Table of Contents
Overview
Real-time access to structured search engine data has become essential infrastructure for modern AI applications, SEO tools, and data-driven SaaS platforms. Yet developers face persistent challenges: web scraping breaks frequently due to anti-bot measures, maintaining scrapers requires constant updates as search engines evolve, scaling scraping infrastructure proves expensive and unreliable, and parsing unstructured HTML into usable data consumes development resources. These barriers have created demand for reliable SERP APIs that deliver clean, structured search results without the operational overhead of scraping.
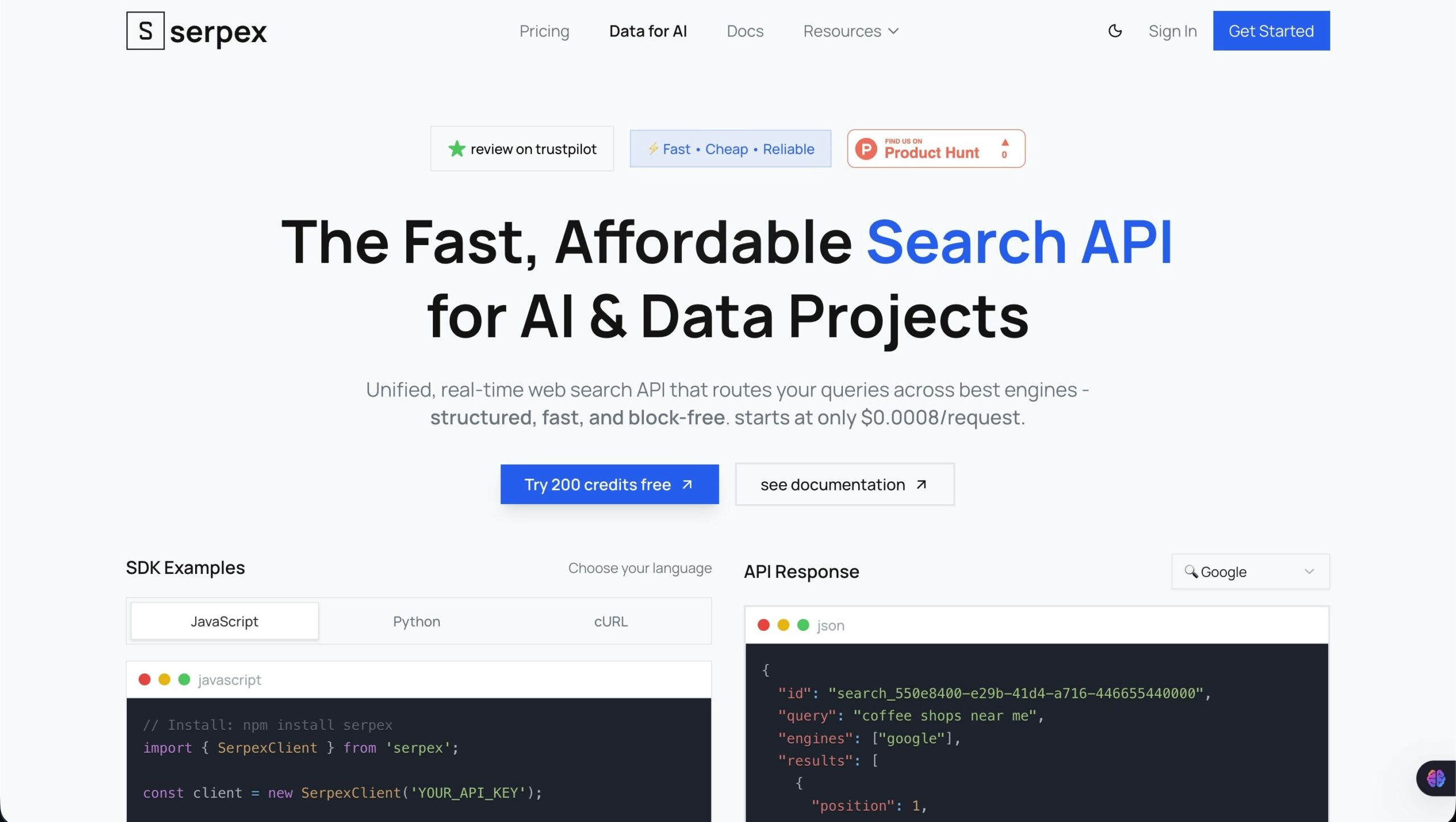
Serpex.dev addresses this need as a unified search API that routes queries across multiple search engines while handling blocking, CAPTCHAs, and data structuring automatically. Launched on Product Hunt in October 2025 where it garnered 108 upvotes, the platform positions itself as “the fast, affordable search API for AI and data projects,” emphasizing speed and cost advantages over established competitors like SerpAPI and Bright Data.
The service currently serves over 300 companies and developers worldwide, processing queries for LLM training, SEO rank tracking, market research, competitive analysis, and SaaS data enrichment. With response times averaging 0.4 seconds and pricing starting at \$0.0008 per request, Serpex targets developers seeking production-grade SERP data without the premium pricing typical of enterprise-focused alternatives.
Understanding Serpex requires recognizing what differentiates it from both web scraping and competing SERP APIs. Unlike scraping, Serpex handles infrastructure, anti-bot circumvention, and data parsing automatically through a simple REST API and SDKs for Node.js, Python, and Go. Unlike premium SERP providers charging \$2.75-\$15 per 1,000 searches with subscription requirements, Serpex offers pay-as-you-go pricing at \$0.30-\$0.80 per 1,000 requests with credits that never expire, dramatically lowering both cost and commitment barriers.
The platform’s technical architecture centers on intelligent multi-engine routing. Rather than forcing users to manually select search engines, Serpex offers an “auto” mode that routes queries to the optimal engine based on query characteristics, though the specific routing logic lacks transparency in public documentation. Users can also manually specify engines including Google, Bing, DuckDuckGo, Brave, Yahoo, and Yandex, enabling comparative analysis or engine-specific use cases.
All responses return in structured JSON format containing organic search results with position, title, URL, and snippet data, answer boxes and featured snippets when available, related search suggestions, query metadata including response time and engines used, and infoboxes with structured entity information. This clean data structure eliminates HTML parsing complexity and enables immediate integration into applications.
Key Features
Serpex delivers a focused feature set designed for developers integrating real-time search data into applications:
REST API with Multi-Language SDKs: Provides a straightforward REST API alongside official SDKs for Node.js, Python, and Go (Golang), enabling integration in minutes regardless of technology stack. The SDKs abstract API complexity into simple function calls, handling authentication, request formatting, and error management automatically. Developers can choose their preferred integration method based on existing infrastructure and programming language expertise.
Intelligent Multi-Engine Support: Routes queries across seven search engines: Google, Bing, DuckDuckGo, Brave, Yahoo, Yandex, and an “auto” mode that intelligently selects the optimal engine for each query. This multi-engine capability serves multiple purposes: comparative analysis across engines, failover redundancy if one engine blocks requests, and access to regional engines with better localized results. The auto routing feature aims to maximize result quality and reliability, though specific routing algorithms are not publicly documented.
Structured JSON Output: Delivers all search data in clean, predictable JSON format that eliminates HTML parsing complexity. The structure includes arrays of organic results with consistent fields, answer boxes and featured snippets with structured metadata, related search suggestions for query expansion, infoboxes containing entity information, and request metadata including response time and credits consumed. This standardized format enables immediate integration into data pipelines, databases, and application logic without custom parsing.
Real-Time Web Search Data: Ensures results reflect current search engine states rather than cached or stale data. Every query executes against live search engines, capturing the latest rankings, featured snippets, and organic results. This real-time capability proves essential for applications where data freshness matters: SEO rank tracking requiring current positions, AI models needing up-to-date factual information, competitive monitoring detecting immediate market changes, and trend analysis identifying emerging patterns.
Ultra-Fast Response Times: Achieves average response times of approximately 0.4 seconds per request, with 95th percentile at ~0.75 seconds and 99th percentile at ~0.9 seconds. This speed enables time-sensitive applications including conversational AI requiring sub-second responses, real-time rank tracking dashboards, high-volume batch processing completing quickly, and user-facing applications without noticeable latency. The platform maintains 99.99% uptime and supports thousands of concurrent users simultaneously.
Extremely Low Cost Per Request: Offers pricing starting at \$0.0008 per request (\$0.80 per 1,000 requests) with volume discounts that reduce costs further: \$5-\$29 spend level = \$0.80 per 1,000 requests, \$30-\$99 = \$0.65 per 1,000, \$100-\$499 = \$0.45 per 1,000, and \$500-\$2,000 = \$0.30 per 1,000. This tiered pricing structure positions Serpex as up to 10 times cheaper than competitors like SerpAPI and Bright Data, making high-volume applications economically viable.
Pay-As-You-Go with No Expiration: Operates on a credit-based system where users purchase credits that never expire, eliminating subscription pressure and unused credit waste. Credits purchase as one-time payments without recurring commitments, scale flexibly based on actual usage, never expire regardless of purchase date, and can be topped up at any time without contracts. This model suits variable-usage patterns where monthly search volumes fluctuate unpredictably.
200 Free Credits to Start: Provides 200 complimentary credits for new users to test the API before purchasing, requiring no credit card for trial access. This zero-risk trial enables developers to validate integration, test response formats, verify speed and reliability, and assess value before financial commitment. The free tier removes evaluation friction common with enterprise-focused alternatives requiring sales conversations.
Additional Query Parameters: Supports customization including time range filtering (all, day, week, month, year results), location-based targeting for localized results, device type simulation (desktop, mobile, tablet), and language specification. These parameters enable sophisticated use cases requiring specific result characteristics.
How It Works
Serpex operates through a streamlined integration workflow designed to minimize time from signup to production deployment:
Developers begin by visiting serpex.dev and signing up for an account, immediately receiving 200 free credits and an API key without requiring credit card information. This zero-friction onboarding enables instant API access for testing and validation.
Integration proceeds through either direct REST API calls or official SDKs. For Node.js users, a simple npm install serpex followed by initializing the SerpexClient with their API key provides immediate access. Python and Go developers follow similar patterns using pip or go get respectively. The SDKs abstract HTTP request complexity, handle authentication automatically, format requests correctly, and parse responses into native data structures.
A minimal integration requires just a few lines of code. Developers import the SDK, instantiate a client with their API key, and call the search method with desired parameters including query text, engine selection or “auto” for intelligent routing, optional category currently limited to “web”, and optional time range filtering. The SDK handles the rest: authenticating the request, formatting parameters correctly, executing the HTTP call, parsing the JSON response, and returning structured data ready for use.
The API returns comprehensive response objects containing a unique request ID for tracking, the original query text, engines actually used to fulfill the request, an array of search results with position, title, URL, snippet, and engine source, answer boxes and featured snippets when available, spelling corrections for typo queries, infoboxes with structured entity data, related search suggestions, and metadata including total results count, response time in milliseconds, timestamp, and credits consumed.
For production deployments, developers typically wrap Serpex calls in application logic that caches results appropriately to avoid redundant API calls for identical queries, implements error handling for network issues or rate limits, manages credit balance and triggers refills before depletion, logs API usage for cost monitoring, and formats results for specific application needs whether display, analysis, or storage.
The credit system operates transparently with each successful search request consuming one credit regardless of result quantity, engine used, or response complexity. Failed requests due to network errors or API issues do not consume credits. Users monitor credit balance through the dashboard and receive notifications approaching depletion, enabling proactive refills without service interruption.
For high-volume applications requiring thousands or millions of monthly queries, Serpex’s pay-as-you-go model with volume discounts provides predictable economics. A project executing 100,000 queries monthly would pay \$45 (\$0.45 per 1,000 at that volume tier), dramatically cheaper than competitors charging \$275-\$1,500 for equivalent usage on subscription plans.
Use Cases
Serpex enables practical applications across scenarios where real-time, structured search data proves essential:
LLM and AI Model Enhancement: Developers training or deploying large language models integrate Serpex to provide models with current factual information beyond training data cutoff dates. When an LLM needs to answer questions about recent events, current prices, latest research, or emerging topics, Serpex retrieves live search results that the model can cite and synthesize. This grounding in real-time data reduces hallucinations and improves factual accuracy for user-facing AI applications.
SEO Tool Development: SaaS platforms offering SEO services integrate Serpex to power core features including keyword rank tracking showing current positions across search engines, SERP feature monitoring detecting featured snippets, knowledge panels, and other enhancements, competitor analysis revealing rival rankings and strategies, keyword research identifying search volumes and trends, and content gap analysis discovering topics competitors rank for but the client doesn’t. The structured JSON output integrates seamlessly into dashboards and reporting tools.
Market Research and Competitive Intelligence: Analysts and researchers leverage Serpex to systematically gather search data revealing market dynamics: brand mention frequency and sentiment trends, product comparison prominence in search results, emerging competitor visibility, category leadership across different queries, and geographic market variations through localized searches. The multi-engine support enables comparative analysis across different search ecosystems.
SaaS Application Data Enrichment: Software platforms integrate Serpex to enhance their core functionality with live search intelligence. CRM systems enrich company records with current web presence data, content marketing tools identify trending topics and optimization opportunities, lead generation platforms discover prospect information from search results, and business intelligence dashboards incorporate search trend data alongside internal metrics. The API’s speed and reliability enable real-time enrichment without degrading user experience.
AI Agent Tool Integration: Conversational AI agents and autonomous systems use Serpex as a tool for real-time information retrieval. When users ask questions requiring current data—”What’s the weather in Tokyo?”, “Who won last night’s game?”, “What are Tesla’s current stock prices?”—agents invoke Serpex to gather authoritative search results, synthesize answers, and provide citations. The sub-second response times maintain conversational flow without noticeable delays.
Rank Tracking and Monitoring Automation: SEO professionals and agencies automate rank tracking workflows by scheduling regular Serpex queries for target keywords, storing results in time-series databases, detecting position changes and alerting on significant movements, generating client reports showing historical trends, and benchmarking against competitors automatically. The pay-as-you-go model with no expiration enables cost-effective tracking of hundreds or thousands of keywords without subscription pressure.
Custom Dashboard and Report Building: Agencies and consultants leverage Serpex data to build custom client dashboards displaying real-time search intelligence alongside other metrics. The structured JSON format integrates easily with data visualization tools, business intelligence platforms, and custom web applications. Users can present search data in formats tailored to client needs without being constrained by pre-built templates.
Academic Research and Analysis: Researchers studying search engine behavior, information retrieval patterns, or digital marketing trends use Serpex to systematically collect search data for analysis. The multi-engine support enables comparative studies, time range filtering facilitates temporal analysis, and the affordable pricing makes large-scale data collection feasible for academic budgets.
Pros \& Cons
Advantages
Exceptional Cost Advantage: At \$0.30-\$0.80 per 1,000 requests depending on volume, Serpex costs approximately 10 times less than premium competitors like SerpAPI (\$2.75-\$15 per 1,000) and Bright Data. This dramatic price difference makes high-volume applications economically viable that would prove prohibitively expensive on competing platforms. For projects executing millions of monthly queries, the cost savings reach tens of thousands of dollars annually.
Industry-Leading Speed: Average response times of 0.4 seconds substantially outperform competitors typically delivering results in 1-2 seconds. This speed advantage enables time-sensitive applications including conversational AI requiring sub-second responses, real-time dashboards updating frequently, high-throughput batch processing, and user-facing features without noticeable latency. The consistent performance at 95th and 99th percentiles demonstrates reliability under load.
True Pay-As-You-Go Flexibility: Unlike subscription-based competitors requiring monthly commitments regardless of actual usage, Serpex’s credit system with no expiration eliminates waste and commitment pressure. Users purchase only what they need, scale usage freely without plan changes, avoid paying for unused capacity during low-activity periods, and maintain credits indefinitely without pressure to consume before expiration. This model suits variable workloads and exploratory projects.
Straightforward Integration: The REST API and official SDKs for Node.js, Python, and Go enable integration in minutes rather than days. Developers avoid complex authentication flows, custom HTML parsing logic, anti-bot infrastructure, and scaling challenges inherent in web scraping. The structured JSON responses eliminate data cleaning and normalization, enabling immediate use in application logic.
Multi-Engine Intelligence: Support for seven search engines with automatic routing provides flexibility and reliability absent from single-engine APIs. Users can compare results across engines, implement failover redundancy, access regional engines with better localized data, and leverage intelligent routing for optimal results. This multi-engine architecture future-proofs against any single engine changing terms or blocking access.
Zero-Risk Trial with 200 Free Credits: The generous free tier requiring no credit card removes evaluation barriers. Developers can fully test integration, validate response formats, verify performance, and assess value before financial commitment. This contrasts sharply with enterprise-focused competitors requiring sales conversations and minimum commitments before access.
High Reliability and Scalability: The platform maintains 99.99% uptime and supports thousands of concurrent users simultaneously, demonstrating production-grade infrastructure. Load testing shows all requests completing successfully under high concurrency, validating reliability for demanding applications. The system handles CAPTCHA solving and anti-bot circumvention automatically without user intervention.
Disadvantages
No User Interface for Visualization: Serpex provides exclusively API access without dashboards, visualization tools, or user interfaces for exploring data. Developers must build their own UI layers for data presentation, analysis, or reporting. This pure API approach suits technical teams comfortable with data integration but may frustrate users seeking turnkey solutions with built-in visualization.
SERP Data Only, Not General Web Scraping: The platform focuses exclusively on search engine results pages rather than general web scraping or full webpage content extraction. Users needing to scrape product pages, extract structured data from arbitrary websites, or monitor non-search content must use different tools. This narrow scope ensures quality and reliability for SERP use cases but limits versatility.
Limited Engine Selection Transparency: While the “auto” routing feature promises intelligent engine selection, the specific algorithms and decision criteria lack public documentation. Developers cannot predict which engine will handle each query or understand the routing logic, potentially creating inconsistent results for certain query types. More transparency about routing behavior would enable better optimization.
Relatively New Platform: Launched recently compared to established competitors with years of operational history, Serpex represents higher early-adopter risk. The platform’s long-term viability, feature roadmap, and continued maintenance remain to be proven. Users committing to Serpex for critical infrastructure should consider contingency plans if the service evolves unexpectedly or encounters sustainability challenges.
Currently Web Search Only: The platform currently supports only “web” category searches, lacking specialized result types including image search results, video search data, news-specific results, shopping and product searches, local business listings, or academic paper searches. Users requiring these specialized result types must use category-specific APIs or scraping approaches. Serpex’s roadmap may expand categories but current focus remains general web search.
Response Variability Across Engines: Different search engines return varying result structures, quality, and completeness. While Serpex normalizes responses into consistent JSON format, the underlying data quality depends on which engine processes each query. Users may encounter inconsistencies when auto-routing switches engines for similar queries or when manually comparing results across engines.
No Advanced SERP Features in All Cases: While Serpex captures organic results, answer boxes, and suggestions reliably, some advanced SERP features may not appear consistently including knowledge panels, local packs, shopping results, image carousels, and other rich results. The extraction depends on both search engine presence and Serpex’s parsing capabilities, which may not capture every possible SERP element.
How Does It Compare?
Serpex competes in the established SERP API market alongside mature providers with different positioning, pricing, and capabilities:
SerpAPI dominates the premium segment as the most trusted and feature-rich SERP API, supporting not just Google, Bing, and other search engines but also YouTube, Amazon, Google Maps, App Store, and dozens of specialized sources. SerpAPI’s reliability and comprehensive feature set command premium pricing: plans start at \$50 monthly for 5,000 searches, scale to \$3,750 monthly for Enterprise with additional usage charges of \$2.75-\$15 per 1,000 searches depending on speed tier and commitment. The platform offers optional “Ludicrous Speed” at 2-3x additional cost for ultra-fast responses.
SerpAPI’s strength lies in breadth—supporting virtually every major search property and data source developers might need—and maturity with years of operational history demonstrating reliability. However, this breadth and reliability come at significant cost. Organizations executing hundreds of thousands or millions of monthly queries face substantial bills. Serpex positions explicitly against SerpAPI on price, claiming to be 10 times cheaper while maintaining comparable speed and reliability for core web search use cases.
Serper.dev represents Serpex’s closest price-performance competitor, marketing itself as “the world’s fastest and cheapest Google Search API” with pricing starting at \$0.30 per 1,000 queries. Serper delivers results in 1-2 seconds and focuses exclusively on Google search, sacrificing multi-engine support for simplicity and speed. At equivalent pricing to Serpex’s highest volume tier, Serper proves competitive for Google-only use cases but lacks Serpex’s multi-engine flexibility. Developers requiring Bing, DuckDuckGo, or other engine support must look elsewhere.
DataForSEO targets enterprise SEO and digital marketing agencies with comprehensive data coverage including SERP results, backlinks, keywords, on-page analysis, and content analytics. DataForSEO’s pricing and packaging focus on large-scale professional users rather than individual developers or startups. While powerful for agencies managing multiple clients and requiring diverse data types, DataForSEO’s complexity and enterprise focus make it less suitable for developers simply needing clean SERP data for AI or application integration.
Bright Data SERP API positions as the premium option emphasizing data quality, worldwide localization, JavaScript rendering, CAPTCHA solving, and unlimited concurrent requests. Pricing follows enterprise models with custom quotes and volume-based plans. Bright Data excels for organizations requiring guaranteed uptime, dedicated support, complex localization needs, and willingness to pay premium prices for reliability. However, for standard SERP use cases, Serpex’s 99.99% uptime and 0.4-second responses at 10x lower cost prove difficult to justify bypassing.
SpaceSerp differentiates through AI-powered features including intelligent result analysis, automated monitoring schedules, and transformation of raw SERP data into structured business insights. SpaceSerp targets users seeking not just data but analytical capabilities around that data. The platform’s focus on automation and intelligence suits teams wanting turnkey solutions over raw API access. Serpex appeals more to developers comfortable building their own analysis and automation layers.
WebScraping API SERP offers tiered subscriptions from \$28 monthly (10,000 requests) to \$1,600 monthly (1 million requests) with SERP parsing, bulk processing, and support for JSON, CSV, and HTML formats. While competitively priced in lower tiers, WebScraping API’s monthly commitment model contrasts with Serpex’s pay-as-you-go flexibility. Users with consistent monthly volumes may find WebScraping API suitable, but variable-usage patterns benefit from Serpex’s no-commitment model.
serpstack by apilayer provides real-time SERP data from Google, Yahoo, Bing, Baidu, and Yandex with bank-grade SSL encryption and support for mobile, tablet, and desktop devices. serpstack offers free tiers and subscription plans but lacks the modern developer experience of SDK support and intelligent routing. The platform serves users comfortable with basic REST API integration who don’t require advanced features.
Serpex distinguishes itself through a specific combination of attributes that established competitors struggle to match simultaneously:
The dramatic price advantage at \$0.30-\$0.80 per 1,000 requests versus competitors’ \$2.75-\$15 enables high-volume applications economically unfeasible on premium platforms. Speed leadership with 0.4-second average responses beats competitors typically delivering 1-2 seconds, enabling time-sensitive applications. Pay-as-you-go flexibility with no expiration eliminates subscription pressure and unused capacity waste inherent in monthly commitment models. Multi-engine support with intelligent routing provides redundancy and flexibility absent from single-engine APIs. Modern developer experience through official SDKs for Node.js, Python, and Go accelerates integration compared to basic REST-only competitors.
The platform serves developers and organizations best when they prioritize cost efficiency for high-volume usage, require sub-second response times for real-time applications, prefer pay-as-you-go flexibility over subscription commitments, need multi-engine support or intelligent routing, and want straightforward SDK integration. It’s less suitable for users requiring specialized search types beyond web (images, videos, shopping, news), needing comprehensive multi-source coverage (YouTube, Amazon, Maps, etc.) beyond search engines, wanting built-in UI/visualization without custom development, or requiring enterprise features like dedicated support, SLAs, and account management.
Final Thoughts
Serpex.dev addresses a genuine market need with pragmatic execution: delivering clean, structured SERP data at costs 10 times lower than established premium providers while maintaining competitive or superior performance. The platform’s positioning as “the fast, affordable search API” proves accurate rather than hyperbolic—0.4-second response times genuinely lead the market, and \$0.30-\$0.80 per 1,000 requests genuinely undercut competitors charging \$2.75-\$15.
This value proposition resonates particularly with three developer segments. AI and LLM developers integrating real-time search capabilities into models and applications find Serpex’s speed and structured output ideal for reducing hallucinations and grounding responses in current data. High-volume users executing hundreds of thousands or millions of monthly queries discover that Serpex’s pricing makes previously uneconomical applications viable, saving tens of thousands annually compared to premium alternatives. Startups and indie developers appreciate the pay-as-you-go model with no expiration and 200 free trial credits, enabling experimentation without financial commitment or subscription pressure.
However, realistic assessment requires acknowledging limitations and competitive context. Serpex’s recent launch means limited operational history compared to SerpAPI’s years of proven reliability. Early adopters accept higher platform risk in exchange for cost and speed advantages. The narrow focus on web SERP data excludes specialized searches (images, videos, shopping, news) and non-search scraping use cases that comprehensive platforms like SerpAPI support. Organizations requiring this breadth may find Serpex insufficient despite cost savings.
The “auto” engine routing feature, while conceptually valuable, lacks transparency about decision logic. Developers cannot predict which engine handles each query or optimize routing behavior. More documentation about routing algorithms would enable better optimization and predictability. Similarly, the absence of UI or visualization tools means teams must build their own dashboards and reporting, suitable for technical teams but potentially limiting for less technical users.
The competitive landscape presents both opportunities and threats. Serpex’s dramatic price advantage creates sustainable differentiation if maintained as the platform scales. However, competitors could respond with price cuts or introduce pay-as-you-go models that erode Serpex’s positioning. The platform’s long-term success depends on maintaining cost leadership while expanding capabilities to reduce the feature gap with comprehensive providers.
For developers evaluating SERP APIs today, the decision hinges on prioritization. Teams for whom cost represents the primary constraint and web SERP data suffices for use cases will find Serpex delivers exceptional value. Projects requiring comprehensive multi-source coverage, specialized search types, or enterprise support justify premium pricing for platforms like SerpAPI despite higher costs. Applications where sub-second response times prove critical may find Serpex’s 0.4-second performance uniquely enabling compared to slower alternatives.
The 200 free credits with no credit card requirement remove evaluation barriers, enabling developers to test integration, validate performance, and assess value before commitment. This zero-risk trial distinguishes Serpex from enterprise-focused competitors requiring sales conversations, and enables informed decisions based on actual experience rather than marketing claims.
Looking ahead, Serpex’s trajectory depends on sustaining cost advantages as the platform scales, expanding search category support beyond web to images, videos, shopping, and news, increasing transparency around auto-routing logic, maintaining performance and reliability as user base grows, and potentially introducing UI tools for less technical users. The platform’s survival and growth will validate whether the fast-and-affordable positioning proves sustainable or whether operational realities force convergence toward industry pricing norms.
For now, Serpex offers a compelling option for developers seeking production-grade SERP data without premium pricing or subscription commitments. Whether building AI applications, SEO tools, market research platforms, or data-driven SaaS products, teams should evaluate Serpex alongside alternatives based on specific requirements for coverage breadth, response speed, cost constraints, and risk tolerance. The free trial enables informed assessment, and for many use cases, Serpex’s combination of speed, affordability, and flexibility will prove optimal.