
Table of Contents
Overview
In the ever-evolving landscape of artificial intelligence, multimodal models are rapidly becoming the gold standard. Enter Qwen2.5-Omni, a powerful contender developed by the Qwen team at Alibaba Cloud. This isn’t just another AI; it’s a versatile tool capable of understanding and generating content across text, images, audio, and even video. Let’s dive into what makes Qwen2.5-Omni a noteworthy addition to the AI toolkit.
Key Features
Qwen2.5-Omni boasts a robust set of features designed to handle a wide range of tasks:
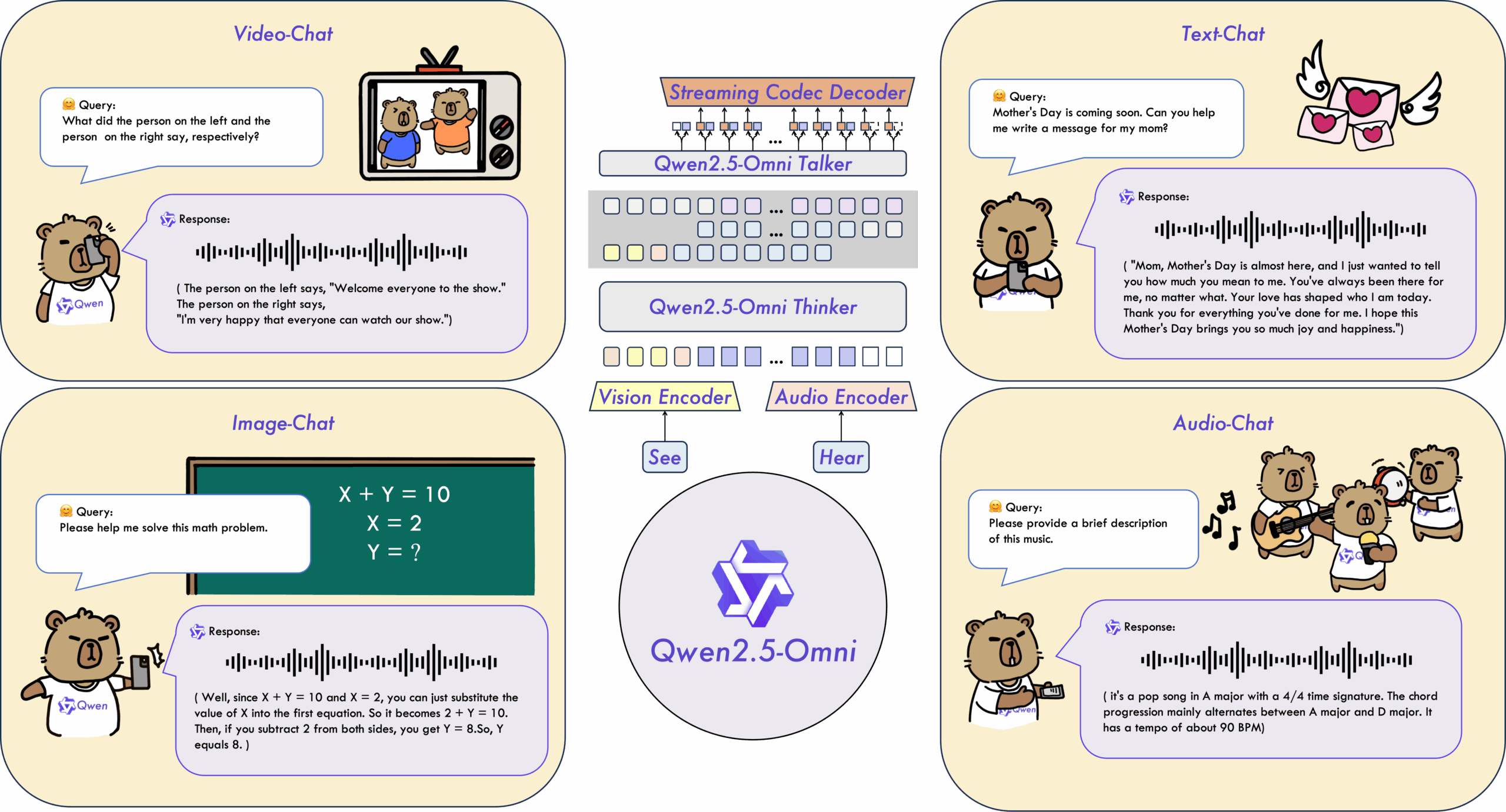
- Multimodal Understanding (text, image, audio, video): Seamlessly processes and interprets information from various sources, allowing for a more holistic understanding of the input.
- Natural Text Generation: Creates human-like text that is coherent, contextually relevant, and engaging.
- Real-time Speech Synthesis: Generates speech in real-time, enabling interactive and dynamic applications.
- End-to-End Deep Learning Architecture: Streamlines the AI pipeline, optimizing performance and efficiency.
How It Works
So, how does Qwen2.5-Omni achieve this multimodal mastery? The model utilizes transformer-based architectures tailored for each modality – text, image, audio, and video. These individual models process their respective inputs and generate embeddings, which are then merged for unified processing. This unified representation allows Qwen2.5-Omni to understand the relationships between different modalities and generate coherent outputs. The model is trained on diverse datasets to ensure general-purpose comprehension and generation capabilities.
Use Cases
The versatility of Qwen2.5-Omni opens doors to a multitude of applications:
- AI Assistants: Powering more intuitive and responsive virtual assistants that can understand and respond to a wider range of user inputs.
- Content Creation Tools: Assisting in the creation of diverse content formats, from generating image captions to creating video scripts.
- Educational Applications: Providing personalized learning experiences through interactive multimedia content and adaptive feedback.
- Multimedia Analysis: Analyzing and extracting insights from multimedia data, such as identifying objects in images or transcribing audio recordings.
- Accessibility Enhancements: Creating tools that make multimedia content more accessible to individuals with disabilities, such as generating audio descriptions for videos.
Pros & Cons
Like any powerful tool, Qwen2.5-Omni has its strengths and weaknesses.
Advantages
- Versatile Input/Output Support: Handles a wide range of modalities, making it adaptable to various applications.
- Open-Source Availability: Fosters collaboration and allows for community-driven development and improvement.
- Backed by Alibaba Cloud: Provides access to robust infrastructure and resources.
Disadvantages
- High Computational Requirements: Demands significant processing power, potentially limiting accessibility for some users.
- Limited Fine-tuning Options for Custom Domains: May require significant effort to adapt the model to specific industry needs or niche applications.
How Does It Compare?
When considering multimodal AI models, Qwen2.5-Omni faces stiff competition. GPT-4V offers broader ecosystem support and a more mature development environment. Gemini, with its tight integration with Google services, provides seamless access to a vast array of tools and data. The choice between these models often depends on specific project requirements and existing infrastructure.
Final Thoughts
Qwen2.5-Omni represents a significant step forward in the realm of multimodal AI. Its ability to process and generate content across various modalities makes it a valuable tool for a wide range of applications. While it may have some limitations, its open-source nature and backing from Alibaba Cloud position it as a promising contender in the ever-evolving AI landscape. As the technology matures, we can expect even more innovative applications to emerge, further solidifying the importance of multimodal AI in our daily lives.