
Table of Contents
SERA (Soft-verified Efficient Repository Agents)
SERA is a family of open coding models (8B, 14B, 32B) developed by the Allen Institute for AI (Ai2) that dramatically lowers the barrier to creating custom coding agents. By using a novel “soft-verified” training method, SERA eliminates the need for expensive reinforcement learning infrastructure, allowing state-of-the-art agents to be trained on standard hardware for a fraction of the usual cost.
Key Features
- Fully Open Release: Weights, training data, recipes, and the data generation pipeline are all open-source.
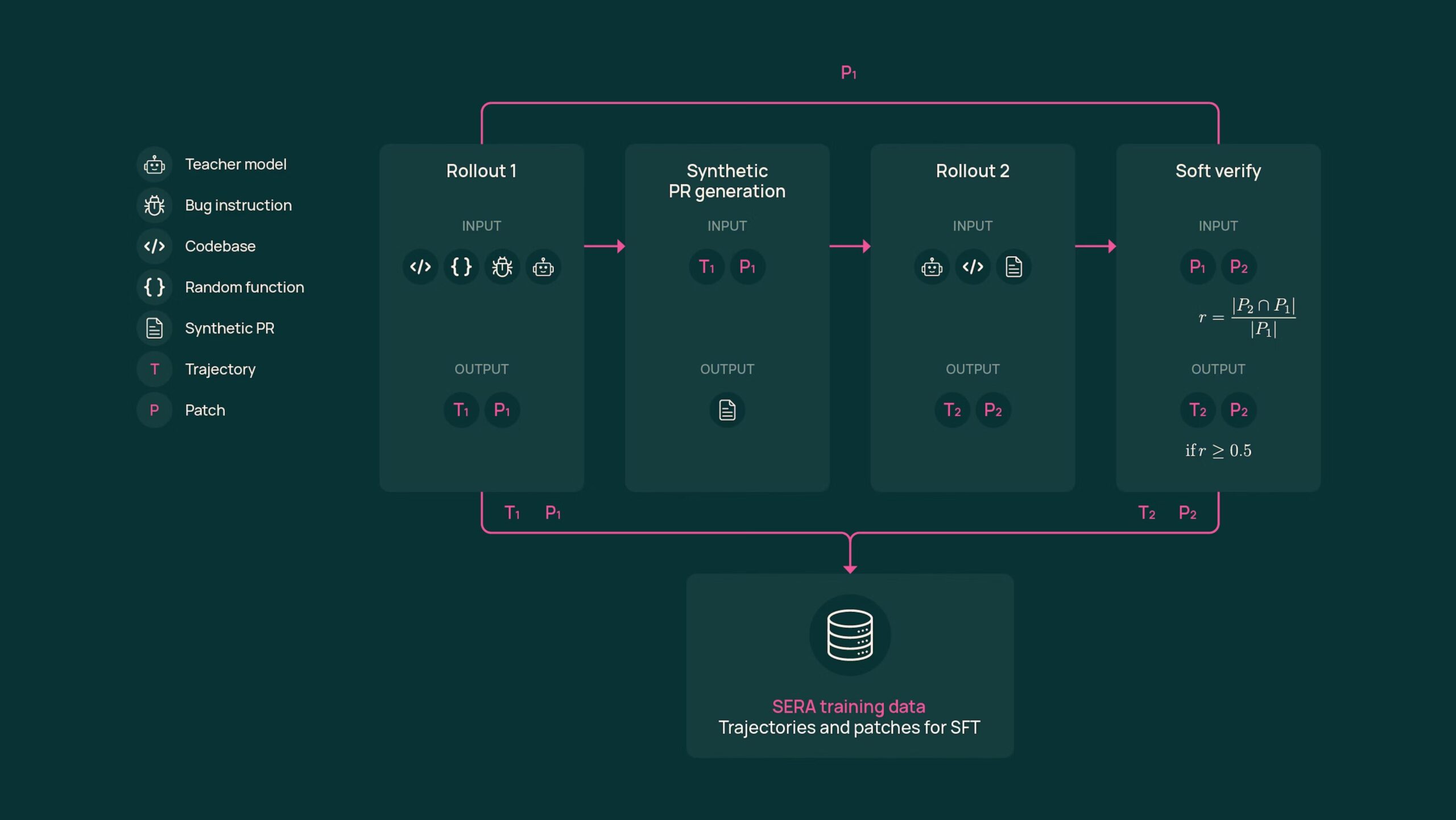
- Soft-Verified Generation (SVG): A new training method that validates synthetic data by comparing code patches rather than running expensive unit tests, reducing training costs to $400–$2,000.
- Private Codebase Adaptation: Can be fine-tuned on a specific private repository with as few as 8,000 samples, enabling highly specialized agents that outperform larger general models.
- State-of-the-Art Performance: SERA-32B achieves 54.2% on SWE-bench Verified, rivaling top proprietary models.
- Efficient Architecture: Built on Qwen 3 foundations with support for 32K/64K context windows.
- Accessible Hardware: Training and fine-tuning can be performed on accessible setups (e.g., 2–16 GPUs), democratizing agent research.
- Tool Compatibility: Designed to integrate with existing workflows, including compatibility with Claude Code.
How It Works
Developers download SERA model weights (8B, 14B, or 32B) from Hugging Face. To adapt the model to a private codebase, they use the provided Soft-Verified Generation pipeline. This pipeline generates synthetic training examples by having the model propose multiple solutions to problems derived from the codebase history. Instead of running a complex test suite (which requires massive RL infrastructure), SERA “soft-verifies” the solutions by checking if different valid reasoning paths lead to the same code patch. This validated data is then used to fine-tune the model via standard Supervised Fine-Tuning (SFT). The result is a specialized agent that understands the specific patterns, libraries, and style of that private repository, often outperforming much larger generic models.
Use Cases
- Private Codebase Agents: Startups building internal coding assistants that know their secret sauce without sharing data with OpenAI/Anthropic.
- Low-Cost Research: Academic labs experimenting with agent behaviors without million-dollar compute budgets.
- Specialized Framework Assistants: Training agents specifically for niche libraries (e.g., a “Django-Expert” or “Internal-Legacy-Framework” agent).
- Secure Coding Workflows: Deploying high-performance agents completely on-premise or within a VPC for strict data compliance.
Pros and Cons
- Pros: Fully open-source (true democratization of agent tech); Drastically lower training costs ($400 vs $10k+); High performance on benchmarks (SWE-bench Verified); No complex RL infrastructure needed (SFT only); Data privacy (models run locally/privately); Backed by the trusted Allen Institute for AI.
- Cons: Requires engineering effort to set up training and inference (not a plug-and-play API); Inference costs are your responsibility (hosting GPUs); Smaller context window than Gemini 1.5 Pro (2M); Community support is newer than Llama’s; “Soft-verification” may miss subtle runtime bugs that execution-based RL would catch.
Pricing
- Model Weights & Code: Free (Open Source / Apache 2.0 or similar open license).
- Training Costs: Estimated $400–$2,000 for compute (e.g., 40 GPU-days on H100s for full training, significantly less for fine-tuning).
- Inference: Variable based on your hosting provider (AWS, Azure, RunPod, or local hardware).
How Does It Compare?
SERA changes the economics of coding agents. Here is how it compares to the field:
- Proprietary APIs (OpenAI o1/GPT-4o, Claude 3.5 Sonnet): These are the current performance kings but are “Black Boxes.” You cannot fine-tune them deeply on your private codebase without sending data out, and you pay per token. SERA offers comparable performance (specifically SERA-32B) on coding tasks but gives you total ownership and privacy.
- GitHub Copilot / Cursor: These are polished products wrapping proprietary models. They are easy to use but rigid. SERA is a model that you build into a product. You wouldn’t “switch” from Copilot to SERA as a user; rather, your company might build its own internal Copilot using SERA to get better suggestions for your specific proprietary code.
- Open Weights Models (Llama 3, DeepSeek-Coder-V2): SERA is specialized specifically for agentic workflows (multi-step reasoning, tool use) rather than just code completion. While DeepSeek is excellent at raw code generation, SERA’s training methodology (SVG) makes it better at the “Software Engineering” loop of proposing, verifying, and fixing code in a repository context.
- Replit Agent: A closed, end-to-end product for building apps. SERA is the engine you would use to build a competitor to Replit Agent.
Final Thoughts
SERA is a milestone for the open-source AI community. Until now, “Agentic Coding”—where an AI autonomously solves a GitHub issue—was the moat of massive labs like OpenAI and Cognition (Devin). Ai2 has successfully dismantled this moat by proving you don’t need millions of dollars in Reinforcement Learning to build a top-tier agent; you just need smart data filtering. For any engineering team currently paying a fortune for generic API calls, SERA represents the future: Small, Specialized, Private Agents that know your code better than any massive generalist model ever could.