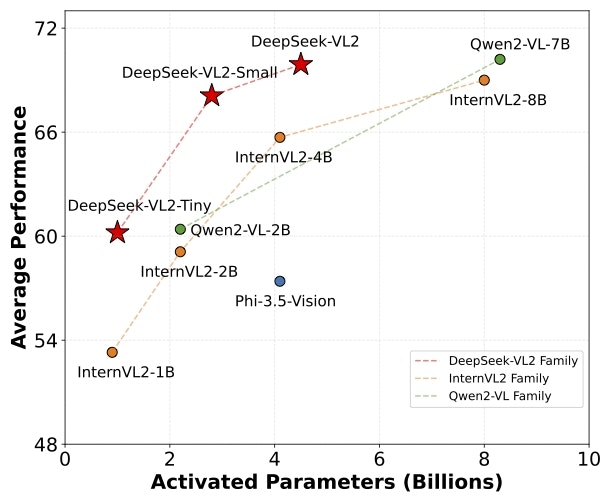

Overview
In the ever-evolving landscape of artificial intelligence, multimodal understanding is becoming increasingly crucial. Enter DeepSeek-VL2, a powerful open-source vision-language model designed to bridge the gap between visual and textual data. Built with an efficient Mixture-of-Experts (MoE) architecture, DeepSeek-VL2 promises high performance and scalability for a wide range of tasks. Let’s dive into what makes this tool a noteworthy contender in the AI arena.
Key Features
DeepSeek-VL2 boasts a robust set of features designed for advanced multimodal processing:
- Mixture-of-Experts (MoE) architecture: This innovative design allows for efficient scaling and improved performance by leveraging multiple specialized models.
- Vision-Language pretraining: The model is pretrained on vast datasets of images and text, enabling it to understand the relationships between visual and textual information.
- High scalability and efficiency: The MoE architecture ensures that DeepSeek-VL2 can handle large datasets and complex tasks without sacrificing performance.
- Open-source on GitHub: This allows for community collaboration, transparency, and customization of the model.
- Supports image and text input: DeepSeek-VL2 can process both images and text, making it versatile for a variety of applications.
How It Works
DeepSeek-VL2 leverages a sophisticated approach to process visual and textual information. It integrates a Mixture-of-Experts model with vision-language training. This allows the model to effectively process both images and text. The process involves large-scale pretraining and fine-tuning on multimodal tasks. This enhances its comprehension across different types of inputs, leading to more accurate and nuanced understanding.
Use Cases
DeepSeek-VL2’s capabilities make it suitable for a diverse range of applications:
- Visual question answering: Answer questions based on the content of an image.
- Image captioning: Generate descriptive captions for images.
- Multimodal classification: Classify data based on both visual and textual information.
- AI research: Provides a powerful tool for exploring new frontiers in multimodal AI.
- Assistive technology: Can be used to develop tools that help visually impaired individuals understand their surroundings.
Pros & Cons
Like any powerful tool, DeepSeek-VL2 has its strengths and weaknesses.
Advantages
- High performance in vision-language benchmarks.
- Efficient MoE design for scalability.
- Open access and community support.
Disadvantages
- Requires significant computational resources.
- Complex architecture may limit customization for some users.
How Does It Compare?
When compared to other vision-language models, DeepSeek-VL2 holds its own. Compared to GPT-4V, DeepSeek-VL2 offers open access and MoE efficiency. In contrast to Flamingo, DeepSeek-VL2 is more scalable and benefits from a strong community-driven development.
Final Thoughts
DeepSeek-VL2 represents a significant step forward in the field of multimodal AI. Its open-source nature, combined with its efficient architecture and strong performance, makes it a valuable tool for researchers, developers, and anyone interested in exploring the potential of vision-language models. While it requires considerable computational power, the benefits it offers in terms of scalability and community support make it a compelling option for tackling complex multimodal tasks.