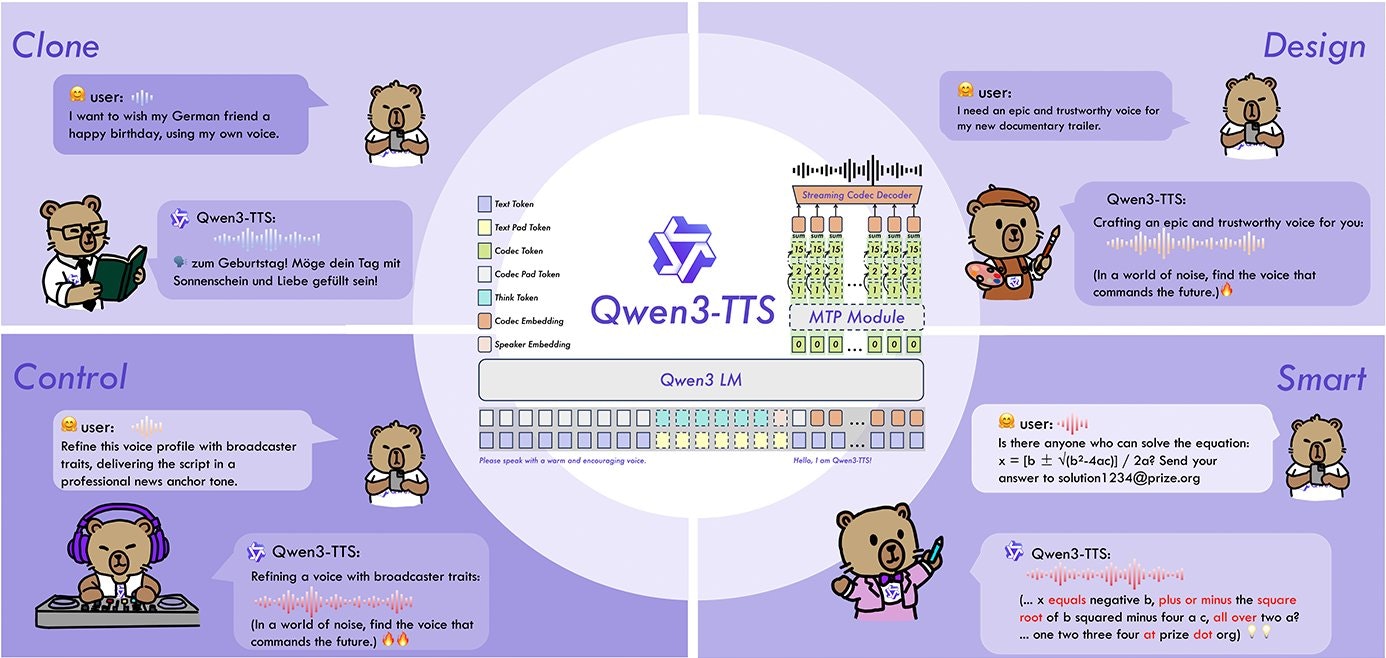

Qwen3-TTS
Qwen3-TTS is a family of state-of-the-art (SOTA) speech synthesis models (0.6B & 1.7B parameters) developed by Alibaba Cloud. Released in January 2026, it supports 10 languages and introduces a novel “Dual-Track” architecture for extreme low-latency streaming.
Key Features
- Multilingual Support: Native support for 10 major languages including English, Chinese, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian.
- Voice Design: Create custom voices from text prompts (e.g., “an elderly British man with a raspy voice”) without needing audio samples.
- 3s Zero-Shot Cloning: accurately replicates speaker timbre and prosody using just a 3-second reference audio clip.
- Dual-Track Architecture: Innovative hybrid streaming architecture that achieves <100ms (approx. 97ms) first-packet latency.
- Instruction Control: Fine-grained control over emotion, speaking rate, and pitch via natural language instructions.
How It Works
Users provide input text and either a prompt description or a short (3s+) reference audio. The model utilizes a Dual-Track language model architecture combined with a 12Hz streaming tokenizer. This design allows the system to generate the first audio packet immediately after processing the first text token, bypassing the lag typical of traditional cascade architectures while maintaining high-fidelity output.
Use Cases
- Real-time Conversational AI: Powering voice agents that require human-like response times (<100ms).
- Video Dubbing: Automatically generating localized voiceovers in 10 languages while preserving original speaker characteristics.
- Interactive Gaming NPCs: Creating dynamic, instruction-driven character voices on the fly.
- Personalized Content: Reading articles or e-books in a user’s specific cloned voice.
Pros and Cons
- Pros: SOTA voice quality comparable to proprietary models; open weights (Apache 2.0) allow for self-hosting; extreme low latency beats most commercial APIs; efficient 0.6B model runs on consumer hardware.
- Cons: 1.7B model requires significant VRAM for local inference; commercial API usage through Alibaba Cloud incurs costs; zero-shot cloning on the smaller model can be sensitive to background noise.
Pricing
- Open Source: Free to use and modify (Apache 2.0 license).
- Commercial API: Paid inference available via Alibaba Cloud DashScope (pricing varies by usage volume).
How Does It Compare?
- ElevenLabs: The industry standard for quality. While ElevenLabs still holds a slight edge in emotional nuance and consistency, Qwen3-TTS matches its cloning fidelity while offering significantly lower latency (97ms vs ~200ms) and the option to run locally for free.
- OpenAI TTS: OpenAI’s HD model provides smooth, high-quality speech but lacks the zero-shot custom voice cloning capabilities of Qwen3. Qwen3-TTS also outperforms OpenAI’s standard model in streaming speed (~150ms latency for OpenAI).
- Fish Speech: A strong open-source competitor in 2026. Fish Speech is also highly capable at cloning, but Qwen3-TTS generally offers better cross-lingual performance and more stable instruction adherence due to its larger training data (5M+ hours).
- F5-TTS / E2-TTS: These non-autoregressive models are excellent for speed but often struggle with the complex prosody control and “Voice Design” prompt capabilities that Qwen3’s Dual-Track architecture handles effectively.
Final Thoughts
Qwen3-TTS represents a significant shift in the text-to-speech landscape by bringing “proprietary-grade” features—like prompt-based voice design and sub-100ms latency—to the open-source community. Its Dual-Track architecture solves the critical trade-off between streaming speed and audio quality, making it arguably the best choice for developers building real-time voice agents in 2026 who want to avoid vendor lock-in. While it requires decent hardware to run the 1.7B model locally, the ability to fine-tune and control the model offers flexibility that API-only services cannot match.