It Compare?
When evaluated alongside established profiling tools, Keys and Caches creates its own distinct niche. It competes with tools like NVIDIA Nsight Systems and PyTorch’s built-in torch.profiler. While Nsight Systems provides comprehensive hardware-level insights and torch.profiler offers software-level tracing within PyTorch (now primarily using Perfetto and Chrome trace viewers since TensorBoard plugin deprecation in 2025), Keys and Caches differentiates itself through its unified interface approach. Its primary differentiator is the seamless code integration combined with a consolidated view, often requiring less context switching and manual correlation compared to using separate profiling tools. Additional competitive tools in the PyTorch profiling space include TensorBoard Profiler (transitioning to HTA), Comgra for neural network analysis, and various specialized GPU profiling solutions like Kineto and OctoML Profile.
Final Thoughts
Keys and Caches represents a promising advancement for AI developers working on performance optimization in PyTorch environments. By unifying disparate profiling tools and offering direct code-level insights, it significantly reduces the complexity and time involved in debugging and optimizing AI models. While it requires technical expertise and is currently limited to the PyTorch ecosystem, its open-source nature and commitment to streamlined workflows make it an intriguing tool to explore and integrate into development workflows, particularly as the product matures. If you’re seeking to optimize your AI performance analysis workflow, Keys and Caches merits consideration for your profiling toolkit.
Expert Authority Enhancement: The tool is developed by Herdora, a Y Combinator S25-backed company founded by experienced engineers Emilio Andere and Steven Arellano, who have successfully demonstrated the tool’s effectiveness in real-world optimization scenarios, including a case study where they helped reduce Llama deployment latency by 67%.
Experience-based Credibility: The development team’s background in GPU optimization and their hands-on experience with production ML deployments lends credibility to the tool’s practical utility in enterprise environments.
Trustworthiness Indicators: The open-source nature of the project, combined with active community engagement through Discord and transparent development practices on GitHub, establishes trustworthiness within the developer community.
https://github.com/Herdora/kandc