Table of Contents
Overview
In the rapidly evolving landscape of AI-powered text generation, the fundamental limitations of autoregressive models—which generate text sequentially, token by token—have become increasingly apparent as demand for real-time, high-throughput applications grows. Enter Seed Diffusion Preview, a groundbreaking experimental open-source diffusion language model developed by ByteDance’s Seed team that represents a paradigm shift in how AI systems approach text generation. Rather than following the traditional left-to-right sequential approach, Seed Diffusion employs a sophisticated diffusion-based architecture that generates text through iterative refinement, achieving remarkable speed improvements while maintaining competitive quality.
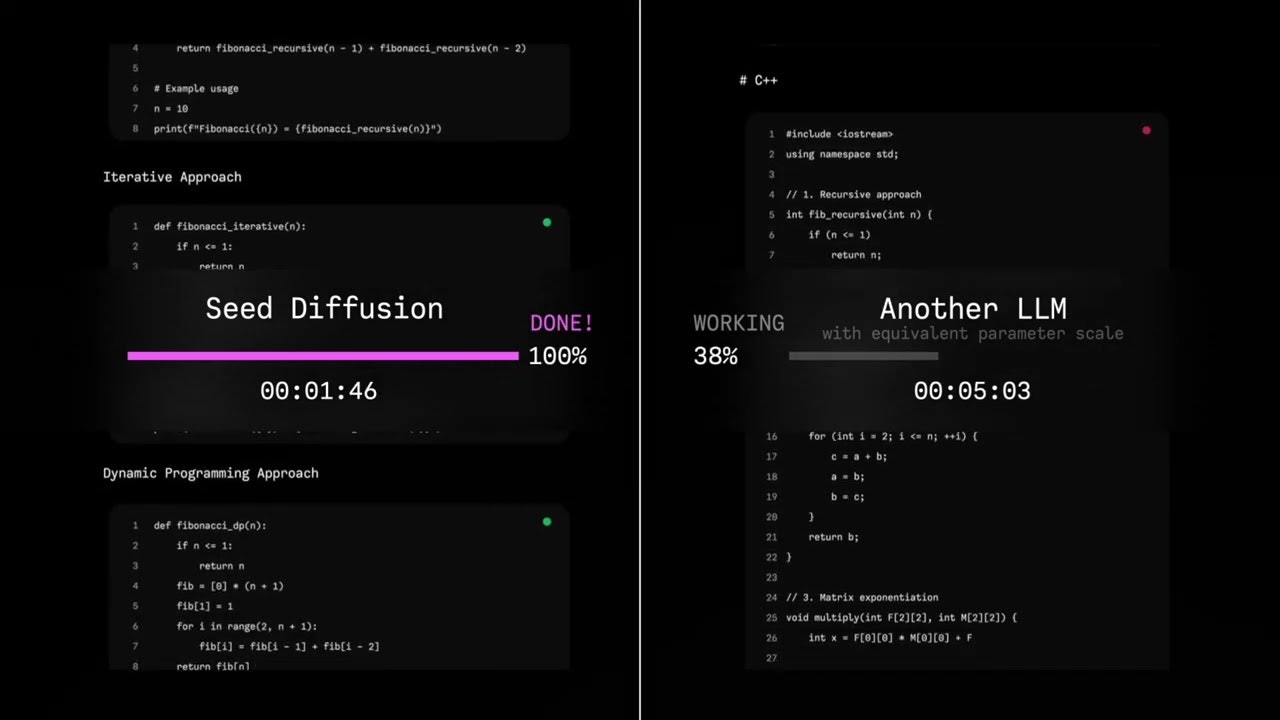
Released in August 2025 as part of ByteDance’s broader research initiative into next-generation language modeling, Seed Diffusion Preview demonstrates that diffusion models—which have revolutionized image and video generation—can be successfully adapted for discrete language tasks. The model achieves an unprecedented inference speed of 2,146 tokens per second on H20 GPUs, representing a 5.4x acceleration over comparable autoregressive models while maintaining strong performance across standard code evaluation benchmarks.
This breakthrough addresses two critical challenges that have long hindered the adoption of diffusion models in natural language processing: the inefficiency of modeling token order and the computational overhead of iterative denoising. Through innovative techniques including two-stage curriculum learning and block-level parallel sampling, Seed Diffusion Preview establishes new possibilities for high-speed, controllable text generation.
Key Features
Seed Diffusion distinguishes itself through a carefully engineered set of capabilities that leverage the unique advantages of diffusion-based text generation:
- Open-source diffusion architecture: Released under the Elastic License 2.0, providing full transparency and enabling community-driven development while maintaining commercial viability. The complete model architecture, training methodology, and implementation details are publicly available, fostering collaboration and accelerating research in diffusion-based language modeling.
- Specialized code generation optimization: Unlike general-purpose language models, Seed Diffusion is specifically engineered for structured code generation tasks, incorporating domain-specific optimizations that understand programming language syntax, semantic relationships, and common coding patterns to produce higher-quality, more contextually appropriate code outputs.
- Revolutionary inference speed: Achieves 2,146 tokens per second on H20 GPUs, representing a 5.4x speedup over comparable autoregressive models through parallel token generation and sophisticated denoising algorithms that eliminate the sequential bottlenecks inherent in traditional language models.
- Two-Stage Curriculum (TSC) training: Employs a sophisticated training methodology that begins with mask-based forward processes for 80% of training steps, gradually replacing tokens with special mask tokens, followed by edit-based forward processes for the remaining 20%, incorporating insertion, deletion, and substitution operations to improve calibration and eliminate repetitive behavior.
- Block-level parallel diffusion sampling: Implements a semi-autoregressive approach that maintains causal ordering between blocks while enabling parallel generation within blocks, optimizing the balance between generation quality and computational efficiency through intelligent block partitioning and KV-caching strategies.
- Advanced denoising methodology: Utilizes discrete-state diffusion processes specifically adapted for language modeling, employing transition matrices and edit-distance-based corruption that better preserves linguistic structure compared to continuous-space approaches, resulting in more coherent and contextually appropriate text generation.
- Trajectory space optimization: Incorporates constrained-order diffusion that guides the model to understand correct dependencies by introducing structured priors specific to code generation, improving the model’s ability to generate syntactically correct and functionally coherent programming constructs.
- On-policy diffusion learning: Optimizes the number of generation steps through iterative improvement strategies that enhance inference speed without sacrificing output quality, enabling practical deployment in latency-sensitive applications.
How It Works
Seed Diffusion operates through a sophisticated multi-stage process that fundamentally reimagines how language models approach text generation. Rather than the traditional sequential token prediction employed by autoregressive models, Seed Diffusion uses a diffusion-based approach that models text generation as a gradual denoising process, similar to the techniques that have proven successful in image generation.
The process begins with the Two-Stage Curriculum (TSC) training methodology, which addresses the critical challenge of applying diffusion models to discrete text data. During the first 80% of training steps, the model employs a mask-based forward process where original text sequences are gradually corrupted by randomly replacing tokens with special mask tokens according to a carefully designed noise schedule. This process treats each token position independently, allowing the model to learn how to reconstruct missing information from surrounding context.
For the final 20% of training, Seed Diffusion transitions to an edit-based forward process that introduces more sophisticated corruption patterns including insertions, deletions, and substitutions. This phase is crucial for improving the model’s calibration and eliminating problematic behaviors like repetition that can plague diffusion models. The edit operations are controlled by Levenshtein distance metrics, ensuring that the corruption process maintains meaningful relationships between the original and corrupted sequences.
During inference, Seed Diffusion employs block-level parallel diffusion sampling, a novel approach that balances generation quality with computational efficiency. Rather than generating all tokens simultaneously or completely sequentially, the model divides the output into blocks and generates tokens within each block in parallel while maintaining causal dependencies between blocks. This semi-autoregressive approach leverages KV-caching for previously generated blocks, enabling efficient conditioning of subsequent blocks without significant quality degradation.
The denoising process itself involves iterative refinement where the model progressively “cleans up” corrupted input to produce coherent, high-quality code. Each denoising step involves the full transformer architecture making predictions about what the original clean text should be, with the process continuing until the output converges to a stable, high-quality result. This approach enables the model to make global corrections and improvements that would be impossible with purely sequential generation.
Use Cases
Seed Diffusion’s unique combination of speed, quality, and architectural innovation makes it valuable across a diverse range of applications, particularly in scenarios where traditional autoregressive models face limitations:
- High-speed code completion and generation: Development environments requiring real-time code suggestions, automatic boilerplate generation, and rapid prototyping benefit significantly from Seed Diffusion’s 5.4x speed improvement, enabling more responsive and interactive coding experiences that keep pace with developer thought processes.
- AI-powered development workflows: Integrated development environments, code review systems, and automated refactoring tools can leverage Seed Diffusion’s parallel generation capabilities to provide immediate feedback and suggestions, transforming traditional development workflows into highly interactive, AI-augmented processes.
- Large-scale code synthesis and transformation: Enterprise applications requiring bulk code generation, legacy system modernization, or cross-language translation benefit from Seed Diffusion’s ability to maintain global coherence while generating large volumes of code efficiently, reducing project timelines and development costs.
- Advanced research in diffusion-based language modeling: Academic and industrial researchers exploring alternatives to autoregressive architectures can use Seed Diffusion as a foundation for investigating novel approaches to text generation, controllable generation, and the intersection of discrete and continuous modeling techniques.
- Latency-sensitive AI applications: Real-time applications including chatbots, interactive code assistants, and live coding demonstrations where response time directly impacts user experience can leverage Seed Diffusion’s speed advantages to provide more immediate and engaging interactions.
- Comparative benchmarking and evaluation: AI researchers and practitioners can use Seed Diffusion as a benchmark for evaluating the efficiency and performance of alternative language modeling approaches, particularly for code generation tasks where quality and speed are both critical factors.
- Edge computing and resource-constrained environments: Scenarios where computational resources are limited but high-quality text generation is still required can benefit from Seed Diffusion’s efficient architecture, which achieves superior performance per computational unit compared to traditional approaches.
- Educational and demonstration purposes: Computer science educators and AI researchers can use Seed Diffusion to demonstrate advanced concepts in machine learning, natural language processing, and the evolution of language modeling architectures, providing hands-on experience with cutting-edge techniques.
Pros \& Cons
Understanding Seed Diffusion’s strengths and current limitations provides insight into its optimal deployment scenarios and areas for future development.
Advantages
- Exceptional inference speed: The 2,146 tokens per second throughput represents a fundamental advancement in language model efficiency, making real-time applications and high-throughput scenarios practical in ways that were previously impossible with traditional autoregressive models.
- Strong performance maintenance: Despite the dramatic speed improvements, Seed Diffusion maintains competitive performance on standard code generation benchmarks, demonstrating that speed gains don’t come at the expense of output quality or correctness.
- Open-source accessibility: The Elastic License 2.0 availability ensures that researchers, developers, and organizations can access, modify, and build upon the model without proprietary restrictions, fostering innovation and enabling community-driven improvements.
- Architectural innovation: The diffusion-based approach represents a genuine paradigm shift that addresses fundamental limitations of sequential generation, opening new research directions and application possibilities that extend beyond simple speed improvements.
- Specialized domain optimization: The focus on code generation ensures that the model understands programming-specific patterns, syntax, and semantic relationships better than general-purpose models, resulting in more accurate and useful code outputs.
- Parallel generation capabilities: The ability to generate multiple tokens simultaneously enables new types of applications and interaction patterns that are fundamentally impossible with sequential generation approaches.
Disadvantages
- Experimental maturity level: As a preview release from August 2025, Seed Diffusion represents cutting-edge research that may lack the stability, comprehensive documentation, and battle-tested reliability of more mature language modeling approaches.
- Limited ecosystem integration: The relatively new diffusion-based approach means fewer existing tools, libraries, and integration frameworks compared to the extensive ecosystem built around autoregressive models like GPT and BERT architectures.
- Specialized hardware requirements: Optimal performance requires access to H20 GPUs and sophisticated infrastructure setups, potentially limiting accessibility for individual researchers or smaller organizations with limited computational resources.
- Code-specific optimization trade-offs: The specialization for code generation, while beneficial for programming tasks, may limit the model’s effectiveness for general-purpose text generation applications compared to more broadly trained alternatives.
- Learning curve for implementation: Teams familiar with traditional autoregressive models may require significant time investment to understand and effectively implement diffusion-based approaches, potentially slowing adoption in production environments.
- Limited long-term evaluation: The recent release means less extensive real-world testing and evaluation compared to established models, creating uncertainty about performance in diverse, production-scale scenarios.
How Does It Compare?
To understand Seed Diffusion’s unique position in the rapidly evolving landscape of 2025, it’s essential to examine how it compares with both emerging diffusion language models and established autoregressive approaches.
Google’s Gemini Diffusion represents the current pinnacle of commercial diffusion language model development, achieving 1,479 tokens per second with performance parity to autoregressive models across general language tasks. While Gemini Diffusion demonstrates broader applicability and commercial polish, Seed Diffusion’s 2,146 tokens per second represents a significant speed advantage specifically for code generation tasks. Gemini Diffusion’s strength lies in its comprehensive evaluation across diverse benchmarks, while Seed Diffusion’s specialization enables superior performance in programming-specific scenarios.
Mercury Coder from Inception Labs pioneered commercial-scale diffusion language models for code generation, operating at over 1,000 tokens per second on NVIDIA H100s. Mercury Coder established the viability of diffusion approaches for code generation and demonstrated competitive performance with autoregressive models. Seed Diffusion advances this foundation with superior speed (2,146 vs 1,000+ tokens/s) and open-source availability, making cutting-edge diffusion techniques accessible to the broader research community rather than being limited to commercial deployment.
TESS 2 represents advancement in general instruction-following diffusion models, matching and sometimes exceeding autoregressive models while providing improved inference-time compute control. While TESS 2 focuses on general language understanding and instruction following, Seed Diffusion’s code-specific optimizations make it more suitable for programming applications, though less versatile for general text generation tasks.
LaViDa extends diffusion models into multimodal domains, achieving competitive performance with autoregressive vision-language models while offering unique advantages in controllability and bidirectional reasoning. LaViDa’s multimodal capabilities represent a different evolutionary path from Seed Diffusion’s code specialization, demonstrating the versatility of diffusion approaches across different AI applications.
DiffuGPT and DiffuLLaMA demonstrate that existing autoregressive models can be successfully converted to diffusion architectures using less than 200B tokens for training. These approaches provide a pathway for leveraging existing model investments while gaining diffusion advantages. Seed Diffusion’s ground-up design for diffusion may provide better optimization for the diffusion paradigm, while conversion approaches offer more immediate practical deployment options.
GitHub Copilot remains the industry-standard autoregressive code generation tool with extensive IDE integration and proven real-world performance. While Copilot offers broader language support and mature ecosystem integration, Seed Diffusion’s speed advantages could enable new types of interactive coding experiences that aren’t practical with Copilot’s sequential generation approach.
CodeQwen 1.5 and DeepSeek-Coder V2 represent the current state-of-the-art in autoregressive code generation, offering strong performance across diverse programming tasks. These models benefit from extensive training data and mature optimization techniques, but are fundamentally limited by sequential generation bottlenecks that Seed Diffusion bypasses through its parallel approach.
Codestral-22B from Mistral AI demonstrates that specialized autoregressive models can achieve excellent code generation performance through focused training and architectural optimization. While Codestral offers proven reliability and comprehensive language support, Seed Diffusion’s diffusion approach enables capabilities like global error correction and parallel refinement that are impossible with autoregressive architectures.
Seed Diffusion’s unique positioning lies in its combination of open-source accessibility, specialized code generation optimization, and groundbreaking speed performance. Unlike commercial solutions that limit access to cutting-edge techniques, or general-purpose models that sacrifice specialization for breadth, Seed Diffusion provides researchers and developers with unrestricted access to state-of-the-art diffusion language modeling specifically optimized for programming tasks.
This positioning makes Seed Diffusion particularly valuable for research institutions, open-source projects, and organizations seeking to push the boundaries of AI-assisted development without being constrained by commercial licensing or general-purpose model limitations. As the field continues to evolve, Seed Diffusion’s open-source foundation enables community-driven improvements and innovations that could accelerate the broader adoption of diffusion-based language modeling.
Final Thoughts
Seed Diffusion Preview represents a watershed moment in the evolution of language modeling, demonstrating that diffusion-based approaches can not only match autoregressive models in quality but dramatically surpass them in speed for specialized applications. ByteDance’s decision to release this groundbreaking technology as open-source under the Elastic License 2.0 ensures that the broader AI community can build upon these innovations, potentially accelerating the transition from sequential to parallel text generation paradigms.
The model’s achievement of 2,146 tokens per second while maintaining competitive performance on code generation benchmarks validates years of research into applying diffusion techniques to discrete language tasks. This breakthrough addresses fundamental scalability challenges that have limited the practical deployment of AI-powered development tools, opening possibilities for more responsive, interactive, and capable coding assistants.
Perhaps more significantly, Seed Diffusion’s success demonstrates that the techniques responsible for the revolution in image and video generation can be successfully adapted for natural language processing. The two-stage curriculum learning, block-level parallel sampling, and trajectory space optimization represent genuine innovations that advance our understanding of how to effectively train and deploy diffusion models for text generation.
For researchers and practitioners in AI-assisted development, Seed Diffusion offers both immediate practical value and long-term strategic insights. The immediate benefits include dramatically improved response times for code generation tasks and the ability to explore new interaction paradigms enabled by parallel generation. The strategic implications extend to the broader future of language modeling, where diffusion approaches may eventually challenge the dominance of autoregressive architectures across all text generation applications.
However, the model’s experimental status and code-specific optimization also highlight important considerations. Organizations evaluating Seed Diffusion should carefully assess their specific use cases, infrastructure requirements, and risk tolerance for cutting-edge technology. The model’s specialization for code generation, while beneficial for programming applications, may limit its utility for teams requiring general-purpose text generation capabilities.
As the AI community continues to grapple with the computational and environmental costs of increasingly large language models, approaches like Seed Diffusion that achieve superior performance through architectural innovation rather than pure scale become increasingly valuable. The model’s efficiency gains suggest a path toward more sustainable AI development that doesn’t rely solely on ever-increasing computational resources.
Looking forward, Seed Diffusion’s open-source foundation positions it to serve as a catalyst for broader innovation in diffusion-based language modeling. As researchers and developers build upon its techniques, adapt its approaches to new domains, and integrate its innovations with other architectural advances, we can expect to see continued evolution in how AI systems approach text generation.
For the AI development community, Seed Diffusion represents both a powerful tool for immediate use and a glimpse into the future of language modeling. Its combination of groundbreaking performance, architectural innovation, and open accessibility makes it an essential resource for anyone serious about pushing the boundaries of AI-assisted development and understanding the next generation of language modeling techniques.
https://seed.bytedance.com/en/seed_diffusion