Table of Contents
Overview
In the ever-evolving landscape of AI-driven tools, text-to-speech (TTS) technology continues to advance, offering more realistic and expressive speech synthesis. Orpheus TTS, an open-source system developed by Canopy Labs, is making waves with its ability to generate human-like speech with natural emotion and intonation. Built on the powerful Llama-3b backbone, Orpheus TTS brings a new level of customization and control to the world of voice synthesis. Let’s dive into what makes Orpheus TTS a compelling option for developers and content creators alike.
Key Features
Orpheus TTS boasts a range of features designed to deliver high-quality and customizable speech output:
- Human-like speech synthesis: Generates natural-sounding speech that closely mimics human intonation and rhythm.
- Zero-shot voice cloning: Allows users to clone voices with minimal training data, opening up possibilities for personalized voice experiences.
- Emotion and intonation control: Provides granular control over the emotional nuances and intonation patterns in the generated speech.
- Low-latency streaming (~200ms): Enables real-time applications with minimal delay, making it suitable for interactive scenarios.
- Open-source with customizable models: Offers full access to the underlying code and models, allowing for extensive customization and fine-tuning.
How It Works
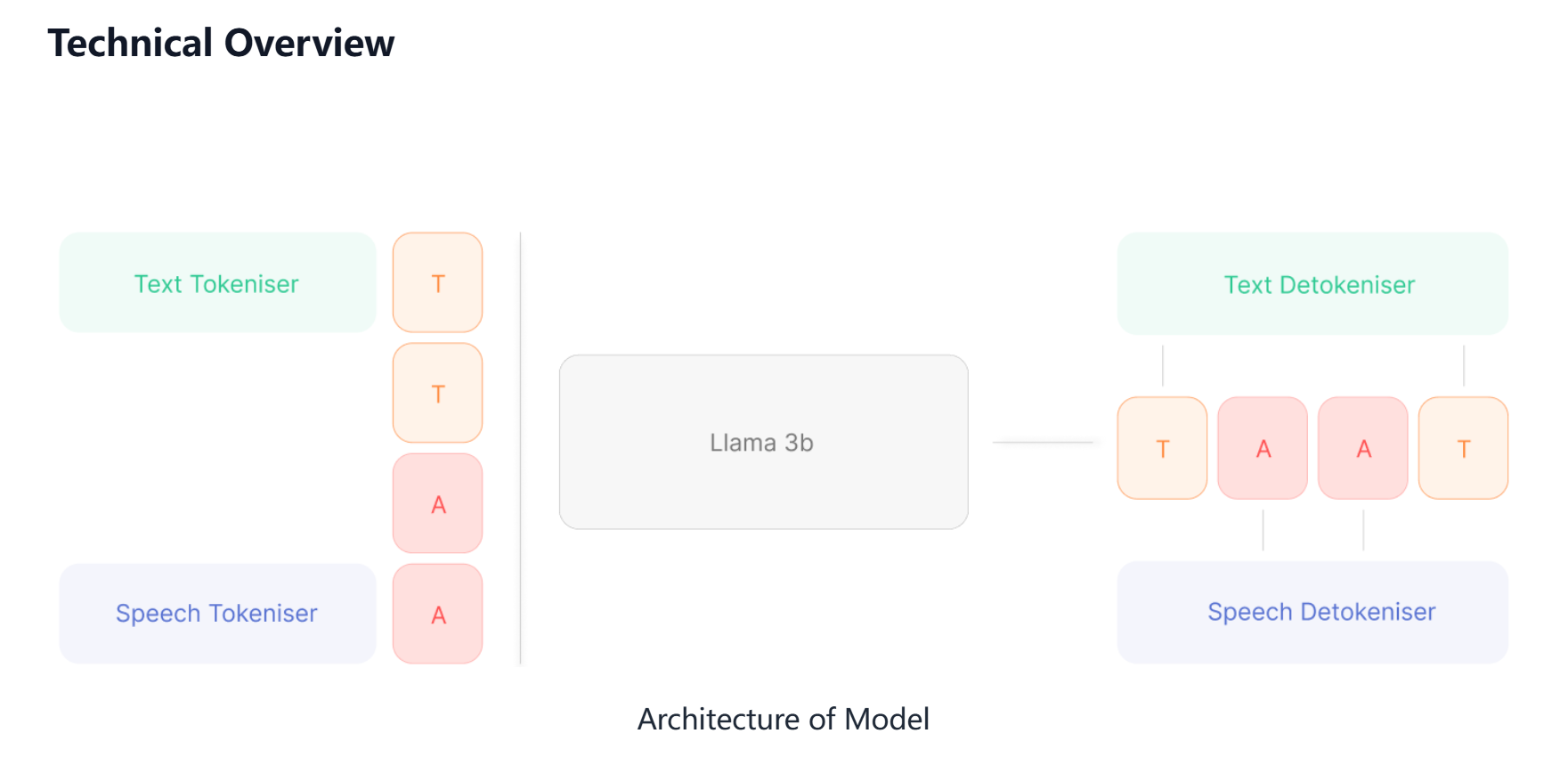
Orpheus TTS leverages the Llama-3b architecture to transform text into realistic speech. The system employs a SNAC decoder and a non-streaming tokenizer to process the input text. This process converts the text into audio tokens, which are then used to generate the final speech output. The architecture allows for nuanced control over emotional expression, resulting in more natural and engaging speech. The non-streaming tokenizer contributes to the system’s ability to capture context and generate more coherent speech patterns.
Use Cases
Orpheus TTS’s capabilities make it a versatile tool for various applications:
- Audiobook narration: Create engaging and expressive audiobook narrations with customizable voice tones.
- Virtual assistants: Develop more human-like and responsive virtual assistants with natural-sounding speech.
- Real-time communication tools: Enhance real-time communication applications with low-latency speech synthesis.
- Voice cloning for content creation: Clone voices for various content creation purposes, such as personalized messages or character voices.
Pros & Cons
Like any technology, Orpheus TTS has its strengths and weaknesses. Let’s examine the advantages and disadvantages:
Advantages
- High-quality, expressive speech output that rivals human speech.
- Open-source and customizable, offering unparalleled control over the system.
- Zero-shot voice cloning capabilities for personalized voice experiences.
Disadvantages
- Requires substantial computational resources for training and inference.
- Technical expertise is needed for setup and customization.
How Does It Compare?
When comparing Orpheus TTS to other text-to-speech systems, such as ElevenLabs, a key difference emerges. ElevenLabs is a proprietary platform with limited customization options. In contrast, Orpheus TTS is open-source, providing users with full customization and control over the models and parameters. This makes Orpheus TTS a compelling choice for users who require greater flexibility and control over their text-to-speech system.
Final Thoughts
Orpheus TTS represents a significant step forward in open-source text-to-speech technology. Its ability to generate human-like speech with natural emotion and intonation, coupled with its open-source nature and customization options, makes it a powerful tool for developers and content creators. While it requires technical expertise and computational resources, the potential benefits of Orpheus TTS are undeniable. As the technology continues to evolve, Orpheus TTS is poised to play a key role in shaping the future of voice synthesis.