
Overview
In the rapidly evolving landscape of artificial intelligence, open-source models are democratizing access to cutting-edge technology. Today, we explore Qwen3-235B-A22B-Thinking-2507, a formidable open-source Mixture-of-Experts (MoE) model that has made significant waves for its exceptional deep reasoning capabilities. With a focus on agentic tasks and an impressive 262K context window, this model is designed to push the boundaries of what’s possible, offering state-of-the-art performance among open-source thinking models and broad accessibility via Hugging Face and API.
Key Features
Qwen3-235B-A22B-Thinking-2507 is packed with features that set it apart, making it a powerful tool for developers and researchers alike.
- Mixture-of-Experts (MoE) Architecture: Leverages a sparse activation mechanism with 128 total experts and 8 activated experts per token for enhanced efficiency and performance.
- 22B Active Parameters: While boasting a massive total parameter count of 235B, only 22 billion parameters are actively engaged per token, optimizing computational resources.
- 235B Total Parameters: A testament to its vast knowledge base and potential for complex understanding.
- 262K Context Length Support: Natively supports 262,144 tokens, enabling the model to maintain coherence and process information across incredibly long documents or extended dialogues.
- SOTA Results in Open-Source Reasoning: Achieves state-of-the-art performance among open-source thinking models, particularly excelling in intricate agentic assignments and complex reasoning tasks.
- Open-Source and API Accessible: Provides flexibility for developers to integrate, experiment, and build upon its capabilities under Apache 2.0 license.
- Optimized for Thinking Mode Only: Specifically engineered to handle multi-step, autonomous reasoning tasks with high precision in thinking mode exclusively.
How It Works
Understanding the mechanics behind Qwen3-235B-A22B-Thinking-2507 reveals its innovative approach to AI efficiency and performance. This model employs a sparse Mixture-of-Experts (MoE) architecture with 94 layers and Grouped Query Attention (GQA) featuring 64 query heads and 4 key-value heads. Out of its grand total of 235 billion parameters, only a select subset of 22 billion active parameters are engaged for processing each token through selective expert routing. This intelligent design significantly boosts efficiency by avoiding the need to activate the entire model for every computation, all while retaining high performance.
Furthermore, Qwen3-235B-A22B-Thinking-2507 is meticulously optimized for long-context understanding and complex, multi-step reasoning. It achieves this by utilizing an expansive 262K context length, allowing it to maintain coherence and draw insights from extensive dialogues or lengthy documents. The model operates exclusively in thinking mode, automatically including reasoning chains in its outputs, making it ideal for tasks requiring deep contextual awareness and transparent reasoning processes.
Use Cases
The advanced capabilities of Qwen3-235B-A22B-Thinking-2507 open up a wide array of practical applications across various domains.
- Advanced Reasoning Research: Ideal for developing and testing autonomous AI systems that can perform complex, multi-step operations requiring extended reasoning chains.
- Long-Context Document Analysis: Capable of analyzing extremely lengthy documents, reports, or books while retaining key information and coherence across the full 262K token context.
- Autonomous Task Execution: Powers systems that can independently plan and execute complex tasks based on high-level instructions with visible reasoning processes.
- Knowledge Synthesis Systems: Enhances the accuracy and depth of information synthesis by understanding and processing vast knowledge bases with transparent reasoning.
- Academic and Scientific Research: Assists researchers by comprehending and extracting insights from dense, technical literature while showing its reasoning process.
- Complex Code Generation: Generates more accurate and contextually relevant code by utilizing extensive context memory and transparent problem-solving approaches.
Pros \& Cons
Like any powerful tool, Qwen3-235B-A22B-Thinking-2507 comes with its own set of advantages and considerations.
Advantages
- High Efficiency via Sparse Activation: Its MoE architecture ensures that only 8 out of 128 experts are active per token, leading to more efficient computation compared to dense models of similar capability.
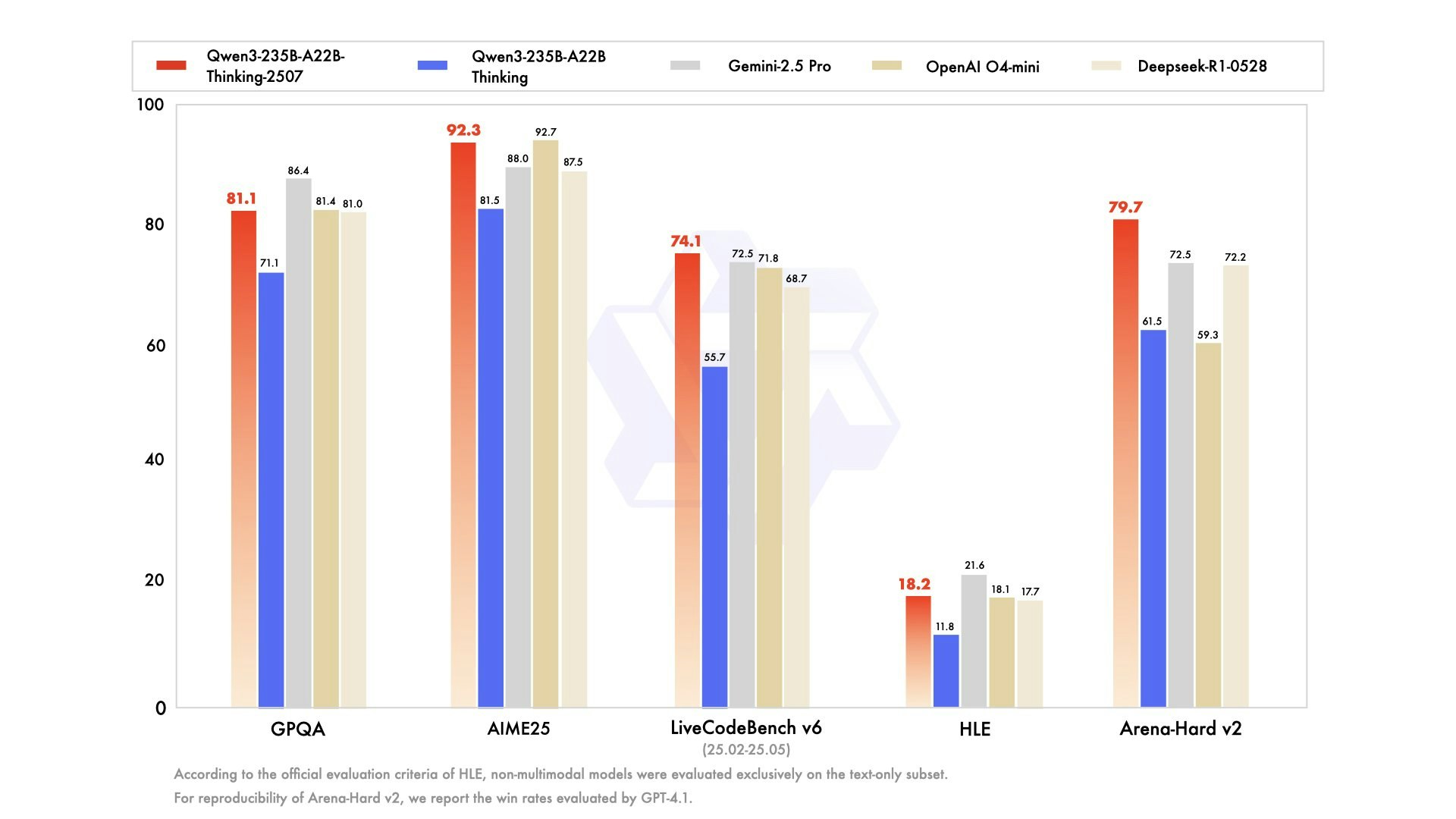
- Excellent at Complex Reasoning: Demonstrates superior performance in tasks requiring deep logical inference and problem-solving, achieving competitive results on benchmarks like AIME25 (92.3%) and LiveCodeBench (74.1%).
- Extensive Context Support: The 262K context window allows for unparalleled understanding of long and intricate inputs, enabling comprehensive document analysis and extended conversations.
- Open Access for Developers: Being open-source under Apache 2.0 license, it fosters innovation and allows for broad community contributions, customization, and deployment flexibility.
- Transparent Reasoning: The thinking-mode-only design provides visible reasoning processes, making it valuable for applications requiring explainable AI.
Disadvantages
- Resource-Intensive to Deploy: Despite efficiency optimizations, deploying the full model requires significant computational resources, typically needing multiple high-end GPUs for optimal performance.
- Thinking Mode Only: The model operates exclusively in thinking mode, which may result in longer response times and higher token usage compared to non-thinking variants.
- Still in Active Development: As a recently released model (July 2025), users might encounter ongoing updates and potential changes as the model ecosystem matures.
- Specialized Use Case: The thinking-mode focus makes it less suitable for simple, quick-response applications where reasoning transparency is not required.
How Does It Compare?
When placed alongside other leading AI models in 2025, Qwen3-235B-A22B-Thinking-2507 establishes its position as a top open-source reasoning model. Compared to DeepSeek R1, Qwen3 demonstrates competitive performance across reasoning benchmarks, with notable advantages in certain areas like AIME25 (92.3% vs 87.5%) and LiveCodeBench (74.1% vs 68.7%), while maintaining full open-source accessibility.
Against OpenAI’s o3 and o4-mini models, Qwen3 offers comparable reasoning capabilities with the significant advantage of complete transparency and control. While o3 and o4-mini may excel in some specific benchmarks, Qwen3 provides the freedom of open-source deployment and customization that proprietary models cannot match.
Compared to Claude 4 Opus, Qwen3 holds its ground in reasoning tasks while offering the crucial advantage of open weights and Apache 2.0 licensing. Claude 4 Opus excels in coding tasks and maintains strong performance, but remains proprietary and accessible only through Anthropic’s controlled API.
When evaluated against Gemini 2.5 Pro, both models offer extensive context capabilities, with Gemini supporting up to 1 million tokens compared to Qwen3’s 262K. However, Qwen3 distinguishes itself through its specialized thinking mode design and complete open-source nature, providing developers with unprecedented control and transparency.
In the broader landscape of open-source alternatives, Qwen3-235B-A22B-Thinking-2507 stands out among models like Llama, Mixtral, and other community-driven projects by offering specialized reasoning capabilities that rival proprietary systems while maintaining the accessibility and transparency that the open-source community values.
Final Thoughts
Qwen3-235B-A22B-Thinking-2507 represents a significant milestone in open-source AI development, offering a robust solution for deep reasoning and complex analytical tasks through its innovative MoE architecture and extensive 262K context window. Released in July 2025, this model demonstrates that the open-source community can achieve reasoning capabilities that compete directly with proprietary giants like OpenAI’s o3 series, DeepSeek R1, and other leading models.
While it demands substantial computational resources and operates exclusively in thinking mode, its open accessibility under Apache 2.0 license and state-of-the-art performance among open-source thinking models make it an invaluable asset for researchers, developers, and organizations seeking transparent, controllable AI capabilities. The model’s ability to provide visible reasoning processes while maintaining competitive performance positions it uniquely in the current AI landscape.
As the field continues to evolve rapidly with new releases from major players like OpenAI, Anthropic, Google, and others, Qwen3-235B-A22B-Thinking-2507 stands as a testament to the power and potential of open-source AI development, offering both performance and the freedom to innovate that proprietary solutions cannot provide.