
Overview
Planning your self-hosted Large Language Model infrastructure requires precise calculations rather than costly guesswork. SelfHostLLM emerges as an essential open-source tool that transforms this complex challenge into a straightforward process, helping AI engineers and organizations accurately calculate GPU memory requirements and estimate maximum concurrent requests for various self-hosted LLM inference scenarios. Supporting an extensive range of popular models including Llama, Qwen, DeepSeek, Mistral, and many others, SelfHostLLM empowers teams to plan their AI infrastructure efficiently, ensuring optimal hardware alignment with workload demands while avoiding both under-provisioning and expensive over-investment.
Key Features
SelfHostLLM delivers comprehensive functionality specifically designed for efficient AI infrastructure planning and capacity estimation.
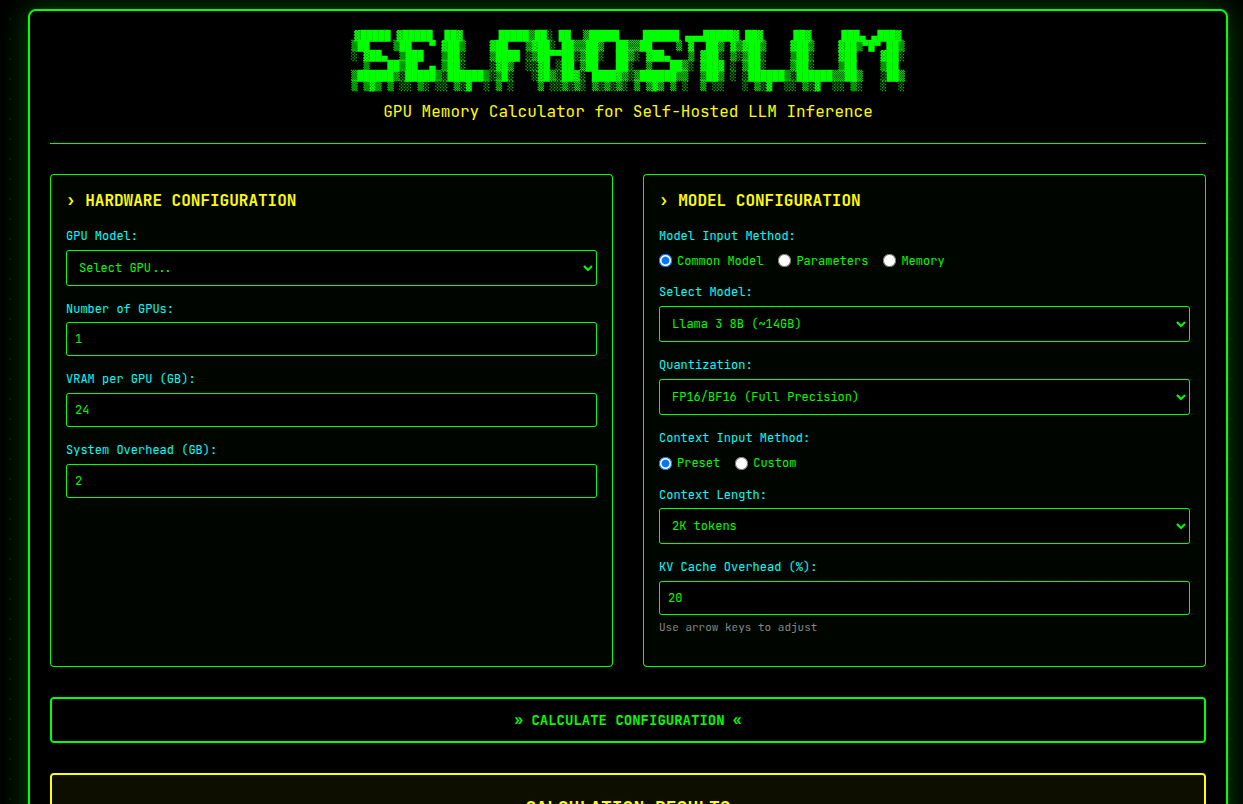
- Precise GPU memory requirement calculator: Accurately estimates VRAM needs for specific LLM models and configurations using proven mathematical formulas, preventing costly under-provisioning or wasteful over-provisioning of GPU resources.
- Maximum concurrent request estimation: Provides detailed insights into simultaneous inference capacity using the formula Max Requests = Available Memory / KV Cache per Request, crucial for accurate capacity planning and performance optimization.
- Comprehensive model support: Offers broad compatibility with major open-source LLM architectures including latest models like DeepSeek-R1, Qwen2.5, Llama series from 1B to 405B parameters, Mistral variants, Command R, DBRX, Arctic, and Mixtral models.
- Multiple platform compatibility: Available as both web-based calculator and Mac-specific version optimized for Apple Silicon deployments, with mobile-responsive design ensuring accessibility across all devices.
- Configuration sharing capabilities: Features URL sharing functionality enabling teams to easily share and collaborate on infrastructure configurations, streamlining decision-making processes.
How It Works
SelfHostLLM simplifies complex infrastructure planning through an intuitive, scientifically-grounded approach to LLM deployment calculations. Users begin by selecting their desired LLM architecture from the comprehensive model database or inputting custom parameters for specialized configurations. The tool then processes this information using established formulas that account for model memory requirements, quantization factors, KV cache overhead, and system resources. The underlying calculation follows the principle: Available Memory = Total VRAM – System Overhead – Model Memory, with KV Cache = (Context Length × Adjusted Model Memory × KV Overhead) / 1000. This mathematical foundation ensures accurate estimations while clearly communicating assumptions about worst-case scenarios where all requests utilize full context windows, helping teams understand both optimal and realistic capacity expectations.
Use Cases
SelfHostLLM addresses critical planning scenarios across diverse AI infrastructure deployment contexts, serving teams at every scale.
- Initial infrastructure planning and hardware procurement: Essential for teams determining exact GPU specifications and memory requirements before making significant hardware investments, preventing costly miscalculations and ensuring adequate resources.
- Scaling existing deployments and capacity expansion: Provides clear guidance for organizations expanding their LLM infrastructure, helping determine additional hardware needs based on increased workload demands and performance requirements.
- Benchmarking and comparative analysis: Enables systematic evaluation of different hardware configurations and model combinations, facilitating data-driven decisions about infrastructure investments and deployment strategies.
- Educational resource for AI engineering teams: Serves as valuable learning tool helping engineers understand relationships between model parameters, hardware requirements, and performance characteristics, building institutional knowledge around LLM deployment.
- Multi-environment deployment planning: Supports planning for diverse deployment scenarios from local development setups to enterprise-scale production environments, including Apple Silicon optimization for Mac-based development workflows.
Pros \& Cons
Advantages
- Completely free and open-source under MIT License, ensuring accessibility for teams regardless of budget constraints while providing full transparency and community-driven development.
- Comprehensive model support covering latest architectures and parameter ranges, from efficient 1B parameter models suitable for edge deployment to massive 671B parameter models requiring enterprise hardware configurations.
- Scientifically grounded calculations with clearly documented assumptions, helping teams understand both theoretical capacity and real-world performance expectations while avoiding common infrastructure planning pitfalls.
- Cross-platform compatibility including specialized Mac version optimized for Apple Silicon, ensuring broad accessibility across different development environments and deployment targets.
- Active development with continuous updates reflecting latest model releases and hardware advances, providing ongoing value as the LLM landscape evolves.
Disadvantages
- Estimation-focused tool providing theoretical calculations rather than real-world performance measurements, requiring teams to validate actual performance against predicted capacity in production environments.
- Planning-phase specialization without integrated deployment automation, focusing solely on pre-deployment calculations rather than offering end-to-end infrastructure management capabilities.
- Dependency on worst-case assumptions that may overestimate resource requirements for typical workloads, potentially leading to conservative hardware specifications that exceed actual needs.
How Does It Compare?
When evaluated against the comprehensive landscape of LLM infrastructure tools and platforms, SelfHostLLM occupies a unique position by specializing in precise pre-deployment planning rather than deployment execution or runtime optimization.
Infrastructure Planning Tools in the ecosystem include several alternatives with different approaches. The LLM Memory Calculator by Alex188dot provides basic GPU memory estimation with parameter input and quantization selection, while Research AIMultiple’s VRAM Calculator offers compatibility checking for specific hardware configurations. VMware’s LLM Sizing Guide targets enterprise deployments with comprehensive memory footprint and latency calculations, and qoofyk’s LLM_Sizing_Guide provides detailed capacity planning for different GPU architectures. SelfHostLLM differentiates itself through comprehensive model database integration, user-friendly interface design, and cross-platform compatibility.
Deployment \& Runtime Solutions represent the next phase after SelfHostLLM’s planning capabilities. Ollama, with 136,000 GitHub stars, offers local LLM runtime focusing on ease of use across macOS, Linux, and Windows. LM Studio provides beginner-friendly desktop applications for model experimentation, while AnythingLLM (43,000 stars) specializes in local RAG applications with document processing. TensorRT-LLM delivers NVIDIA’s high-performance inference optimization, Text Generation Inference (TGI) provides Hugging Face’s production-ready server solution, and LMDeploy offers multi-modal deployment capabilities. SelfHostLLM complements these tools by ensuring optimal hardware provisioning before deployment.
Cloud \& Enterprise Solutions operate at different scales and service models. Modal provides serverless GPU platforms for LLM deployment, Runpod offers cloud GPU rental services, and Together AI delivers hosted inference for open-source models. BentoML focuses on production AI deployment platforms, while Ray Serve enables distributed model serving frameworks. These solutions often include built-in capacity planning, but SelfHostLLM provides independent, vendor-neutral analysis for informed decision-making.
Development Frameworks like FastAPI + vLLM combinations, Gradio for quick demos, Streamlit for interactive applications, and LangChain for LLM application development represent the application layer that ultimately runs on infrastructure planned using tools like SelfHostLLM.
Comparison with Original Mentions: While Hugging Face Inference Endpoints provides managed, subscription-based hosting services, SelfHostLLM serves teams planning self-managed deployments with free, independent analysis. vLLM, an excellent high-performance runtime focusing on throughput optimization during execution, operates after infrastructure provisioning. SelfHostLLM’s pre-deployment planning ensures teams have optimal hardware configurations before implementing runtime solutions like vLLM, creating complementary rather than competing value propositions.
SelfHostLLM uniquely fills the pre-deployment planning gap that many infrastructure solutions either don’t address or handle as secondary features within broader, often more expensive platforms.
Final Thoughts
SelfHostLLM stands as an indispensable resource for anyone embarking on self-hosted LLM deployments, successfully demystifying the complex relationship between model parameters, hardware requirements, and capacity planning. By providing scientifically grounded calculations with transparent assumptions and comprehensive model support, it empowers teams to make informed infrastructure decisions while avoiding common pitfalls that can result in either insufficient capacity or wasteful over-investment. While the tool focuses purely on the planning phase rather than deployment execution, its open-source nature under MIT License, continuous development with latest model support, and cross-platform compatibility including Apple Silicon optimization make it an essential component of any serious LLM infrastructure planning process. For organizations prioritizing cost-effective, data-driven infrastructure decisions, SelfHostLLM offers the foundation for confident deployment planning in an rapidly evolving landscape of large language model technologies and hardware capabilities.