
Table of Contents
Overview
Mistral AI released Voxtral in July 2025, marking their entry into the speech recognition and understanding market. Unlike simple transcription models, Voxtral combines state-of-the-art speech recognition with deep semantic understanding capabilities. Available in two sizes – Voxtral Small (24B parameters) for production environments and Voxtral Mini (3B parameters) for edge deployment – these models can handle up to 40 minutes of audio for understanding tasks and 30 minutes for transcription. Both versions are distributed under the Apache 2.0 license and accessible via API at \$0.001 per minute.
Key Features
Voxtral delivers comprehensive speech understanding capabilities that extend far beyond traditional transcription:
- Open-source speech understanding models: Complete transparency and flexibility for developers, released under Apache 2.0 license allowing commercial use
- Available in 24B and 3B parameter sizes: Voxtral Small for production-scale applications and Voxtral Mini for local and edge deployments
- Long-form context processing: 32K token context window enables handling audio up to 40 minutes for understanding tasks and 30 minutes for transcription
- Built-in Q\&A and summarization: Direct question-answering from audio content and structured summary generation without requiring separate ASR and language model chains
- Natively multilingual: Automatic language detection with state-of-the-art performance across widely used languages including English, Spanish, French, Portuguese, Hindi, German, Dutch, and Italian
- Function-calling from voice: Direct triggering of backend functions, workflows, or API calls based on spoken user intents without intermediate text processing steps
- Retains text capabilities: Full text understanding capabilities from its Mistral Small 3.1 language model backbone
How It Works
Voxtral employs a sophisticated multimodal architecture combining a Whisper large-v3 based audio encoder with Mistral’s language model backbone. The system processes audio through three main components: an audio encoder that converts speech to embeddings, an adapter layer that downsamples audio representations for efficiency, and a language decoder that performs reasoning and text generation. Unlike traditional speech-to-text systems, Voxtral processes spoken input to extract deep semantic meaning, enabling contextual understanding, intent recognition, and direct action execution from voice commands.
Use Cases
Voxtral’s advanced capabilities enable diverse applications across industries:
- Intelligent voice assistants: Create next-generation voice interfaces that understand complex commands and context beyond simple keyword recognition
- Audio content analysis: Automatically extract insights, summaries, and key information from meetings, lectures, podcasts, and other audio content
- Enterprise voice interfaces: Develop hands-free voice-controlled business applications for improved workflow efficiency
- Semantic transcription services: Generate transcriptions enriched with semantic understanding, summaries, and actionable insights
- Multilingual customer service: Power customer service systems that understand nuanced queries across multiple languages and can initiate appropriate responses
Pros \& Cons
Advantages
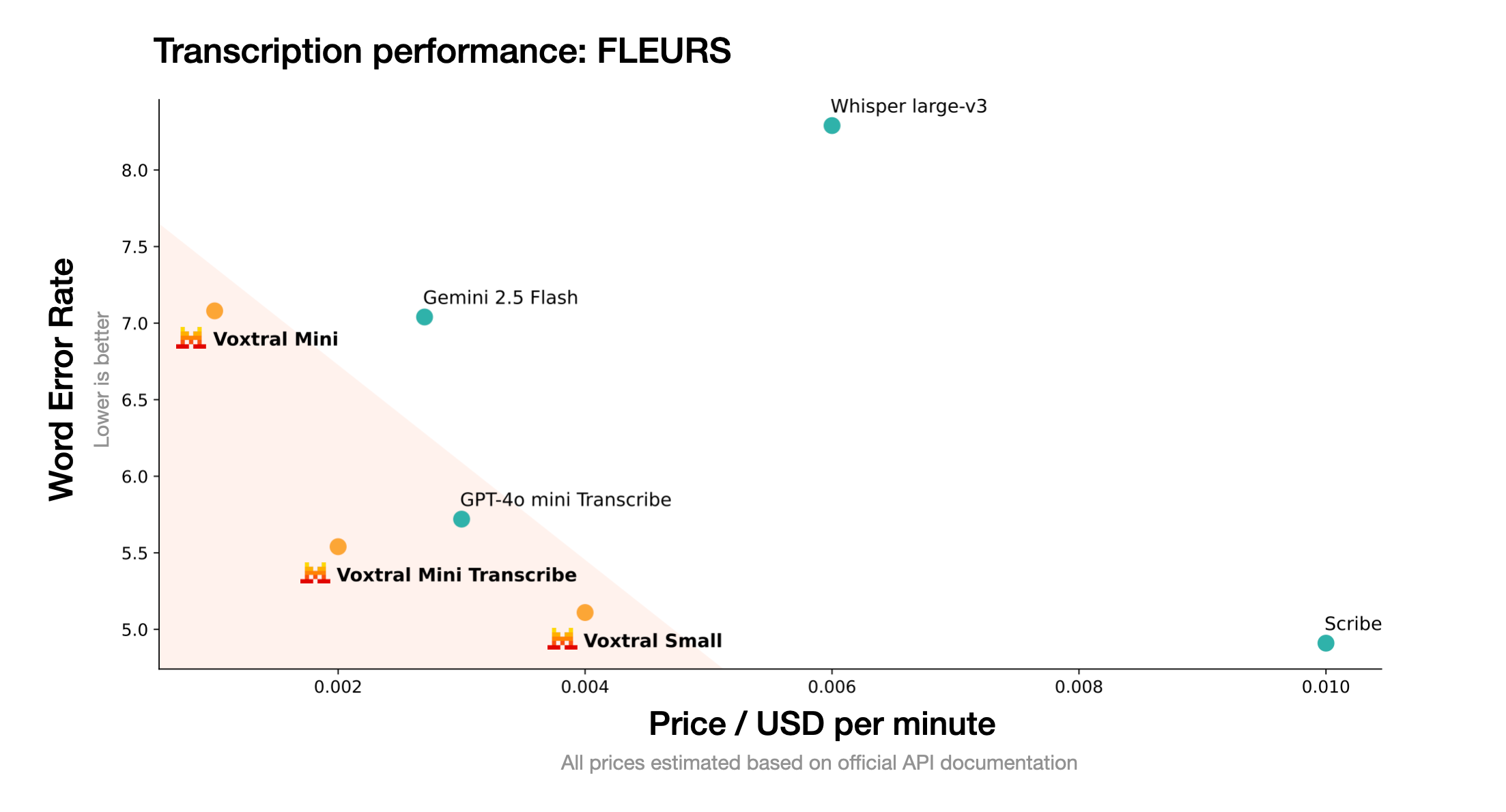
- Superior accuracy: Consistently outperforms Whisper Large-v3 and matches ElevenLabs Scribe performance at lower cost
- Comprehensive language support: Strong multilingual capabilities with automatic language detection
- Open-source flexibility: Apache 2.0 license enables customization and commercial use without proprietary restrictions
- Cost-effective: Pricing at \$0.001 per minute, significantly lower than comparable proprietary solutions
Disadvantages
- Computational requirements: The 24B parameter model requires substantial GPU resources for optimal performance
- Technical implementation: Deployment and optimization may require specialized technical expertise
- Recent release: As a newly launched model (July 2025), it has limited real-world deployment history
How Does It Compare?
Voxtral competes in an evolving speech recognition landscape with several established players:
OpenAI Whisper remains the leading open-source transcription model but focuses primarily on speech-to-text conversion with limited semantic understanding compared to Voxtral’s integrated approach. Whisper Large-v3, while highly accurate, lacks Voxtral’s function-calling capabilities and semantic processing.
ElevenLabs Scribe, launched in February 2025, offers comparable accuracy with 96.7% accuracy for English and support for 99 languages. However, Scribe is a proprietary service, while Voxtral provides open-source flexibility at roughly half the cost.
Google Speech AI and Azure Speech Services provide robust cloud-based transcription but operate as closed platforms without the customization options that Voxtral’s open-source nature enables.
Meta’s MMS (Massively Multilingual Speech) supports over 1,100 languages but is restricted to non-commercial use and lacks Voxtral’s semantic understanding and function-calling capabilities.
Voxtral’s unique position combines the accuracy of premium services like Scribe with the flexibility of open-source models like Whisper, while adding advanced semantic understanding that neither competitor offers.
Final Thoughts
Voxtral represents a significant advancement in open-source speech understanding technology. By combining transcription accuracy with semantic comprehension and function-calling capabilities, Mistral AI has created a model that bridges the gap between simple speech recognition and intelligent voice interaction. The dual-size approach accommodates both resource-constrained edge deployments and high-performance production environments. While implementation requires technical expertise and adequate computational resources, Voxtral’s Apache 2.0 licensing and competitive pricing make advanced speech intelligence accessible to a broader range of developers and organizations seeking to build sophisticated voice-enabled applications.