Overview
In the ever-evolving landscape of AI, large language models (LLMs) are becoming increasingly vital. But what if you could fine-tune open-source LLMs to outperform even the mighty GPT-4, especially when working with limited data? Enter Predibase’s Reinforcement Fine-Tuning (RFT) platform, a powerful tool designed to do just that. This review will delve into its features, functionality, and how it stacks up against the competition.
Key Features
Predibase’s RFT platform boasts a compelling set of features, making it a strong contender in the LLM fine-tuning space:
- Reinforcement Fine-Tuning for LLMs: The core functionality, allowing users to leverage reinforcement learning techniques to optimize LLM performance.
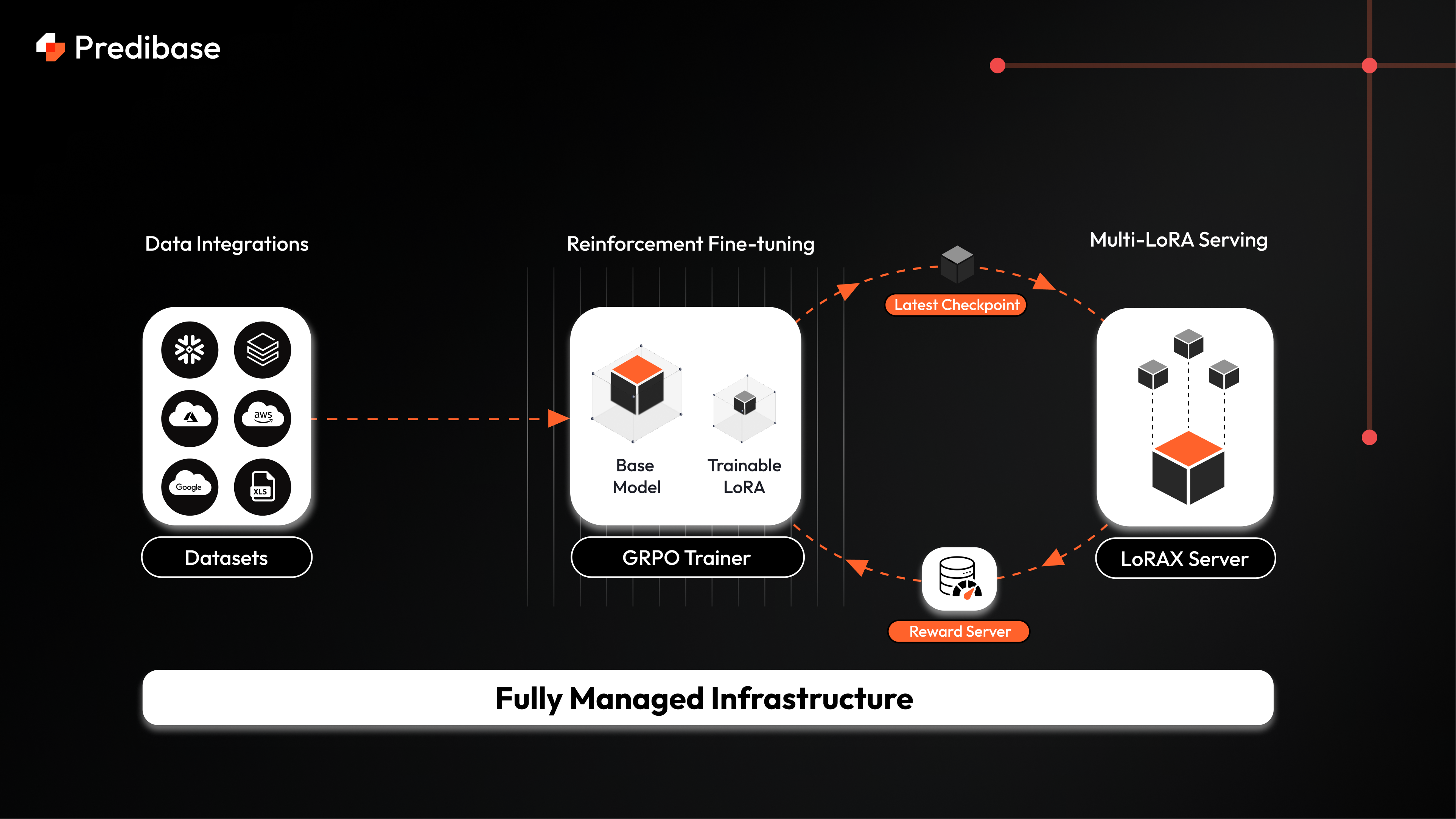
- Compatibility with Open-Source Models: Unlike some platforms, Predibase focuses on empowering users to fine-tune open-source models, providing greater control and transparency.
- Performance Exceeding GPT-4 in Low-Data Settings: A bold claim, but a key differentiator for those working with limited datasets.
- Fully Managed Platform: Simplifies the fine-tuning process by handling the underlying infrastructure, allowing users to focus on model development.
- Advanced RLHF Techniques: Incorporates sophisticated Reinforcement Learning from Human Feedback methods to align models with desired behaviors.
How It Works
The beauty of Predibase’s RFT lies in its relatively straightforward approach to complex reinforcement learning. Users begin by selecting a base LLM from a range of compatible open-source options. Next, they define reward functions that guide the model towards desired behaviors. Finally, they initiate the reinforcement fine-tuning process through RFT’s intuitive interface. The system then optimizes the model’s responses by learning from interactions and feedback, rather than relying solely on labeled data. This iterative process allows for precise control over the model’s output and alignment with specific goals.
Use Cases
Predibase’s RFT platform opens up a wide array of possibilities for various applications:
- Custom LLMs for Enterprise Applications: Tailor LLMs to specific business needs, ensuring accurate and relevant responses for internal tools and customer interactions.
- Research in Low-Resource NLP: Explore language modeling in scenarios where labeled data is scarce, enabling advancements in less-represented languages and domains.
- Enhancing Model Alignment with Business-Specific Goals: Align LLM behavior with unique company values and objectives, ensuring responsible and ethical AI deployment.
- RL Experiments for Language Models: Provide a platform for researchers to experiment with different RL techniques and explore the potential of reinforcement learning in language modeling.
Pros & Cons
Like any tool, Predibase’s RFT has its strengths and weaknesses. Let’s break them down:
Advantages
- Enables superior model performance with minimal data, making it ideal for resource-constrained projects.
- Fully managed infrastructure reduces the burden of managing complex RL pipelines.
- Flexible and customizable, allowing users to tailor the fine-tuning process to their specific needs.
Disadvantages
- May require some understanding of reinforcement learning principles to effectively define reward functions.
- Currently focused primarily on LLMs, limiting its applicability to other types of models.
How Does It Compare?
When considering alternatives, it’s important to understand how Predibase’s RFT stacks up against the competition. OpenAI offers powerful LLMs, but requires access to their proprietary platform, limiting customization and control. Hugging Face provides fine-tuning tools, but lacks the integrated reinforcement learning platform offered by Predibase. This makes Predibase a compelling choice for those seeking open-source flexibility and advanced RLHF capabilities.
Final Thoughts
Predibase’s Reinforcement Fine-Tuning platform presents a promising solution for organizations looking to leverage the power of reinforcement learning to fine-tune open-source LLMs. Its ability to achieve impressive performance with limited data, coupled with its fully managed infrastructure, makes it a valuable tool for both researchers and enterprises alike. While some understanding of RL principles is beneficial, the platform’s user-friendly interface and comprehensive features make it a worthwhile investment for those seeking to push the boundaries of LLM performance.
https://predibase.com