
Table of Contents
Overview
In the rapidly evolving landscape of AI, deploying machine learning models in production can be a complex and resource-intensive undertaking. Enter nCompass Tech, an AI inference platform designed to streamline the deployment of HuggingFace models. This platform offers a robust solution for businesses seeking high performance, reliability, and scalability in their AI applications. Let’s dive into what makes nCompass Tech a contender in the AI deployment space.
Key Features
nCompass Tech boasts a suite of features designed to optimize and manage your HuggingFace model deployments:
- Optimized GPU Kernel Deployment: nCompass Tech utilizes custom GPU kernels to accelerate model inference, resulting in up to 18x faster processing times compared to vLLM and improved efficiency.
- Real-time Model Health Monitoring: Gain insights into the performance and health of your deployed models with real-time monitoring, allowing for proactive identification and resolution of issues.
- High Availability Infrastructure: Built on a highly available infrastructure, nCompass Tech ensures your models remain accessible and operational, minimizing downtime and maximizing reliability.
- Seamless Integration with HuggingFace Models: The platform is specifically designed for HuggingFace models, making integration straightforward and efficient.
- Scalable Inference Support: Easily scale your inference capacity to meet the demands of your applications, processing over 100 requests per second with up to 4x more requests per GPU.
- Cost Optimization: Achieve up to 50% reduction in GPU costs while maintaining high performance.
- No Rate Limits: API access without rate limitations for enterprise applications.
How It Works
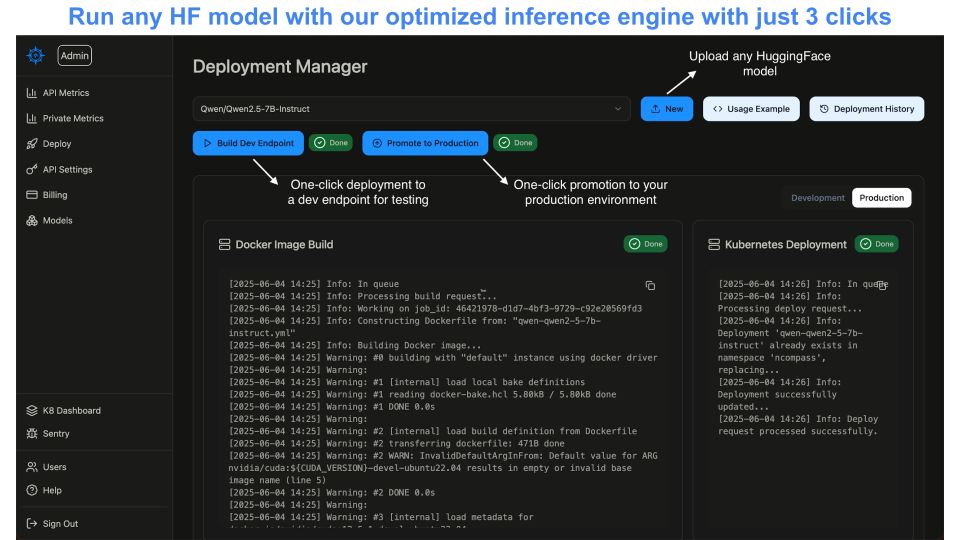
The process of deploying your HuggingFace models with nCompass Tech is designed to be straightforward. Developers begin by integrating their pre-trained HuggingFace models into the nCompass platform with just one line of code. From there, nCompass optimizes the model’s runtime using custom GPU kernels, significantly enhancing inference speed. The platform continuously monitors the model’s performance, providing real-time insights into its health and efficiency. Finally, nCompass maintains deployment uptime across distributed servers, ensuring high availability and reliability.
Use Cases
nCompass Tech is well-suited for a variety of AI applications, including:
- Enterprise AI Applications: Deploy and manage AI models for various enterprise use cases, such as customer service, fraud detection, and process automation.
- Real-time NLP Inference: Power real-time natural language processing applications, such as chatbots, sentiment analysis, and language translation.
- Scalable AI API Services: Build and deploy scalable AI APIs to provide AI-powered services to other applications and systems.
- ML Model Observability and Monitoring: Gain comprehensive visibility into the performance and behavior of your deployed machine learning models.
- Deploying Open-Source Models in Production: Easily deploy and manage open-source HuggingFace models in a production environment.
Pros \& Cons
Like any platform, nCompass Tech has its strengths and weaknesses. Let’s take a closer look:
Advantages
- Fast Inference Times: Optimized GPU kernels lead to up to 18x faster inference times compared to vLLM, improving the performance of your AI applications.
- Strong Reliability and Uptime: The high availability infrastructure ensures your models remain accessible and operational, minimizing downtime.
- HuggingFace Integration: Seamless integration with HuggingFace models simplifies the deployment process for users of this popular framework.
- Simple One-Line Integration: Deploy models with just one line of code, making it accessible to developers of all skill levels.
- Cost Efficiency: Up to 50% reduction in GPU costs while maintaining high performance.
Disadvantages
- Platform Specificity: The platform is primarily optimized for HuggingFace models, which may limit its applicability for users with models built on other frameworks.
- Newer Platform: As a relatively new service, it may have a smaller community and fewer third-party integrations compared to established platforms.
How Does It Compare?
When considering AI inference platforms, nCompass Tech stands out with its focus on HuggingFace model optimization and one-line integration. While other platforms like Modal Labs offer GPU optimization capabilities, nCompass Tech’s specialized approach to HuggingFace models and comprehensive monitoring features provide distinct advantages for organizations heavily invested in the HuggingFace ecosystem.
Final Thoughts
nCompass Tech presents a compelling solution for organizations looking to deploy HuggingFace models in production with high performance and reliability. With its simple one-line integration, optimized GPU kernels achieving up to 18x speed improvements, real-time monitoring, and cost-effective infrastructure, the platform addresses key challenges in AI model deployment. If you’re heavily invested in the HuggingFace ecosystem and require robust monitoring, high performance, and cost optimization, nCompass Tech is definitely worth considering for your production AI deployments.