Table of Contents
Overview
In an era where machine learning promises transformative business value yet consistently fails to deliver—with industry estimates suggesting that up to 87% of data science projects never reach production—a fundamental problem persists. Organizations invest months and millions building ML models only to watch projects collapse under the weight of data preparation complexity, experimentation overhead, and deployment bottlenecks. Plexe emerges as a paradigm shift in this landscape, providing an agentic machine learning platform that transforms natural language problem descriptions into production-ready, deployed models through autonomous ML engineering agents.
Founded by Y Combinator alumni Vaibhav Dubey and Marcello De Bernardi in 2025, Plexe addresses the core friction that prevents ML adoption at scale: the convoluted, time-intensive workflow from messy data to reliable prediction API. Through a self-correcting multi-agent system, Plexe automates the entire ML lifecycle—data connection, feature discovery, model experimentation, evaluation, refinement, and deployment—delivering what traditionally required teams of specialists over months in a matter of hours. This represents not incremental improvement but fundamental reimagining of how organizations can operationalize machine learning.
Key Features
Plexe distinguishes itself through a comprehensive feature set engineered to eliminate traditional ML development barriers while maintaining production-grade quality and transparency.
- Natural Language Model Specification: Define your ML objective in plain English by describing what you want to predict and what data should inform those predictions. Plexe interprets your intent and autonomously translates business requirements into technical ML implementations, making advanced predictive analytics accessible to product managers, analysts, and domain experts without data science backgrounds.
- Autonomous Multi-Agent ML System: Plexe employs a self-correcting team of specialized ML engineering agents that research optimal approaches, conduct systematic experiments across algorithms and hyperparameters, evaluate model quality through rigorous testing, and iteratively refine based on performance metrics. This agentic architecture mirrors how expert ML teams work, but operates continuously without manual intervention.
- Comprehensive Data Connectivity: Connect directly to existing data sources including databases, cloud storage, and business systems. Plexe automatically discovers relevant fields, handles data ingestion, and manages the complexities of joining disparate sources, eliminating weeks of manual data engineering work.
- 50+ Diagnostic and Evaluation Tests: Unlike platforms that optimize for a single metric and declare victory, Plexe runs an extensive diagnostic suite covering data quality checks, model performance across subgroups, feature stability analysis, perturbation robustness testing, statistical confidence intervals, baseline comparisons, fairness assessments, and failure mode detection. This comprehensive evaluation surfaces potential production issues before deployment rather than after customer impact.
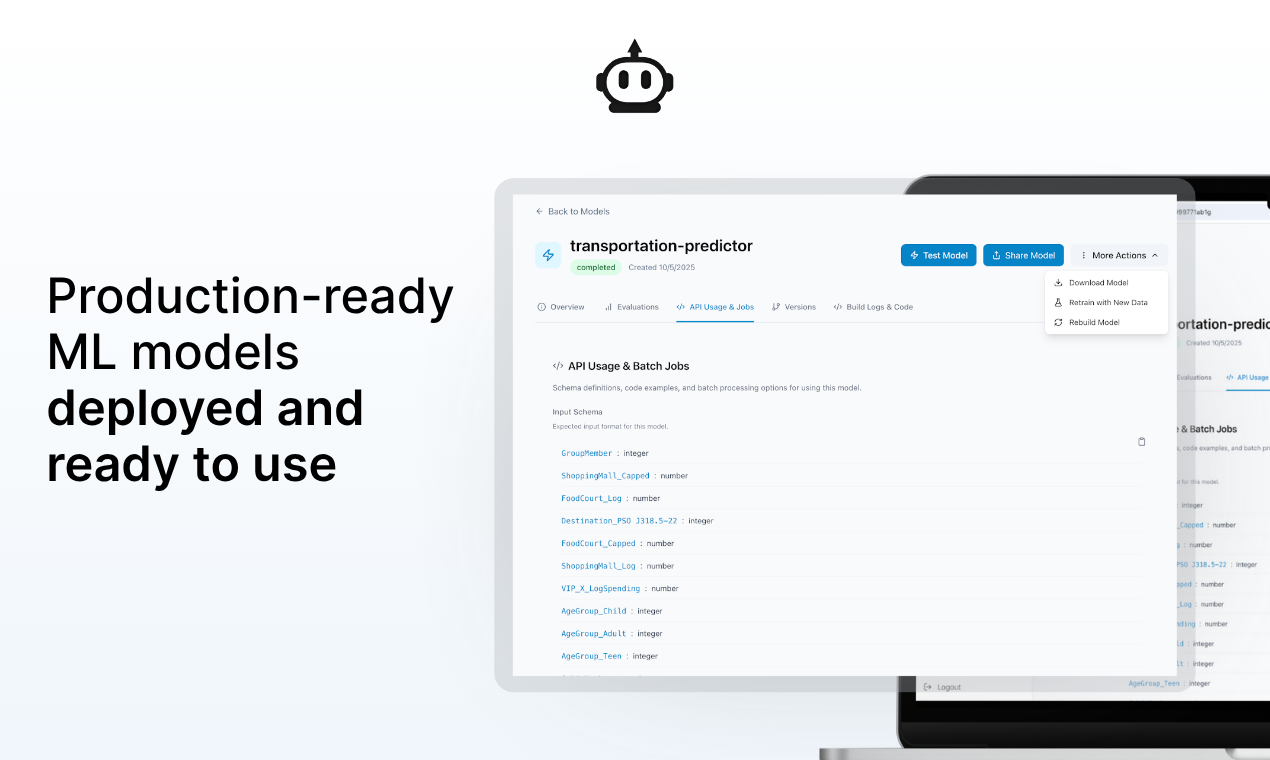
- Production-Ready API Deployment: Models automatically deploy as REST API endpoints with serverless inference, automatic scaling, and enterprise-grade reliability. Integration into applications requires only standard HTTP requests—no complex infrastructure management or MLOps expertise needed.
- Full Transparency and Explainability: Every model comes with complete documentation including training methodology, performance metrics broken down by data segments, feature importance rankings, prediction confidence scores, and human-readable explanations. This transparency enables trust, regulatory compliance, and continuous improvement.
- Self-Hosting Option: For organizations with strict data governance requirements, Plexe offers self-hosted deployment maintaining complete data isolation while preserving the automated workflow benefits.
- Open-Source Foundation: The core Plexe engine is available as an open-source Python library, enabling developers to integrate automated ML capabilities directly into their applications, customize the workflow, and contribute to the platform’s evolution.
How It Works
Plexe transforms the traditionally complex, multi-month ML development process into a streamlined, largely automated workflow accessible through both web interface and programmatic API.
Users begin by connecting their data sources—whether uploading files, linking cloud storage buckets, or connecting directly to production databases. Plexe’s data connectors handle the technical complexities of authentication, schema discovery, and data retrieval. Once data is accessible, users describe their ML objective in natural language: what outcome they want to predict, what success looks like, and any business constraints that should inform model selection.
With the problem specified, Plexe’s multi-agent system activates. The data profiling agent conducts deep analysis to understand data distributions, identify quality issues, detect potential biases, and assess feature relationships. Simultaneously, the feature engineering agent explores transformations, creates derived features, and handles missing values intelligently based on statistical properties rather than simple heuristics.
The experimentation agent then conducts systematic trials across multiple model architectures—from interpretable linear models to sophisticated ensemble methods—comparing performance across your specific data characteristics. Rather than testing randomly, this agent learns from each experiment to guide subsequent trials toward more promising configurations, dramatically accelerating the search for optimal solutions.
Throughout training, the evaluation agent continuously assesses model quality through the comprehensive diagnostic suite, identifying potential failure modes such as poor performance on specific data segments, sensitivity to input noise, or reliance on unstable features. When issues surface, the refinement agent adjusts the approach—trying different algorithms, modifying feature engineering, or tuning hyperparameters—until quality thresholds are met.
Finally, the deployment agent packages the trained model, generates API endpoints, configures scaling policies, and produces complete documentation. The entire process operates autonomously, with users receiving progress updates and the ability to review detailed reports at each stage. The result: from problem description to deployed, production-ready model in hours rather than months, with full transparency into what was built and why.
Use Cases
Plexe’s automation and accessibility enable machine learning adoption across diverse business contexts that previously lacked the resources or expertise for successful ML implementation.
- Rapid MVP and Product Validation: Startups and product teams can validate ML-driven features in hours rather than months, testing whether predictive capabilities deliver user value before committing to full engineering builds. This dramatically reduces the risk and cost of incorporating intelligence into applications.
- Operational Intelligence for SMBs: Small and medium businesses lacking dedicated data science teams can leverage their operational data for churn prediction, demand forecasting, lead scoring, inventory optimization, and fraud detection—use cases that previously required enterprise-scale resources.
- Research and Academic Analysis: Researchers can quickly build models to test hypotheses, analyze experimental results, identify patterns in complex datasets, and validate findings—accelerating discovery cycles without requiring deep ML engineering expertise.
- Enterprise ML Augmentation: Large organizations with established data science teams use Plexe to handle routine modeling tasks, proof-of-concept development, and baseline establishment, freeing senior ML engineers to focus on complex, high-value problems requiring specialized expertise.
- Automated Feature Integration: SaaS and application developers can embed predictive capabilities—recommendation engines, personalization systems, anomaly detection, classification APIs—directly into their products without building entire ML infrastructure and expertise in-house.
- Continuous Model Maintenance: Organizations deploy Plexe to maintain and monitor existing models, automatically detecting performance degradation, data drift, and emerging failure modes that require attention—ensuring production systems remain reliable as data distributions evolve.
Pros \& Cons
Advantages
- Dramatic Time-to-Production Acceleration: Reduces ML development cycles from months to hours or days, enabling 10x faster iteration and dramatically lower opportunity cost for organizations exploring ML applications.
- Comprehensive Model Diagnostics: The 50+ test evaluation suite provides unprecedented transparency into model behavior, surfacing potential production issues that simpler AutoML platforms miss, significantly reducing post-deployment surprises and failures.
- No ML Expertise Barrier: Natural language specification and automated pipeline generation make predictive modeling accessible to domain experts, product managers, and analysts who understand business problems but lack data science training.
- Production-Grade Output: Automated deployment with API endpoints, scaling, and monitoring eliminates the notorious “last mile” problem where promising models fail to reach production due to operationalization complexity.
- Flexible Deployment Options: Choice between managed cloud service and self-hosted deployment addresses both startups seeking simplicity and enterprises requiring data sovereignty and compliance control.
- Open-Source Foundation: The availability of core capabilities as an open-source Python library enables developer customization, integration into existing workflows, and community-driven innovation while avoiding vendor lock-in concerns.
Disadvantages
- Limited to Structured Tabular Data: As of late 2025, Plexe focuses on structured, relational datasets for classification and regression tasks. Support for computer vision, natural language processing, audio analysis, and time-series forecasting remains on the roadmap but is not yet available, limiting applicability for these use cases.
- Reduced Granular Control for ML Experts: The highly automated, opinionated workflow optimizes for speed and accessibility but provides less fine-grained control over model architecture, feature engineering techniques, and hyperparameter spaces compared to code-first frameworks. Expert practitioners seeking maximum customization may find this constraining.
- Governance Features Still Maturing: While core diagnostic capabilities are strong, advanced MLOps features such as continuous drift monitoring with automated retraining, granular data lineage tracking, and CI/CD integration via git hooks are planned but not fully implemented, which may limit adoption by organizations with sophisticated governance requirements.
- Usage-Based Pricing Considerations: The managed platform operates on credit-based pricing tied to model training, prediction volume, and storage. Organizations with extremely high-volume inference requirements or tight budget constraints should carefully evaluate cost projections against their specific usage patterns.
How Does It Compare?
Understanding Plexe’s position requires examining the broader AutoML and MLOps landscape as it exists in late 2025, where multiple categories of solutions address different segments of the ML automation challenge.
DataRobot represents the established enterprise AutoML leader, recognized as a Gartner Magic Quadrant Leader for Data Science and Machine Learning Platforms for multiple consecutive years. DataRobot provides comprehensive end-to-end automation covering data preparation through deployment with strong governance, explainability, and MLOps capabilities. The platform excels in enterprise scenarios requiring extensive model monitoring, compliance documentation, and integration with complex existing infrastructure. However, DataRobot targets large organizations with correspondingly enterprise pricing, steeper learning curves, and configuration overhead that can slow initial adoption. For Fortune 500 companies requiring maximum governance and willing to invest in platform expertise, DataRobot remains compelling. For smaller organizations, startups, or teams seeking rapid prototyping, Plexe’s simpler, more accessible approach with natural language specification offers faster time-to-value.
AWS SageMaker Autopilot provides Amazon’s managed AutoML service within the broader SageMaker ML platform. Autopilot automates feature engineering, algorithm selection, and hyperparameter tuning while maintaining transparency through generated notebooks showing exact transformations and model code. This transparency appeals to ML practitioners who want automation but also need to understand and potentially customize what was built. SageMaker’s strength lies in deep AWS ecosystem integration, making it natural for organizations heavily invested in Amazon cloud services. However, SageMaker requires more AWS-specific knowledge, the user experience prioritizes developers over business users, and the platform’s breadth creates complexity for teams simply wanting automated ML without managing broader infrastructure concerns. Plexe’s natural language interface and fully automated deployment contrast with SageMaker’s more technical, infrastructure-aware approach.
Google Vertex AI AutoML offers Google Cloud’s managed AutoML capabilities integrated with the Vertex AI unified platform. Vertex AI provides strong support for various data types including tabular, image, text, and video, along with access to Google’s foundation models through Model Garden. The platform excels for organizations prioritizing Google Cloud integration, TPU acceleration for large-scale training, and Google’s research-backed model quality. Like SageMaker, Vertex AI assumes cloud platform expertise and targets technical teams comfortable with GCP services. The platform’s comprehensive capabilities come with corresponding complexity in navigation and configuration. For teams already operating primarily in Google Cloud with technical ML expertise, Vertex AI represents a natural choice. Plexe differentiates through its cloud-agnostic stance, simpler interaction model, and focus on making ML accessible to non-specialists.
Azure Machine Learning AutoML delivers Microsoft’s automated machine learning within the Azure ecosystem, offering strong integration with Azure services, Microsoft enterprise tooling, and Power BI for analytics. Azure AutoML supports multiple task types including classification, regression, forecasting, computer vision, and NLP. The platform benefits from Microsoft’s enterprise relationships and hybrid cloud capabilities for organizations with on-premises infrastructure. However, similar to AWS and Google offerings, Azure AutoML assumes familiarity with Azure services and targets technical practitioners within the Microsoft ecosystem. Plexe’s platform-agnostic approach and emphasis on natural language accessibility provide an alternative for teams not deeply committed to a specific cloud vendor or lacking extensive Azure expertise.
H2O Driverless AI stands as a specialized AutoML platform emphasizing maximum model performance through sophisticated feature engineering, ensemble techniques, and extensive algorithm exploration. H2O excels in competitive scenarios where model accuracy is paramount—such as Kaggle competitions or high-stakes business problems where fractional accuracy improvements justify additional complexity. The platform provides strong interpretability tools, comprehensive documentation for regulatory compliance, and flexibility for expert ML practitioners. H2O’s strength in pure model performance comes with steeper learning curves and requires more ML expertise to fully leverage compared to newer, more accessible platforms. Organizations with skilled data science teams seeking maximum predictive accuracy may prefer H2O, while those prioritizing rapid deployment and accessibility will find Plexe’s agent-based automation more aligned with their needs.
Obviously AI and Akkio represent newer no-code AutoML platforms targeting business users with minimal technical backgrounds. Both emphasize natural language interaction, spreadsheet-like data manipulation, and rapid model building for common business use cases like lead scoring, churn prediction, and sales forecasting. These platforms share Plexe’s vision of ML accessibility but differ in depth of automation and diagnostic rigor. Plexe’s multi-agent system and comprehensive 50+ test evaluation suite provide more sophisticated model vetting compared to simpler accuracy metrics, while the self-hosted deployment option addresses enterprise needs that pure SaaS offerings cannot meet. For business analysts requiring basic predictive models with minimal configuration, Obviously AI or Akkio may suffice. For teams needing production-grade reliability, comprehensive diagnostics, and deployment flexibility, Plexe offers more robust capabilities.
Important Clarification: Runway is Not a Competitor. The original content incorrectly listed “Runway” as a machine learning platform competitor. Runway (RunwayML) is an AI-powered creative platform focused on generative video and image creation for artists, filmmakers, and content creators. Runway specializes in text-to-video generation, video editing, and creative AI tools—an entirely different market segment from automated machine learning for predictive modeling. This represents a significant factual error in the original comparison that has been corrected here.
Plexe’s distinctive positioning emerges at the intersection of accessibility, automation depth, and production readiness. Where established enterprise platforms like DataRobot, SageMaker, Vertex AI, and Azure ML provide comprehensive capabilities but require significant expertise and infrastructure investment, and where simpler no-code tools like Obviously AI and Akkio prioritize ease of use but offer less sophisticated automation and diagnostics, Plexe aims for a middle path: natural language accessibility for non-experts combined with agent-based automation sophisticated enough to handle real production requirements. This positioning makes Plexe particularly compelling for startups building ML-powered products, SMBs operationalizing their data, research teams accelerating analysis, and enterprise ML augmentation for routine modeling tasks—use cases where speed, accessibility, and reliable automation matter more than maximum customization or integration with specific cloud ecosystems.
Final Thoughts
Plexe represents a meaningful evolution in how organizations can operationalize machine learning, addressing the persistent gap between ML’s theoretical promise and practical reality. The platform’s core insight—that ML development bottlenecks lie primarily in repetitive, formulaic work amenable to automation rather than fundamental algorithmic innovation—has enabled creation of an agentic system that genuinely accelerates time-to-production while maintaining quality and transparency.
The multi-agent architecture distinguishes Plexe from earlier AutoML generations. Rather than simply trying algorithms until something works, the system conducts systematic research, learns from experiments, and self-corrects based on comprehensive diagnostics—mirroring how expert ML teams approach problems but operating continuously without human fatigue or context switching. This agent-based approach, combined with natural language specification and automated deployment, creates a genuinely end-to-end solution that non-specialists can use effectively.
The comprehensive diagnostic suite represents another crucial differentiator. In production ML, the difference between a model that appears to work in testing and one that reliably performs across diverse real-world scenarios often determines project success or failure. Plexe’s 50+ tests systematically probe for common failure modes—subgroup performance degradation, sensitivity to noise, feature instability, fairness issues—that simpler platforms optimizing solely for aggregate accuracy miss. This thoroughness significantly reduces the risk of deploying models that fail unexpectedly under production conditions.
However, prospective users should carefully evaluate current limitations against their specific requirements. The focus on structured tabular data means organizations needing computer vision, NLP, or time-series capabilities must look elsewhere or wait for roadmap features. The reduced granular control, while enabling accessibility, may frustrate expert practitioners accustomed to code-first workflows and maximum customization. And while governance features are solid, organizations with highly sophisticated MLOps requirements should assess whether current capabilities meet their compliance and monitoring needs.
The availability of both managed cloud service and self-hosted deployment options, along with the open-source foundation, demonstrates thoughtful consideration of diverse organizational needs—from startups prioritizing simplicity to enterprises requiring data sovereignty. This flexibility, combined with transparent, usage-based pricing, lowers adoption barriers compared to platforms requiring enterprise sales cycles and substantial upfront commitments.
As machine learning continues its evolution from specialized expertise to broadly accessible capability, platforms that successfully balance automation depth with usability will increasingly define how organizations leverage their data. Plexe’s agent-based approach, natural language accessibility, comprehensive diagnostics, and production-focused automation position it as a significant player in this transition—particularly for the vast middle market of organizations that understand ML’s value but lack the specialized talent and infrastructure resources of technology giants. For these teams, Plexe offers a practical path from data to deployed predictions that genuinely delivers on AutoML’s longstanding but often unfulfilled promise: making machine learning work for everyone.