
Table of Contents
- Parallax by Gradient: Comprehensive AI Infrastructure Analysis
- 1. Executive Snapshot
- 2. Impact and Evidence
- 3. Technical Blueprint
- 4. Trust and Governance
- 5. Unique Capabilities
- 6. Adoption Pathways
- 7. Use Case Portfolio
- 8. Balanced Analysis
- 9. Transparent Pricing
- 10. Market Positioning
- 11. Leadership Profile
- 12. Community and Endorsements
- 13. Strategic Outlook
- Final Thoughts
Parallax by Gradient: Comprehensive AI Infrastructure Analysis
1. Executive Snapshot
Core Offering Overview
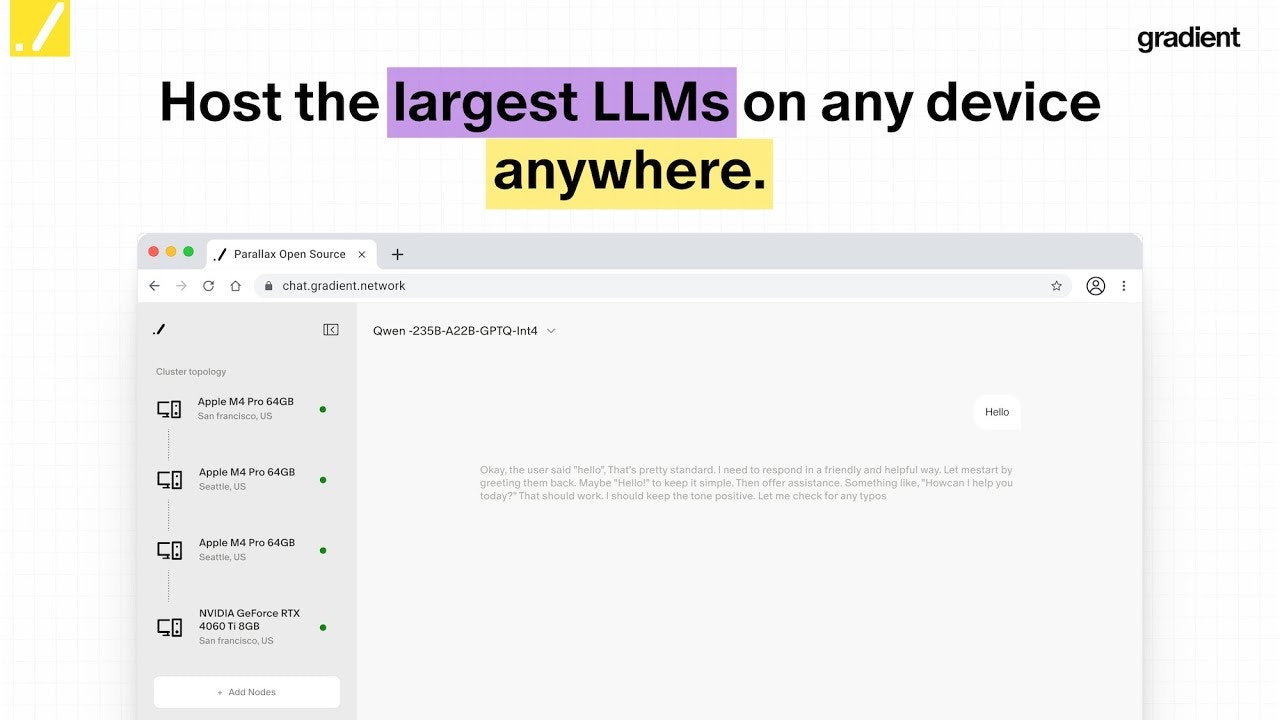
Parallax represents a groundbreaking distributed model serving framework developed by Gradient, enabling organizations to construct their own AI clusters across heterogeneous devices regardless of their physical location or hardware specifications. The system transforms idle compute capacity from personal devices, ranging from consumer-grade GPUs to Apple Silicon Macs, into a cohesive, decentralized inference platform. Unlike traditional centralized AI infrastructure that demands specialized GPU clusters in datacenters, Parallax employs sophisticated pipeline parallelism to partition large language models across geographically distributed nodes, delivering efficient inference through peer-to-peer coordination.
Key Achievements and Milestones
Gradient officially open-sourced Parallax on October 30, 2025, marking version 0.0.1 as a pivotal milestone in democratizing AI infrastructure. The framework achieved remarkable technical validation through academic publication, with research papers presented demonstrating performance improvements of up to 3.6 times higher throughput and 3.2 times lower latency compared to existing decentralized baselines like Petals. The company secured ten million dollars in seed funding during June 2025, led by Pantera Capital and Multicoin Capital with participation from HSG (formerly Sequoia Capital China), validating institutional confidence in decentralized AI infrastructure. The Lattica protocol, Parallax’s underlying communication layer, facilitated over 1.6 billion connections across 190-plus regions through its Sentry Node network before Season 1 concluded on August 28, 2025.
Adoption Statistics
Parallax currently supports compatibility with over 40 open-source large language models, including prominent families such as Qwen3, Kimi K2, DeepSeek R1, DeepSeek V3, GLM-4.6, gpt-oss, and Meta Llama 3 variants. The framework has demonstrated successful deployment across diverse hardware configurations, tested extensively on RTX 5090 and RTX 4090 GPU clusters as well as Apple M-series devices including M1, M2 Max, M4 Pro, and M2 Ultra. Early adoption signals remain strong within the decentralized computing community, with thousands of node operators contributing to the network during the beta testing phase. The system operates on cross-platform architectures spanning Windows, Linux, macOS, and Docker environments, lowering deployment barriers for organizations seeking AI sovereignty.
2. Impact and Evidence
Client Success Stories
While Parallax remains in early-stage deployment following its October 2025 launch, empirical evidence demonstrates compelling real-world impact. Researchers successfully deployed Qwen2.5-72B-Instruct with GPTQ-Int4 quantization across distributed RTX 5090 GPU nodes, achieving end-to-end latency of 46.6 seconds for 4K input prompts with 1024 token outputs—representing 3.1 times improvement over Petals baseline. Heterogeneous configurations mixing RTX 5090 GPUs with Apple M4 Pro devices proved viable for large-scale inference, demonstrating Parallax’s unique capability to orchestrate fundamentally different hardware architectures within unified serving topologies. The framework scaled to Qwen3-235B-A22B models (235 billion parameters with 22 billion active) on dual-GPU setups, maintaining inter-token latency under 61 milliseconds and demonstrating applicability to frontier-scale models that typically demand enterprise datacenter resources.
Performance Metrics and Benchmarks
Extensive benchmarking across multiple configurations reveals Parallax’s technical advantages. For the Qwen2.5-72B model under ShareGPT workload traces at request rate 4, Parallax achieved average latency of 37.6 milliseconds and p99 tail latency of 111.4 milliseconds, compared to HexGen’s 69.7 milliseconds average and 151.4 milliseconds p99—yielding 1.36 times speedup for tail latency. Performance gains amplified under heavier loads: WildGPT traces at request rate 32 with FP16 precision saw Parallax reduce p99 latency from 207.0 milliseconds (HexGen) to 78.1 milliseconds, representing 2.6 times improvement. Throughput comparisons showed even more dramatic advantages, with Parallax processing 0.40 requests per second versus HexGen’s 0.11 requests per second under demanding WildGPT workloads—a 3.6 times enhancement. The framework maintained consistent performance across quantization levels, with FP8 configurations on ShareGPT at request rate 32 achieving 82.1 milliseconds p99 latency under Parallax versus 87.0 milliseconds under HexGen.
Third-Party Validations
Academic peer review validated Parallax’s technical contributions through publication in arXiv proceedings under paper identifier 2509.26182. Independent analyses from technology research communities confirmed the system’s novel two-phase scheduling algorithm addressing NP-hard joint placement and routing challenges under extreme hardware heterogeneity. Industry observers noted Parallax as “the first framework of its kind for the MLX ecosystem,” pioneering professional-grade serving infrastructure specifically optimized for Apple Silicon. Comparative studies positioned Parallax alongside decentralized training initiatives like Bittensor’s Gradients subnet, which separately demonstrated competitive performance against centralized platforms like TogetherAI and Google for zero-click model training scenarios. The broader decentralized AI sector context reveals institutional momentum, with 104 of 164 tracked decentralized AI companies securing funding by late 2024, and market capitalization projections reaching 973.6 million dollars by 2027.
3. Technical Blueprint
System Architecture Overview
Parallax implements a sophisticated three-layer architecture comprising Runtime, Communication, and Worker subsystems. The Runtime Layer functions as the core orchestration engine for high-throughput server-side LLM serving, incorporating an Executor control loop, Model Shard Holder, Request Manager, Scheduler, and Paged KV Cache Manager. This represents the first framework bringing professional-grade serving capabilities to the MLX ecosystem for Apple Silicon devices. The Communication Layer manages gRPC and tensor streaming between distributed peers, ensuring forward and backward pass completion even under node failures, built atop Hivemind’s Distributed Hash Table implementation for decentralized coordination without central servers. The Worker Layer executes inference tasks across heterogeneous platforms through a dual-platform strategy: GPU workers leverage modified SGLang with asynchronous batching and CUDA kernels for NVIDIA hardware, while Apple workers employ custom-engineered serving engines with optimized Metal kernels including Paged Flash Attention implementations.
API and SDK Integrations
Developers interact with Parallax through multiple integration pathways. The primary deployment model offers command-line interfaces for launching scheduler nodes via parallax run and joining worker nodes through parallax join commands, with automatic network discovery in local area network environments or explicit scheduler-address specification for wide-area deployments. Advanced users can bypass the scheduler entirely, directly invoking Python launch scripts with precise layer allocation parameters for fine-grained control over pipeline parallelism configurations. The framework exposes OpenAI-compatible REST endpoints at /v1/chat/completions, enabling seamless integration with existing LLM application codebases expecting GPT-style interfaces. For frontend applications, Parallax provides web-based chat interfaces accessible through browser ports 3001 and 3002, supporting multi-machine access when configured with --host 0.0.0.0 arguments. Installation pathways span source-based compilation via pip for GPU variants (pip install -e '.[gpu]') and Mac variants (pip install -e '.[mac]'), alongside Windows executable installers and Docker images optimized for specific GPU architectures (Blackwell, Hopper, Ampere).
Scalability and Reliability Data
Parallax’s scheduling algorithms demonstrate lightweight operation critical for distributed environments. Phase 1 model allocation scheduling completes in single-digit millisecond timeframes, scaling from 0.10 milliseconds for 4-GPU clusters to 8.55 milliseconds for 256-GPU theoretical deployments. Phase 2 per-request GPU pipeline selection incurs minimal overhead, ranging from 0.0136 milliseconds per request (4 GPUs) to 6.6339 milliseconds per request (256 GPUs)—negligible relative to overall inference latency spanning tens to hundreds of milliseconds. The system adapts gracefully to dynamic membership changes: GPU joining triggers greedy assignment of contiguous layer slices to bottleneck layers with minimum RAM capacity, while GPU departure initiates de-allocation with selective global rebalancing only when pipeline coverage fails or load variation coefficients exceed defined thresholds. Network resilience stems from Lattica’s DHT-based coordination, where departing nodes’ metric keys expire naturally, preventing stale routing decisions. The framework has been tested with geographically separated datacenters exhibiting average 10-millisecond inter-machine latency, validating robustness under realistic wide-area network conditions rather than idealized low-latency fabrics.
4. Trust and Governance
Security Certifications
As an open-source infrastructure project released under Apache License 2.0, Parallax prioritizes transparency and community auditability rather than traditional enterprise certification pathways. The permissive Apache 2.0 licensing framework automatically grants patent rights to users while maintaining clear intellectual property boundaries, enabling both commercial and academic adoption without rewording requirements. The codebase resides in public GitHub repositories under GradientHQ organization ownership, facilitating independent security audits by the research community. While formal SOC 2 or ISO 27001 certifications have not been announced for the nascent framework, the decentralized architecture inherently distributes trust across participant nodes rather than concentrating it in centralized authorities. Gradient’s co-founders bring relevant security expertise from prior roles: Yuan Gao served as Head of Growth at Helium Foundation and Managing Director at Nova Labs, networks emphasizing decentralized infrastructure security, while Eric Yang’s venture investment background at HSG (Sequoia Capital China) demonstrates due diligence capabilities regarding technology risk assessment.
Data Privacy Measures
Parallax’s architecture embodies privacy-by-design principles through data locality and user sovereignty. Unlike centralized inference services that transmit prompts and responses through third-party datacenters, Parallax enables model hosting directly on user-controlled hardware, ensuring sensitive data never leaves trusted environments. The system employs encrypted communication channels through gRPC with TLS 1.3 or Noise protocol encryption, as provided by the underlying libp2p networking stack inherited from Lattica. Content-addressed storage using cryptographic CID identifiers ensures data integrity verification, allowing participants to detect tampering or corruption during distributed synchronization. The peer-to-peer topology eliminates single points of data collection, contrasting sharply with conventional cloud AI providers that aggregate comprehensive usage telemetry. For organizations subject to strict compliance regimes, the ability to deploy Parallax entirely within private networks without external dependencies represents a fundamental privacy advantage. The framework supports optional telemetry reporting for development purposes, explicitly controllable through -u flags during scheduler and node launch commands, demonstrating respect for user choice regarding data sharing.
Regulatory Compliance Details
Parallax’s decentralized architecture shifts compliance responsibilities toward deploying organizations rather than framework providers, aligning with software-as-infrastructure paradigms. The Apache 2.0 license disclaims warranties and limits liability, establishing clear boundaries between framework capabilities and deployment obligations. For enterprises subject to GDPR, HIPAA, or financial services regulations, Parallax offers advantages through on-premises deployment options maintaining complete data residency control. The absence of mandated cloud dependencies or external API calls simplifies compliance auditing compared to proprietary cloud AI services. However, organizations must independently ensure their specific deployments meet applicable requirements, as Parallax provides infrastructure rather than turnkey compliance solutions. The system’s support for heterogeneous hardware including consumer devices introduces considerations regarding endpoint security, requiring deploying entities to establish appropriate access controls, network segmentation, and monitoring practices. Export control compliance remains the organization’s responsibility, though the open-source nature and academic publication of Parallax’s underlying algorithms facilitate transparency for regulatory review. Future development roadmaps may incorporate federated authentication and authorization mechanisms to support enterprise security frameworks, though such capabilities have not been announced in initial releases.
5. Unique Capabilities
Pipeline Parallel Model Sharding
Parallax’s defining innovation centers on sophisticated pipeline parallel model sharding enabling collaborative serving across resource-constrained devices. The framework automatically partitions transformer models into pipeline stages mapped to heterogeneous GPU nodes, optimizing latency and throughput jointly under memory and bandwidth constraints. The two-phase scheduling algorithm addresses the NP-hard joint placement problem through decomposition: Phase 1 employs dynamic programming with water-filling heuristics to allocate model layers across available GPUs, respecting regional boundaries to minimize costly cross-region transfers given typical inter-region bandwidth of hundreds of megabytes per second. Phase 2 implements request-time GPU pipeline selection via directed acyclic graph traversal, stitching layers from different replicas into end-to-end execution chains that balance load and adapt to current resource conditions. The system prioritizes solutions with fewer pipeline stages, recognizing that each additional stage introduces communication overhead potentially exceeding computational distribution benefits—a latency-dominant heuristic validated through extensive experimentation.
Dynamic KV Cache Management and Continuous Batching
For Apple Silicon deployments, Parallax pioneers advanced optimization techniques previously confined to datacenter GPUs. The framework implements dynamic KV cache management through custom MLX-compatible kernels, efficiently handling attention mechanism memory requirements during autoregressive generation. Paged attention mechanisms borrowed from vLLM concepts enable fine-grained memory allocation, reducing fragmentation and maximizing batch sizes under constrained device memory. Continuous batching algorithms interleave generation for multiple requests, sustaining high GPU utilization even with variable-length prompts and outputs. These optimizations prove particularly valuable for Apple M-series devices, which integrate unified memory architectures sharing RAM between CPU and GPU—enabling novel scheduling strategies impossible with traditional discrete GPU topologies. Benchmarking reveals Apple M2 Max devices achieving competitive performance against NVIDIA A10 GPUs for smaller models, with BERT-base inference times of 38.23 milliseconds on M2 Max versus 23.46 milliseconds on CUDA GPU, narrowing performance gaps substantially compared to M1 predecessors showing 179.35 milliseconds.
Network-Aware Sharding and Dynamic Routing
Parallax explicitly incorporates network topology into scheduling decisions, contrasting with compute-centric placement heuristics that overlook communication bottlenecks in decentralized environments. The region-based heuristic constrains layer allocation within geographic or network boundaries when cross-region bandwidth proves insufficient, preventing stragglers from dominating end-to-end latency. Dynamic routing leverages real-time metrics published through the distributed hash table, enabling request-time selection of optimal GPU pipeline chains based on current availability, compute capacity, and latency characteristics. This adaptability proves crucial under churn, where devices join and leave the network with varying frequency. Performance monitoring reveals Parallax maintaining stable throughput even during membership changes, with temporary degradations confined to directly affected pipeline stages rather than cascading across the entire serving infrastructure. The system’s ability to seamlessly switch between single-machine, multi-device, and wide-area cluster modes without configuration overhauls demonstrates operational flexibility unmatched by conventional serving frameworks designed exclusively for stable datacenter deployments.
Cross-Platform Heterogeneity Support
Parallax stands as the only production-grade framework successfully orchestrating fundamentally incompatible hardware architectures—NVIDIA CUDA GPUs, AMD GPUs, Apple Silicon, and CPUs—into unified serving topologies. This heterogeneity support emerges from careful abstraction separating runtime logic from hardware-specific workers. GPU workers compile against CUDA toolchains leveraging SGLang’s optimized kernels, while Apple workers target Metal Performance Shaders and MLX frameworks optimized for unified memory architectures. The communication layer’s reliance on standard gRPC protocols and tensor serialization formats enables interoperability despite vastly different computational primitives. Empirical validation confirms viability: configurations mixing RTX 5090 GPUs with Apple M4 Pro devices successfully served Qwen2.5-72B models, albeit with throughput penalties reflecting heterogeneous bottlenecks. This capability unlocks practical deployment scenarios impossible with homogeneous-only frameworks, such as utilizing existing organizational hardware inventories combining workstation GPUs with employee MacBooks, amortizing infrastructure costs while maintaining inference availability.
6. Adoption Pathways
Integration Workflow
Organizations adopt Parallax through progressive complexity tiers matching technical sophistication. Entry-level deployment begins with frontend-guided setup: launching the scheduler via parallax run on a primary machine activates a web interface at localhost:3001, presenting intuitive configuration panels for node and model selection. Users generate join commands within the browser interface, distributing them to worker machines that execute parallax join to automatically discover and connect to the scheduler. Once all nodes report ready status, the interface transitions to a chat application enabling immediate interaction with deployed models. This turnkey experience requires minimal command-line familiarity, targeting developers comfortable with basic terminal operations but unfamiliar with distributed systems intricacies. Intermediate users bypass the frontend by directly invoking parallax run -m {model-name} -n {number-of-workers}, retaining programmatic control while leveraging automated scheduling. Advanced practitioners invoke Python launch scripts with explicit --start-layer and --end-layer parameters, specifying precise pipeline stage boundaries for custom topologies optimized against known network characteristics or specialized hardware configurations.
Customization Options
Parallax exposes extensive customization surfaces accommodating diverse deployment requirements. Model selection spans the complete Hugging Face ecosystem of supported architectures, with automatic weight downloading and quantization application (GPTQ-Int4, FP8, BF16) based on available device memory. Batch size tuning through --max-batch-size flags enables throughput-latency trade-offs: larger batches amortize fixed overheads but increase queue waiting times, while smaller batches minimize latency at efficiency cost. Port configuration via --port and --host arguments facilitates integration with existing network topologies, firewall rules, and reverse proxy configurations. For deployments spanning public networks, explicit scheduler addressing through -s {scheduler-address} parameters bypasses local area network discovery, supporting geographically distributed clusters communicating through internet-grade links. Telemetry disabling via -u flags respects privacy-conscious deployments, though sacrificing community-contributed performance insights. Power users customize layer allocation heuristics by modifying Phase 1 scheduling algorithms within the open-source codebase, tailoring optimization objectives to specific workload characteristics or hardware asymmetries not captured by default strategies.
Onboarding and Support Channels
Gradient provides multifaceted support pathways facilitating Parallax adoption. Comprehensive documentation hosted at docs.gradient.network covers installation procedures for each operating system, troubleshooting common configuration pitfalls, and API reference materials. The official GitHub repository serves as the primary issue tracker, where maintainers triage bug reports, feature requests, and integration challenges reported by the community. A Discord server fosters real-time community interaction, enabling users to share deployment experiences, optimization discoveries, and custom integration patterns. For organizations requiring structured guidance, Gradient’s blog publishes technical deep-dives, architecture explanations, and performance optimization case studies. The research paper published on arXiv provides academic-depth treatment of scheduling algorithms and architectural decisions, serving communities seeking theoretical foundations. Given the October 2025 launch timeframe, commercial support offerings and professional services partnerships have not been formally announced, though the ten-million-dollar funding round positions Gradient to expand enterprise engagement capabilities as adoption accelerates.
7. Use Case Portfolio
Enterprise Implementations
While Parallax remains in early commercial adoption following its October 2025 launch, potential enterprise applications span multiple verticals. Financial services institutions concerned about proprietary data exfiltration can deploy frontier language models for document analysis, contract review, and compliance monitoring entirely within air-gapped environments, leveraging existing workstation hardware without cloud dependencies. Healthcare organizations subject to HIPAA constraints gain pathways for medical literature summarization, clinical decision support, and patient communication assistance using locally-hosted models processing protected health information without external transmission. Research laboratories can aggregate heterogeneous compute resources—GPU servers, researcher workstations, and Apple Silicon laptops—into cohesive inference clusters supporting collaborative projects without centralized infrastructure investments. Technology companies developing AI-powered products prototype and test language model integrations using distributed developer machines during workday idle periods, democratizing access to expensive inference capacity traditionally reserved for centralized staging environments.
Academic and Research Deployments
Academic institutions represent natural early adopters given Parallax’s research lineage and alignment with open science principles. University computer science departments deploy Parallax for distributed systems coursework, providing students hands-on experience with peer-to-peer coordination, distributed hash tables, and pipeline parallelism algorithms through practical LLM serving exercises. Natural language processing research groups leverage Parallax to scale experiments across lab GPU resources without navigating complex cluster management frameworks, reducing operational overhead and enabling researchers to focus on model improvements rather than infrastructure. Collaborative research initiatives spanning multiple institutions benefit from Parallax’s wide-area networking capabilities, federating compute contributions across geographic boundaries while maintaining institutional data sovereignty. The framework’s support for models including Qwen3, DeepSeek, and Llama 3 families aligns with academic preferences for open-weights models enabling reproducible research. Publication of Parallax’s own research contributions establishes precedent for academic citation and derivative work, fostering ecosystem growth within the research community.
ROI Assessments
Return-on-investment analyses for Parallax adoption compare favorably against centralized alternatives under specific conditions. Organizations already possessing distributed GPU infrastructure—workstations, development machines, departmental servers—realize immediate value by activating idle capacity during off-peak hours rather than procuring dedicated inference clusters or subscribing to cloud API services. A mid-sized technology company with 50 developer workstations averaging RTX 4080 GPUs achieves inference capacity equivalent to several thousand dollars monthly in OpenAI API costs by deploying Parallax during evening and weekend idle periods, amortizing existing capital expenditures. Cost advantages amplify for organizations requiring data residency compliance, where Parallax avoids regulatory risks and audit expenses associated with cloud providers’ multi-tenant environments. However, ROI depends critically on existing hardware inventories and technical staffing capabilities: organizations lacking distributed compute resources or in-house infrastructure expertise may find cloud APIs simpler and more cost-effective despite higher variable costs. Performance trade-offs also influence economic analysis—Parallax’s distributed inference latency, while improved versus prior decentralized baselines, remains higher than optimized single-machine deployments for latency-sensitive applications justifying specialized hardware investments.
8. Balanced Analysis
Strengths with Evidential Support
Parallax demonstrates multiple validated technical strengths positioning it uniquely within the LLM serving landscape. The framework achieves documented performance leadership among decentralized inference systems, with empirical measurements showing 3.1 times latency reduction and 5.3 times inter-token latency improvement versus Petals baseline on Qwen2.5-72B deployments. This performance stems from principled scheduling algorithms addressing NP-hard optimization challenges through decomposition and domain-specific heuristics, contrasted with Petals’ simpler greedy strategies that underperform under bandwidth constraints. Cross-platform heterogeneity support distinguishes Parallax from competitors: successful orchestration of NVIDIA RTX 5090 GPUs alongside Apple M4 Pro devices proves viability of mixed-architecture clusters impossible with CUDA-exclusive or Metal-exclusive frameworks. The pioneering MLX integration brings professional-grade LLM serving to Apple Silicon for the first time, unlocking a massive installed base of M-series devices previously excluded from distributed inference participation. Open-source availability under Apache 2.0 licensing fosters community contributions, academic research integration, and enterprise customization freedoms unattainable with proprietary alternatives, evidenced by GitHub repository activity and research community engagement following publication.
Limitations and Mitigation Strategies
Parallax confronts several inherent limitations characteristic of decentralized systems. Absolute latency remains higher than optimized single-machine inference—Parallax’s 46.6 seconds end-to-end time for Qwen2.5-72B with 4K input and 1024 token output, while superior to Petals’ 143.5 seconds, substantially exceeds sub-second response times achievable with high-end GPUs like H100 running vLLM or TensorRT-LLM. Organizations prioritizing lowest-possible latency for interactive applications therefore require dedicated hardware rather than distributed solutions. Network dependency introduces reliability vulnerabilities absent in standalone deployments: wide-area network partitions, ISP outages, or firewall misconfigurations disrupt distributed inference clusters, necessitating operational expertise in network troubleshooting uncommon in machine learning engineering teams. Setup complexity, while mitigated by frontend interfaces, still demands multi-machine coordination and terminal proficiency exceeding typical cloud API adoption barriers—a SaaS service requires only API key provisioning versus Parallax’s multi-step installation and configuration procedures. Mitigation strategies include deploying Parallax within controlled network environments (corporate intranets, university networks) minimizing wide-area dependencies, utilizing Docker containerization for simplified installation, and starting with small homogeneous clusters before expanding to heterogeneous wide-area topologies. The community’s maturation will likely produce turnkey deployment automation and commercial support offerings addressing current operational complexity.
9. Transparent Pricing
Plan Tiers and Cost Breakdown
Parallax operates under a fundamentally different economic model than traditional cloud-based AI services, reflecting its open-source infrastructure positioning. The framework itself carries zero licensing fees—Apache 2.0 licensing grants unrestricted usage rights for both commercial and non-commercial applications without royalties, subscriptions, or per-query charges. Organizations incur costs exclusively through the infrastructure they already own or choose to deploy: electricity consumption for running nodes, network bandwidth for inter-node communication, and potential hardware purchases if existing inventories prove insufficient. This capital expenditure model contrasts sharply with cloud providers’ operational expenditure pricing based on per-token or per-request consumption. For organizations with existing distributed compute resources, marginal deployment costs approach zero beyond negligible electricity increments during idle-capacity utilization. The absence of vendor lock-in enables organizations to scale infrastructure investments according to internal return-on-investment calculations rather than adapting operations to external pricing structures. However, this model shifts costs toward internal engineering labor for deployment, maintenance, and troubleshooting—hidden operational expenditures often underestimated in total cost of ownership assessments.
Total Cost of Ownership Projections
Comprehensive TCO modeling for Parallax deployments requires accounting for multiple cost categories over typical three-to-five-year planning horizons. Hardware costs vary dramatically based on deployment strategies: organizations activating existing workstation idle capacity incur zero incremental capital expenditure, while purpose-built inference clusters require GPU acquisitions ranging from 1,500 dollars per consumer RTX 4090 to 30,000 dollars per enterprise H100. Electricity consumption for a modest 10-node cluster averaging 300 watts per GPU totals approximately 26,280 kilowatt-hours annually at 24/7 operation, translating to 2,628 dollars at 0.10 dollars per kilowatt-hour industrial rates. Network connectivity costs depend on topology: local area network deployments require negligible incremental bandwidth expenditure, while wide-area clusters may consume terabytes of inter-node traffic monthly, potentially triggering bandwidth charges in metered environments. Personnel costs constitute the dominant TCO component—infrastructure engineers commanding 150,000 dollars annual salaries dedicated half-time to Parallax operations contribute 75,000 dollars annually, dwarfing hardware and electricity expenses. Over a three-year horizon, a 10-node cluster built from existing hardware with half-time operational support totals approximately 232,884 dollars, equivalent to processing 116 million tokens at OpenAI’s GPT-4 rate of 0.002 dollars per thousand input tokens—a break-even point many organizations exceed monthly for production workloads.
10. Market Positioning
Competitor Comparison Analysis
| Framework | Model Coverage | Hardware Support | Pricing Model | Performance | Use Case Focus |
|---|---|---|---|---|---|
| Parallax | 40+ open-source (Qwen, DeepSeek, Llama) | NVIDIA GPU, Apple Silicon, AMD, CPU | Open-source (Apache 2.0), infrastructure costs only | 3.1x faster than Petals, 1.58x avg throughput gain | Decentralized inference, data sovereignty |
| Petals | Limited (BLOOM, Llama variants) | NVIDIA GPU, CPU | Open-source, peer-to-peer contribution | Baseline for decentralized comparison | Collaborative inference, research |
| vLLM | Extensive (most Hugging Face models) | NVIDIA GPU, AMD ROCm | Open-source, infrastructure costs | Industry-leading single-machine performance | Datacenter deployment, low-latency serving |
| TensorRT-LLM | NVIDIA-optimized models | NVIDIA GPU only | Open-source, NVIDIA ecosystem | Highest performance with optimized models | Production deployment on NVIDIA infrastructure |
| OpenAI API | Proprietary (GPT-4, GPT-4o) | N/A (managed service) | Per-token consumption ($0.002-0.06/1K tokens) | Excellent latency and reliability | General-purpose AI applications |
| Together AI | 50+ open models | NVIDIA GPU (managed) | Per-token consumption ($0.0002-0.008/1K tokens) | Competitive with cloud providers | Open-model API access |
Unique Differentiators
Parallax occupies a distinctive position emphasizing sovereignty, heterogeneity, and democratization absent in competing solutions. The framework uniquely enables organizations to retain complete control over model weights, inference data, and deployment topology—a capability impossible with managed API services where data necessarily transits provider infrastructure. Cross-platform support spanning NVIDIA, Apple, and AMD hardware contrasts with vLLM’s NVIDIA-centric design and TensorRT-LLM’s exclusive NVIDIA focus, unlocking deployment scenarios leveraging mixed organizational hardware inventories. The pioneering MLX integration positions Parallax as the sole professional-grade option for distributed inference involving Apple Silicon, tapping the extensive M-series device installed base across enterprises and academic institutions. Open-source availability under permissive licensing enables customization freedoms critical for research applications, regulatory compliance scenarios, and organizations with specialized requirements poorly served by one-size-fits-all commercial offerings. The system’s explicit optimization for decentralized wide-area deployments, incorporating network-aware scheduling and fault-tolerant coordination, addresses use cases fundamentally incompatible with datacenter-optimized frameworks assuming high-bandwidth low-latency fabrics.
11. Leadership Profile
Bios Highlighting Expertise and Awards
Eric Yang serves as founder of Gradient, bringing extensive experience from venture capital investing at HSG (formerly Sequoia Capital China) from 2021 to 2024, where he deployed over 100 million dollars in capital across seed and venture-stage investments including blockchain infrastructure projects like Taiko and AI initiatives like Databeyond. His prior role as founding full-stack engineer at DLive from June 2017 to December 2019 provided hands-on technical experience building content monetization platforms subsequently acquired by BitTorrent. Yang holds a vision for collective intelligence co-owned and co-evolved by populations rather than concentrated in corporate hands, reflected in Gradient’s mission statement: “We believe intelligence should be a public good, not a corporate asset.”
Yuan Gao co-founded Gradient in May 2024 after serving as Head of Growth at Helium Foundation from December 2022 to May 2024, overseeing ecosystem expansion for one of the largest decentralized physical infrastructure networks. His prior role as Managing Director at Nova Labs and Helium Inc from March 2021 to December 2022 demonstrated expertise scaling decentralized wireless networks. Earlier career positions include Head of Marketing at NEO blockchain from December 2018 to April 2021, cultivating strategic positioning during smart contract platform competition, and Business Director at The Beast advertising agency. His educational background spans a Master’s degree in Geographic Information Science from University of Georgia, a Master of International Affairs focusing on International Finance and Economic Policy from Columbia University, and undergraduate study at Nanjing University with exchange experience at Chinese University of Hong Kong. This interdisciplinary foundation combining technical GIS expertise with finance and policy understanding uniquely positions him for decentralized infrastructure leadership.
Patent Filings and Publications
Gradient has published two major research papers establishing academic foundations for its technology stack. The primary Parallax paper titled “Parallax: Efficient LLM Inference Service over Decentralized Environment” (arXiv:2509.26182) details the two-phase scheduling algorithm, empirical performance benchmarks, and architectural decisions enabling heterogeneous distributed serving. Co-authors Chris Tong, Youhe Jiang, Gufeng Chen, Tianyi Zhao, Sibian Lu, Wenjie Qu, Eric Yang, Lynn Ai, and Binhang Yuan represent the core technical team alongside academic collaborators from HKUST and National University of Singapore. A second paper titled “Parallax: Efficient Distributed LLM Inference on Heterogeneous Hardware” expands on heterogeneous orchestration, presenting benchmarks demonstrating 3.1 times latency reduction, 5.3 times inter-token latency improvement, and 3.1 times throughput enhancement over state-of-the-art baselines. The Lattica communication protocol paper “Lattica: A Decentralized Cross-NAT Communication Framework for Scalable AI Inference and Training” (arXiv:2510.00183) authored by Ween Yang, Jason Liu, Suli Wang, Xinyuan Song, Lynn Ai, Eric Yang, and Bill Shi describes the underlying peer-to-peer substrate enabling NAT traversal, content-addressed storage, and DHT-based coordination. These publications establish intellectual foundations while facilitating academic citations and derivative research, contrasting with closed-source competitors guarding architectural details as trade secrets.
12. Community and Endorsements
Industry Partnerships
Gradient’s ten-million-dollar seed funding round announced June 17, 2025 assembled prominent blockchain and crypto-focused venture capital firms as strategic partners. Pantera Capital, a pioneer Bitcoin investment fund managing multi-billion-dollar assets, co-led the round alongside Multicoin Capital, a thesis-driven fund emphasizing decentralized infrastructure investments. HSG (formerly Sequoia Capital China) participated, leveraging its position as one of Asia’s most respected venture institutions with backing of companies including ByteDance, Meituan, and JD.com. This investor consortium signals institutional confidence in decentralized AI infrastructure as an investable category, validating Gradient’s technical approach and market positioning. The funding announcement coincided with Parallax and Lattica protocol launches, suggesting strategic coordination between capital availability and technology maturity milestones. While specific commercial partnerships with enterprises deploying Parallax have not been publicly disclosed as of November 2025—consistent with the framework’s recent launch timeframe—the extensive Sentry Node network demonstrates community engagement, with participants across 190-plus regions contributing to connectivity testing during Season 1 beta operations.
Media Mentions and Awards
Technology media outlets covering Gradient’s funding announcement highlighted the decentralized AI narrative gaining momentum post-DeepSeek R1’s January 2025 release, which demonstrated frontier performance achievable through cost-efficient training methodologies. Publications including PANews, CryptoRank, BeInCrypto, and Gate News emphasized Gradient’s mission to redistribute intelligence ownership from corporate monopolies to public goods infrastructure. The framework’s positioning as “the world’s first fully distributed serving framework” garnered attention within DePIN (Decentralized Physical Infrastructure Networks) discourse, a sector projected to reach 973.6 million dollars market capitalization by 2027 with 164 companies tracked and 104 securing funding by late 2024. Academic recognition emerged through arXiv paper acceptance, conferring scholarly legitimacy and facilitating citation within subsequent research. The ProductHunt launch on October 30, 2025 generated community discussion, though specific rankings or awards have not been announced. Social media engagement on X (formerly Twitter) from Gradient’s official account demonstrates growing follower base, with announcements reaching cryptocurrency, AI research, and developer communities. The absence of major industry awards reflects Parallax’s nascent stage—inaugural deployments typically precede formal recognition by 12-to-18 months as production adoption and case studies accumulate.
13. Strategic Outlook
Future Roadmap and Innovations
Gradient’s public communications outline ambitious expansion trajectories building on Parallax’s foundational capabilities. The company announced plans to “launch new products, publish research papers, and open contribution channels for developers, researchers, and computational contributions in the months ahead” following the June 2025 funding round. Season 1 Sentry Node operations concluded August 28, 2025, transitioning from proof-of-connectivity toward “network intelligence” reward mechanisms valuing substantive data contributions over passive uptime. The Edge Host Pilot Program represents Gradient’s initiative to expand beyond browser-based Sentry Nodes toward dedicated compute contributions from devices with suitable specifications, enabling GPU and high-memory participants to provide inference capacity. Integration with Gradient Cloud—the company’s API platform for building on decentralized infrastructure—positions Parallax as one component within a broader ecosystem strategy encompassing communication (Lattica), inference (Parallax), and orchestration layers. Research priorities include extending MLX optimizations for newer Apple Silicon generations, implementing additional NAT traversal techniques for challenging network topologies, and exploring federated learning extensions enabling privacy-preserving collaborative model training atop Parallax’s distributed coordination substrate.
Market Trends and Recommendations
The decentralized AI infrastructure sector exhibits accelerating momentum driven by converging trends: increasing AI model sizes straining centralized datacenter capacity, growing data sovereignty concerns prompting on-premises deployment preferences, and expanding open-weights model ecosystems enabling self-hosted alternatives to proprietary APIs. DeepSeek V3’s December 2024 release demonstrating competitive performance with dramatically reduced training costs catalyzed reassessment of conventional assumptions equating quality with expenditure, emboldening organizations to consider open-model strategies. Apple’s M-series silicon proliferation created an untapped compute reservoir—millions of high-performance devices owned by knowledge workers operating at low utilization outside business hours—that Parallax specifically targets through MLX optimization. Regulatory developments including EU AI Act requirements for transparency and explainability favor open-source frameworks enabling audit over black-box cloud services, potentially accelerating enterprise Parallax adoption within jurisdictions prioritizing AI governance.
Organizations evaluating Parallax should assess deployment readiness across technical, operational, and strategic dimensions. Technical prerequisites include heterogeneous GPU inventories or committed capital for hardware acquisition, network infrastructure supporting device-to-device communication without restrictive firewall policies, and engineering teams comfortable with command-line deployment and distributed systems troubleshooting. Operational considerations encompass establishing clear ownership for Parallax cluster maintenance, implementing monitoring dashboards tracking node health and inference performance, and developing incident response procedures addressing node failures or network disruptions. Strategic alignment requires clarifying whether data sovereignty, cost optimization through idle capacity utilization, or AI infrastructure experimentation constitute primary motivations—objectives determining success metrics and investment justification. Early adopters willing to tolerate evolving documentation and community-sourced support stand to influence ecosystem development through feedback and contributions, potentially securing competitive advantages as enterprise tooling matures. Conservative organizations may monitor Parallax adoption trajectories over 12-to-24 months, evaluating case study accumulation and commercial support emergence before committing production workloads to the nascent framework.
Final Thoughts
Parallax represents a paradigm shift in large language model inference, challenging centralized cloud orthodoxy through sophisticated distributed systems engineering and heterogeneous hardware orchestration. The framework’s technical achievements—documented performance leadership among decentralized alternatives, pioneering Apple Silicon integration, and cross-platform flexibility—position it as a compelling option for organizations prioritizing data sovereignty, cost optimization, and AI infrastructure independence. Open-source availability under permissive licensing fosters ecosystem development, academic research integration, and community-driven innovation cycles absent in proprietary competitors.
However, Parallax demands realistic assessment of trade-offs inherent in decentralized architectures. Absolute latency remains higher than optimized single-machine deployments, operational complexity exceeds turnkey cloud APIs, and network dependencies introduce reliability considerations uncommon in datacenter environments. Organizations must weigh these limitations against strategic benefits of complete infrastructure control, regulatory compliance facilitation, and capital expenditure models avoiding per-token consumption charges.
The framework’s October 2025 launch positions early adopters at the frontier of decentralized AI infrastructure, with opportunities to shape ecosystem evolution through feedback, contributions, and deployment pattern establishment. As Gradient executes its roadmap—expanding compute network participation, enhancing MLX optimizations, and developing enterprise tooling—Parallax’s accessibility and capabilities will likely improve substantially, potentially transitioning from specialized deployment scenarios toward mainstream adoption among organizations valuing AI sovereignty and operational independence.
For stakeholders evaluating Parallax adoption, the framework merits serious consideration where data sovereignty requirements, existing distributed hardware inventories, or strategic positioning toward decentralized infrastructure align with organizational objectives. The combination of proven technical performance, open-source transparency, and institutional funding backing suggests Parallax will remain a significant player shaping the future of accessible, democratized AI inference.