Overview
EpsteinGPT is an AI-powered document search interface connecting conversational AI with publicly released legal documents related to Jeffrey Epstein cases announced December 2024 as experimental web application. Created as rapid “speedrun” development project by developer who purchased domain and built lightweight website following September-November 2024 releases of court documents and estate files, the platform enables natural language queries searching through document corpus without manually reading thousands of pages of PDFs and image files.
The project uses retrieval-augmented generation (RAG) architecture where documents were processed through OCR (optical character recognition), ingested into vector database enabling semantic search, and connected to large language model agent that retrieves relevant context and generates responses based solely on document corpus. Built using Next.js, HeroUI, and TailwindCSS deployed on Vercel with conversation history stored in Firestore and agentic state maintained in PostgreSQL database through LangGraph, the platform represents demonstration of rapid AI application development capabilities leveraging modern AI frameworks for document intelligence.
Important context: Multiple document releases occurred in 2024-2025 including January 2024 civil litigation documents (943 pages from Giuffre v. Maxwell defamation case), September 2024 House Oversight Committee release (33,295 pages), November 2024 estate document release (approximately 20,000 files), and pending December 2025 release following Epstein Files Transparency Act signed November 2025 mandating Justice Department disclosure within 30 days. Different AI search projects emerged targeting different document sets creating confusion about which files specific platforms index.
Available free without subscription reflecting experimental “meme website” positioning though serious research utility exists, EpsteinGPT targets journalists researching specific events or connections, researchers conducting open-source intelligence investigations, public seeking accessible interface exploring complex legal proceedings, and educators examining high-profile cases. The platform exemplifies growing trend of applying AI document intelligence to public legal records democratizing access to information previously requiring significant time investment and legal expertise to navigate.
Key Features
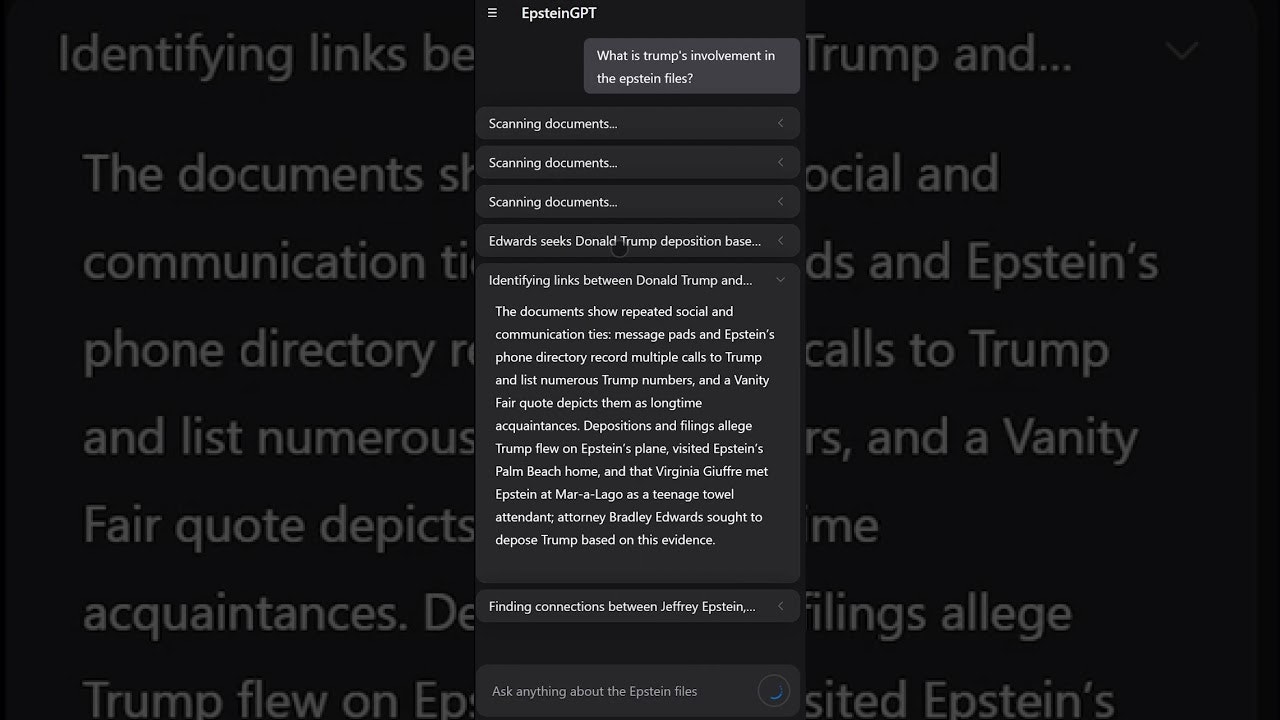
Specialized AI Agent for Document Search: Conversational interface enabling natural language queries like “What connections exist between Person X and Organization Y?” or “Summarize meetings in 2015” rather than requiring Boolean search operators or exact keyword matching. The AI agent understands context, synonyms, and relationships generating responses synthesizing information across multiple documents rather than simply returning keyword matches requiring manual synthesis.
Indexed Vector Database of Documents: Core technical infrastructure processing raw PDFs and image files through OCR extracting text, chunking documents into manageable segments, generating vector embeddings capturing semantic meaning, and storing in searchable database enabling similarity-based retrieval. This architecture allows finding conceptually related content even when exact query terms don’t appear in documents overcoming limitations of traditional keyword search.
Agentic Retrieval Augmented Generation: Advanced RAG implementation using LangGraph for agentic workflows where system doesn’t just retrieve documents but autonomously decides retrieval strategies, follows citation trails across documents, verifies information consistency, and provides sourced answers with links to original documents. The agentic approach enables multi-step reasoning and comprehensive responses versus simple single-query retrieval.
Citations and Source Links: Critical feature for research credibility where AI responses include specific citations referencing original document names, page numbers, or file identifiers enabling users verifying claims against source material. This transparency addresses common concern about LLM hallucinations by providing audit trail to primary sources.
Cross-Platform Accessibility: Web-based interface functional on desktop and mobile browsers without app installation enabling quick access from any device. The responsive design adapts to different screen sizes maintaining usability across platforms.
Conversation History and Context: Maintains conversation threads allowing follow-up questions building on previous queries with system retaining context from earlier interactions enabling more natural iterative research workflows versus starting fresh with each query.
How It Works
Users navigate to website, enter natural language questions about document corpus, then AI agent searches vector database retrieving relevant document segments, synthesizes information across multiple sources, generates coherent response with citations, and presents answer with links to original documents for verification. Follow-up questions maintain conversation context enabling deeper investigation of specific topics or connections.
The underlying architecture: documents processed through OCR converting images to searchable text, text chunked and embedded into vector representations, embeddings stored in database enabling semantic similarity search, user queries embedded into same vector space, similar document chunks retrieved based on vector proximity, LLM generates response grounded in retrieved content, and citations link back to source documents.
Use Cases
Rapid Information Discovery: Journalists or researchers quickly finding specific names, events, dates, or relationships across thousands of pages without manually reading entire corpus. The semantic search surfaces relevant passages even when exact query terms don’t appear verbatim.
Legal and Timeline Analysis: Understanding chronology of events, identifying patterns of communication, or tracking specific individuals’ appearances across multiple documents synthesizing information that would require extensive manual cross-referencing.
Open Source Intelligence Research: OSINT practitioners investigating connections, verifying claims, or building comprehensive pictures of relationships and activities documented in public legal records.
Public Transparency and Accessibility: General public gaining insight into high-profile legal cases without requiring legal expertise or time investment to navigate complex court filings enabling informed civic engagement.
Educational Analysis: Academics or students examining case studies in legal proceedings, investigating research methods for document analysis, or exploring ethical considerations in high-profile criminal investigations.
Pros \& Cons
Advantages
Democratizes Access to Complex Legal Dataset: Makes thousands of pages of court documents accessible to non-experts through conversational interface eliminating barriers of legal jargon, document organization complexity, and time investment required for manual review enabling broader public engagement with transparency.
Demonstrates Rapid AI Development Capabilities: “Speedrun” development approach showcases modern AI frameworks enabling sophisticated applications built quickly illustrating accessibility of AI tools for developers and potential for rapid public interest projects.
Provides Source Attribution and Verification: Unlike pure LLM responses that may hallucinate, grounded RAG approach with citations enables users verifying claims against primary sources maintaining research integrity and accountability.
Free and Openly Accessible: No paywalls, subscriptions, or registration requirements lower barriers to access supporting information transparency and public interest research.
Disadvantages
Sensitive and Controversial Subject Matter: Documents involve serious criminal allegations, victims of sex trafficking, and reputational implications for numerous individuals requiring careful ethical consideration about appropriate usage, potential misuse, and privacy implications despite public release status.
OCR Quality Limitations: Accuracy depends on quality of source document scans with poor image quality, handwritten notes, redactions, or formatting complexities potentially causing text extraction errors leading to incomplete search results or misinterpreted content creating misleading conclusions.
“Meme Website” Framing Undermines Serious Research: Positioning as experimental speedrun project with humorous branding potentially trivializes serious criminal justice matters and may reduce credibility for academic or journalistic research despite legitimate utility as research tool.
LLM Hallucination Risks: Despite grounding in documents, AI responses may still contain errors, misinterpretations, or inferred connections not explicitly stated in source material requiring careful verification especially for claims used in reporting or formal research.
Incomplete Document Coverage: Uncertainty about which specific document releases are indexed (January 2024 court documents, September 2024 House release, November 2024 estate files, or combinations) creates confusion about comprehensiveness and may lead users assuming more complete coverage than actually exists.
Limited Context for Complex Legal Proceedings: Documents extracted from broader legal proceedings may lack essential context about admissibility, verification status, or relevance to actual legal findings potentially leading users drawing incorrect conclusions from partial information.
No Explicit Data Governance or Privacy Policies: Unclear handling of user queries, conversation histories, or potential data retention raises privacy questions about whether sensitive research queries being logged or analyzed despite documents themselves being public.
How Does It Compare?
EpsteinGPT vs ChatPDF
ChatPDF enables conversational interaction with uploaded PDF documents supporting document summarization, question-answering, and citation extraction with subscription tiers for file size limits and usage quotas serving students, researchers, and professionals analyzing various document types.
Scope:
- EpsteinGPT: Pre-indexed specific public legal document corpus; no document upload
- ChatPDF: User uploads any PDFs; general-purpose document analysis
Document Coverage:
- EpsteinGPT: Fixed corpus of Epstein-related court and estate documents
- ChatPDF: Any documents user provides; no pre-indexed collections
Specialization:
- EpsteinGPT: Purpose-built for specific legal case investigation
- ChatPDF: General document analysis across all subject matters
Pricing:
- EpsteinGPT: Free
- ChatPDF: Free tier with paid plans for larger documents and higher usage
When to Choose EpsteinGPT: For researching specific Epstein case documents without needing separate document acquisition or upload.
When to Choose ChatPDF: For analyzing any PDF documents across different subjects with upload flexibility and broader application scope.
EpsteinGPT vs Humata AI
Humata AI provides AI-powered document analysis with focus on research papers, legal documents, and technical reports offering summarization, Q\&A, citation extraction, and comparison across multiple documents with team collaboration features and enterprise deployment options.
Document Type:
- EpsteinGPT: Specific public legal corpus pre-indexed and searchable
- Humata AI: User-provided documents across research and professional domains
Features:
- EpsteinGPT: Conversational search of fixed dataset with case-specific optimization
- Humata AI: Multi-document comparison, citation management, team collaboration
Target Users:
- EpsteinGPT: Public, journalists, researchers investigating specific legal case
- Humata AI: Researchers, legal professionals, teams analyzing various document types
Pricing:
- EpsteinGPT: Free experimental project
- Humata AI: Subscription-based with enterprise plans
When to Choose EpsteinGPT: For specific Epstein case research with pre-indexed documents and no upload requirements.
When to Choose Humata AI: For professional document analysis workflows requiring team collaboration, diverse document types, or enterprise features.
EpsteinGPT vs Distributed Denial of Secrets (DDoSecrets) Platforms
DDoSecrets is transparency collective hosting leaked and FOIA-obtained datasets with searchable interfaces for various public interest document collections including government files, corporate leaks, and legal proceedings focusing on press freedom and transparency.
Organization Type:
- EpsteinGPT: Individual developer project; single-case focus
- DDoSecrets: Transparency organization; multiple datasets across various cases
Dataset Breadth:
- EpsteinGPT: Epstein-related documents only
- DDoSecrets: Diverse datasets including government, corporate, law enforcement files
Search Technology:
- EpsteinGPT: AI-powered conversational semantic search with LLM responses
- DDoSecrets: Traditional keyword search and dataset browsing
Mission:
- EpsteinGPT: Experimental AI application demonstration with transparency benefit
- DDoSecrets: Institutional transparency advocacy and press freedom support
When to Choose EpsteinGPT: For conversational AI-assisted research specifically on Epstein documents with natural language interface.
When to Choose DDoSecrets: For broader transparency research across multiple datasets, traditional document search, or supporting institutional transparency efforts.
EpsteinGPT vs LocalGPT (Private Document Search)
LocalGPT enables private document search using open-source LLMs running entirely locally without cloud services for sensitive document analysis maintaining complete data privacy suitable for confidential business, legal, or personal documents.
Data Privacy:
- EpsteinGPT: Cloud-based service; queries processed online (privacy policy unclear)
- LocalGPT: Fully local processing; no data leaves user’s machine
Setup:
- EpsteinGPT: Web application; immediate access without installation
- LocalGPT: Requires local setup, model downloads, technical configuration
Document Source:
- EpsteinGPT: Pre-indexed public legal documents; no upload capability
- LocalGPT: User provides any documents; complete control over corpus
Technical Expertise:
- EpsteinGPT: No technical knowledge required; web browser access
- LocalGPT: Requires technical setup, understanding of LLM deployment
When to Choose EpsteinGPT: For researching public Epstein documents with simple web access and no setup requirements.
When to Choose LocalGPT: For private sensitive document analysis requiring complete data sovereignty and no cloud processing.
EpsteinGPT vs Epstein Archive (GitHub Project)
Epstein Archive is open-source searchable database created by Reddit data hoarder processing House Oversight Committee October 2024 release using AI for OCR transcription, entity extraction, document reconstruction, and web interface with code released on GitHub and mirrored as torrent for permanent availability.
Development Model:
- EpsteinGPT: Single developer web application; closed implementation
- Epstein Archive: Open-source GitHub project; community verifiable and extendable
Document Set:
- EpsteinGPT: Unclear which releases included (multiple document drops 2024-2025)
- Epstein Archive: Explicitly House Oversight Committee October release (33,295 pages)
Search Type:
- EpsteinGPT: Conversational AI with synthesis and summarization
- Epstein Archive: Entity-based search (people, orgs, locations, dates) with document linking
Availability:
- EpsteinGPT: Web application dependent on hosting and domain
- Epstein Archive: Torrent distribution ensuring permanence; downloadable database
Transparency:
- EpsteinGPT: Proprietary implementation; methodology not publicly detailed
- Epstein Archive: Fully open-source code; reproducible processing pipeline
When to Choose EpsteinGPT: For conversational natural language research interface with AI-generated summaries and responses.
When to Choose Epstein Archive: For transparent open-source research, offline access, entity-focused search, or technical users wanting to verify processing methodology.
Final Thoughts
EpsteinGPT represents growing application category of AI-powered document intelligence applied to public legal records demonstrating technical feasibility of rapidly deploying sophisticated search interfaces over complex document corpora. The platform showcases modern RAG architectures enabling natural language interaction with specialized document collections potentially democratizing access to legal information traditionally requiring significant expertise, time, and resources to navigate effectively. As demonstration of AI development velocity and accessibility, the project illustrates how individual developers leverage contemporary frameworks (LangGraph, vector databases, LLMs) building functional applications serving public interest within tight timeframes.
However, the platform involves several important considerations: the subject matter involves serious criminal allegations with victims and reputational implications requiring thoughtful ethical engagement rather than casual exploration; OCR quality limitations and potential LLM hallucinations necessitate verification against source documents for any serious research or reporting; unclear documentation about which specific document releases are indexed creates ambiguity about comprehensiveness; and “meme website” framing potentially undermines legitimate research utility while trivializing serious criminal justice matters deserving appropriate gravitas.
For journalists researching specific connections or timelines, researchers conducting open-source intelligence investigations, or public seeking understanding of high-profile legal cases, EpsteinGPT provides convenient accessible interface reducing barriers to document exploration. The conversational search capability and citation provision enable investigative workflows impossible with manual document review given scale of document releases.
For users requiring transparent verifiable methodology, the open-source Epstein Archive GitHub project provides code inspection and reproducible processing. For general document analysis capabilities, ChatPDF and Humata AI offer broader applicability across diverse document types. For privacy-critical sensitive document analysis, LocalGPT enables complete local processing without cloud dependencies. For institutional transparency research beyond single case, DDoSecrets provides diverse dataset access with traditional search capabilities.
Critical considerations: This tool involves sensitive subject matter related to criminal cases and should be used responsibly recognizing documents contain information about victims, unproven allegations, and individuals mentioned without proven wrongdoing. AI-generated responses require verification against source documents before citing in research, journalism, or public discourse. The ethical implications of packaging serious legal proceedings as “speedrun meme website” deserve reflection about appropriate framing for content involving trafficking victims and criminal investigations.
For those engaging with these documents for legitimate research, journalistic investigation, or informed civic participation, EpsteinGPT demonstrates how AI can accelerate information discovery in public legal records while emphasizing ongoing necessity of source verification, ethical consideration, and recognition that convenience of AI interfaces should not replace careful primary source analysis when accuracy and fairness remain paramount.